Language Modeling은 문장의 확률을 나타내는 모델이다. 즉, 언어 모델을 통해 문장의 출현 확률을 예측하거나, 이전 단어가 주어졌을 때 다음 단어를 예측할 수 있고, 결과적으로 주어진 문장이 얼마나 자연스럽고 유창한 표현인지 계산할 수 있다. 언어 모델을 학습하기 위해서는 인터넷이나 책에서 최대한 많은 문장을 수집하고 단어와 단어 사이의 출현 빈도를 세어 확률을 계산해야 한다. 이 과정의 궁극적 목표는 일상 생황에서 사용하는 실제 언어의 분포를 정확하게 근사하는 것이다.
이를 위해 여러 단어가 나타날 확률을 연쇄법칙(chain rule)을 통해 분리하여 표현할 수 있다.
해석하면, 이 나타날 확률과 이 주어졌을 때 가 나타날 확률, , 가 주어졌을 때 이 나타날 확률, , , , 이 주어졌을 때 이 나타날 확률을 곱하게 된다.
n-gram
언어모델에서는 문장의 확률을 구할 때 각 단어 시퀀스의 출현 빈도를 계산하여야 한다. 하지만, 최대한 많은 단어, 문장, 문서를 구한다고 해도 단어 조합의 수는 실제 예제의 수보다 훨씬 많을 것이고, 조합이 조금만 길어져도 corpus에서 출현 빈도를 구하기 어려워지게 된다. 이를 희소성 문제라고 한다.
이를 해결하기 위해 markov assumption을 도입하게 된다. 이는, 시점의 상태확률은 직전의 개에만 의존한다는 논리이다. 즉, 전체 단어의 조합을 보는 것이 아닌 앞의 개의 단어만 보고 출현 확률을 구하게 되는 것이다. 이렇듯 일부 조합의 출현 빈도만 계산하여 확률을 추정하는 방법을 n-gram이라고 한다.
일반적으로 훈련 corpus의 양이 작을수록 n의 크기도 작아져야하며, 양이 적당하다는 가정하에 3-gram을 많이 사용하며, 양이 많은 경우 4-gram을 사용하기도 한다. 3-gram인 경우 앞의 2개 단어만 보고도 확률을 근사할 수 있게 되었고, 훈련 corpus내에 해당 문장이 존재한 적 없더라도 markov assumption을 도입하여 희소성 문제를 해결할 수 있게 되었다.
Language Model 평가방법
언어 모델을 평가하는 척도인 Perplexity(PPL)은 정량평가 방법의 하나이다. PPL은 문장의 길이를 반영하여 확률값을 정규화한 값이다.
문장이 길어지면 문장의 확률은 굉장히 작아지며, 확률값이 분모에 들어가 있으므로, 확률값이 높을수록 PPL은 작아지게 된다. 따라서, PPL이 낮을수록 좋은 모델이다. 일반적으로 n-gram의 n이 클수록 더 낮은 PPL을 보여준다.
NNLM
n-gram은 훈련 corpus에 존재하지 않으면 출현 빈도를 계산할 수 없기 때문에 확률을 구할 수 없고, 확률 간 비교를 할 수도 없다. 이를 보완해 나온 모델이 신경망 언어모델, NNLM(Neural Network Language Model)이다. NNLM은 word embedding을 사용하여 단어 차원을 축소하여 단어간 유사도를 dense vector로 학습하게 된다. 따라서 NNLM은 훈련 corpus에서 보지 못한 조합을 만나더라도, 비슷한 훈련 데이터로부터 배운 것과 유사하게 대처할 수 있다.
RNNLM
RNNLM은 RNN을 사용한 language model이다.
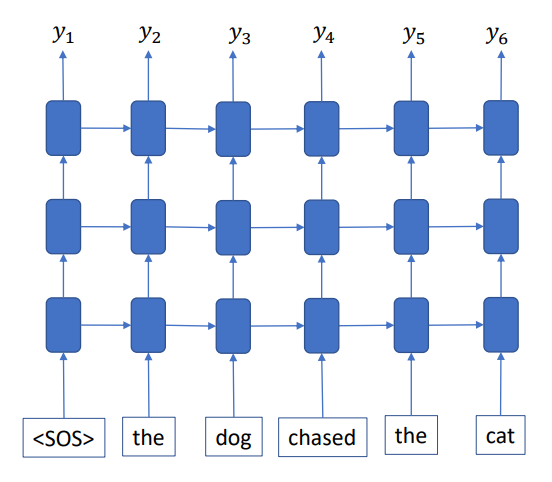
기존의 n-gram은 희소성 문제로 인해 마르코프 가정을 통해 n-1이전 단어만 조건부로 사용하여 확률은 근사하였다. 하지만 RNNLM은 word embedding을 통해 dense vector로 만들어 이 문제를 해결하였으므로 문장의 첫 단어부터 해당 단어 직전까지 모두 조건부에 넣어 확률을 근사할 수 있다.
모델의 예측 과정을 간단하게 설명하면,
먼저, n개의 입력 문장이 있다고 가정하면, 문장의 시작과 끝에는 <BOS(Beginning of Sentence)>, 마지막에는 <EOS(End of Sentence)>가 포함되게 되어 결과적으로 n+2개가 input으로 들어오게 된다. 다음은 token별로 embedding layer에 넣는 과정을 진행하는데, 이 때 마지막 토큰인 <EOS(End of Sentence)>는 제외하고 넣어주게 된다. 그러면 정해진 embedding dimension의 embedding vector를 얻고 이를 RNN의 input으로 넣어주게 된다. RNN을 거쳐 생성된 값을 linear layer와 softmax 함수를 적용해 각 단어에 대한 확률 분포를 구하고, 예측한 확률 분포에 대해 cross entropy를 계산해 최종적인 loss value를 구하게 된다. 이때, 입력과 반대로 <BOS(Beginning of Sentence)>를 제거한 정답과 비교하게 된다. 구해진 loss를 바탕으로 weight이 업데이트되게 된다.
