SimCLR
: A Simple Framework for Contrastive Learning of Visual Representations
- 2020년도 발표된 논문
이전의 일반적인 접근방법
- Generative
: input에서 모델 pixel들을 만드는 방법이다. pixel-level generation은 비싸고 representation learning에 필수적이지 않다. - Discriminative
: supervised learning과 비슷한 objective function을 사용해 representation을 만든다. 이 방법의 문제점은 input과 라벨들이 라벨링되지 않은 데이터셋에서 pretext task를 수행해야하는 것이다. 이런 작업들은 heuristic(인간의 판단이 포함된)하다고 보기 때문에 일반화에 문제가 있다.
SimCLR의 주요 구성
- 간단하게 설계됨, 간단한 프레임워크
- 데이터 증강(Multiple Data Augmentation Operations)
- learnable nonlinear transformation
- Representation learning with contrasive cross entropy
- 큰 배치사이즈와 긴 trainig을 시키고 신경망을 더 깊고 넓게 쌓을수록 성능이 높아진다는 장점이 있다.
Method
The Contrastive Learning Framework
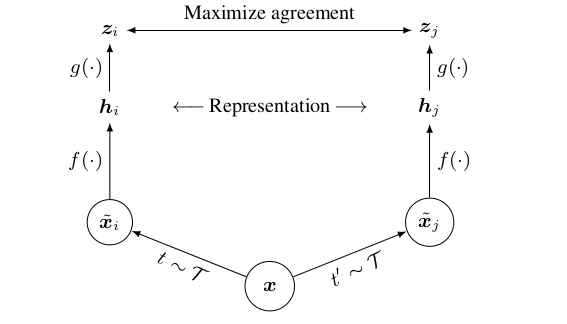
: x라는 positive 이미지를 데이터 증강을 통해 xi와 xj라는 Encoder를 만든다. 이 두 이미지를 f함수를 통해 representation h를 만들고 g함수를 통해 z를 만든다. zi와 zj를 비교해 나온 값을 x encoder에 매번 업데이트시켜 가중치를 학습시킨다.
Projection head를 통해 positive sample은 embedding space와 가깝게하고, negative sample은 거리를 멀게하는 방식을 사용한다.
linear evaluation은 representation h 위에서 사용한다.
Loss function for a positive pair of examples (i,j)

NT-Xent(the normalized temperature-scaled cross entropy loss)

Training with Large Batch Size
training batch size N은 256부터 8192까지 다양하다. 8192개의 batch size는 positive pair당 증강 이미지로부터 16382개의 negative example들을 만든다. 이렇게 큰 사이즈를 학습시키는 것은 linear learning rate scaling과 함께 SGD/Momentum을 사용해서 unstable할 수도 있다. 그래서 모든 batch size들에 대해서 LARS optimizer를 사용한다. batch size마다 32개에서 128개의 core를 사용하는 Cloud TPUs로 모델을 학습시켰다.
Global BN
Contrastive learning에서 positive pair들이 같은 기기에서 계산될 때, 그 모델은 representation을 향상시키는 것 없이 예측 정확도를 향상시키는데는 정보결함이 생긴다. 그래서 이 문제를 해결하기 위해 BN 평균과 분산을 사용한다.
Evaluation Protocol
: ImageNet ILSVRC-2012 데이터셋을 사용했고 CIFAR-10을 Pre-train용으로 사용했다. pretrained 결과들을 평가하기 위해서 transfer leaning의 데이터셋들을 사용했다. 그 결과 semi-supervised와 transfer learning에 대해서도 가장 높은 성능을 도달했다.
- 기본세팅
Data Augmentation(Crop & Resize with random flip, color distortion, Gaussian blur) - ResNet-50 - 128 dimensional latent space에서 representation을 project - 2layer MLP projection - loss로는 NT-Xent사용하고 learning rate 4.8(=0.3 x BatchSize/256), weight decay of 10−6
- batch size 4096 for 100 epochs
- linear warmup for the first 10 epochs, and decay the learning rate with the cosine decay schedule without restarts
Data Augmentation for Contrastive Representation Learning
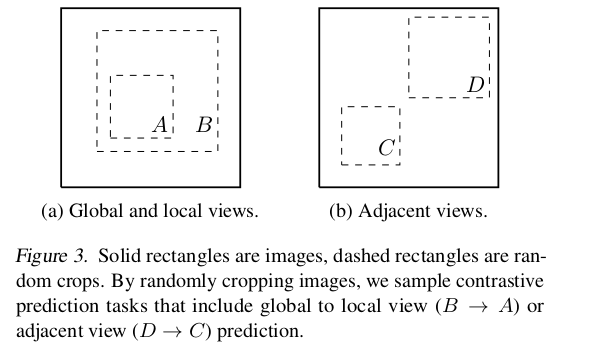
이미지를 자르면(crop) B는 A와 같은 클래스의 이미지고 D는 C와 같은 클래스의 이미지라고 판단하도록 한다. target 이미지를 랜덤하게 자르면 복잡성이 해결된다.

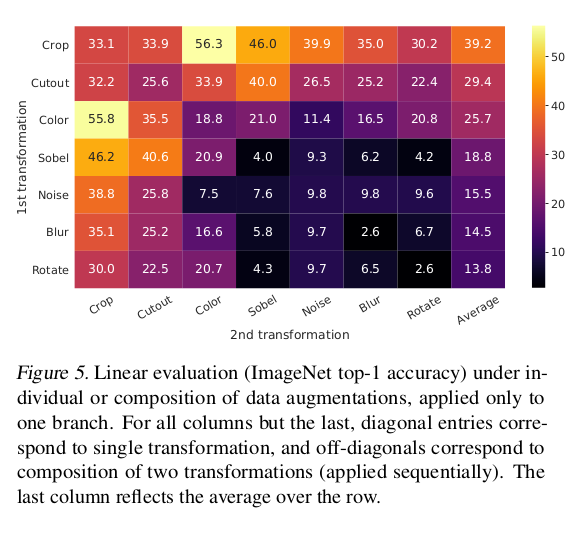
각 augmentation 기법들을 적용했을 때 언제 가장 높은 성능을 보이는지 실험했다. 결과적으로, Crop과 Color를 적용했을 때 가장 높은 성능을 보였다.
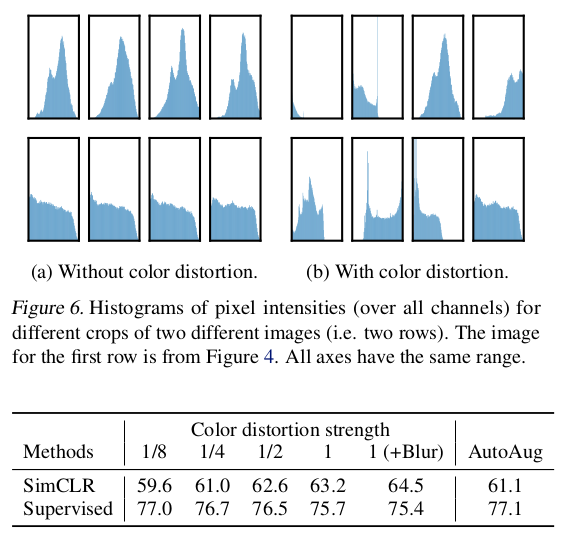
color augmentation은 learned unsupervised models의 평가를 향상시켰다. AutoAugment는 simple cropping + color distortion보다 낮은 성능을 보인 것을 알 수 있다. 하지만, supervised 모델은 color augmentation을 사용해도 성능이 오르지 않았다. 이것은 unsupervised constrastive learning이 data augmentation한 경우 효과적인 것을 알 수 있다.
Architectures for Encoder and Head
Unsupervised contrastive learning benefits (more) from bigger models
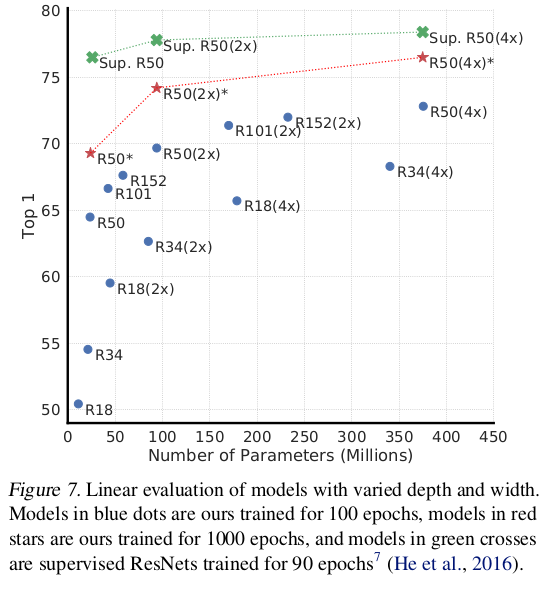
unsupervised learning benefits more from bigger models than its supervised counterpart.
Supervised Learning은 층이 깊어져도 학습이 제대로 되지 않는다. Unsupervised learning은 supervised learning보다 모델이 커질수록 성능이 향상하는 것을 볼 수 있다.
A nonlinear projection head improves the representation quality of the layer before it
Projection head가 사용될 때, 출력 크기와 관계없이 비슷한 결과를 보였다. 게다가, nonlinear projection이 사용될 때, projection head 이전 층인 h는 z = g(h)보다 10% 더 성능이 좋았다.
그 이유는 논문 저자가 추측하길, nonlinear projection이전에 사용은 contrastive loss로 유입된 정보손실 때문이다. g(h)는 projection head를 거치면 loss를 줄이는 방향으로 학습한다. z = g(h)가 데이터 변형에 변함이 없게 학습되었다. 그래서, g는 물체의 방향이나 색깔과 같은 아래 작업들에서 유용한 정보를 제거하는 것이다.
g(.)를 사용하는 것은 많은 정보가 h에 만들어지고 유지될 수 있다.
즉, h는 적용된 데이터 변형에 대한 더 많은 정보를 포함하지만 g(h)는 정보를 잃는다.

Loss Functions and Batch Size
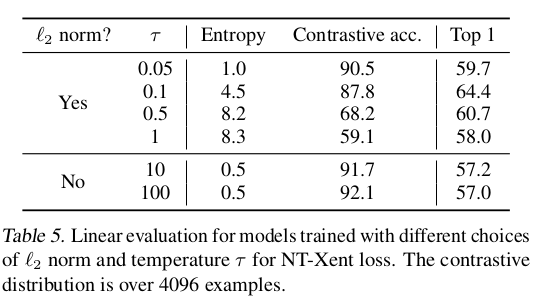
Normalized cross entropy loss with adjustable temperature works better than alternatives
- NT-Xent loss
1) l2 normalization(cosine similarity) along with temperature
: 데이터셋에서 원 형태로 이미지 클래스들을 분류할 때, cosine similarity가 작을수록 이미지간의 유사성이 높다고 볼 수 있다. temperature는 다른 예시들을 구분할 때 가중치로 사용되어, 가중치가 커질수록 positive와 negative를 더 잘 비교할 수 있도록 한다.
2) Cross entropy와 달리, 다른 objection functions는 상대적인 hardness에 의해 negative들에 가중치를 곱하지 않는다.

NT-Xent가 가장 높은 성능을 보인다.
Contrastive learning benefits (more) from larger batch sizes and longer training
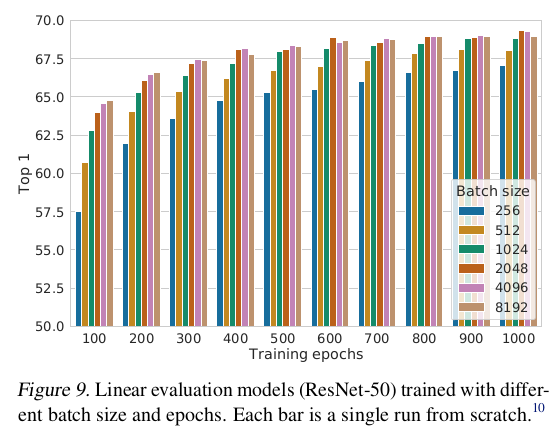
epoch가 작을 때 larger batch size가 작은 batch size보다 더 효과적이다. 더 많은 steps/epochs를 학습시키면 다른 batch size들의 간격은 줄어들거나 사라진다. Supervised learning과 달리 constrative learning은 더 큰 batch size가 더 많은 negative sample들을 만든다. 오래 학습시킬수록 더 많은 negative sample들을 만든다.
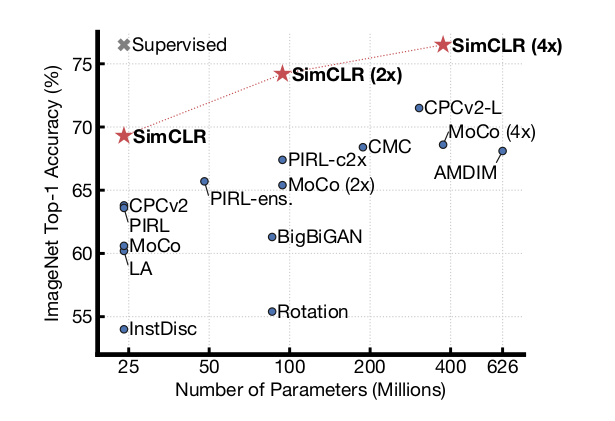
Comparison with State-of-the-art
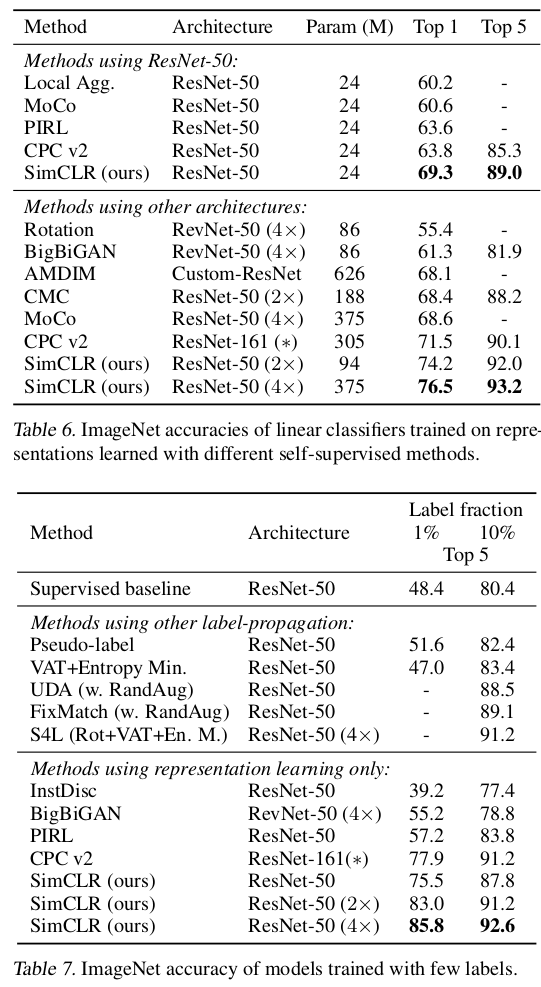
Self-Supervised Learning과 Supervised Learning에서 모두 SimCLR이 가장 높은 성능을 도달했음을 볼 수 있다.
SimCLR의 문제점
SimCLR은 positive sample(x)로 같은 클래스의 이미지들을 모두 negative sample이라고 학습시킨다. Data Augmentation을 통해 많은 negative sample들을 만들수록 positive와 negative간의 간격이 줄어들어 더 정확한 확률을 구할 수 있다. 한 배치크기 안에 많은 negative sample들이 들어가려면 Batch size가 크기 때문에 메모리 사용량도 커지게 된다. 보통의 PC로는 구현하기 어렵다는 단점이 있다.
A100이 40GB인데 SimCLR을 사용하려면 16장 이상 되어야한다.
