Translation(번역)의 궁극적 목표는 어떤 언어의 문장이 주어졌을 때, 가능한 언어의 번역 중에서 최대 확률을 갖는 언어의 번역을 찾아내는 것이다.
Rule-Based Machine Translation(RBMT)는 주어진 문장의 구조를 분석하고, 규칙을 세우고 분류를 나누어 규칙에 따라 번역한다. 규칙이 잘 만들어진 경우에는 자연스러운 표현이 가능하지만, 규칙을 만드는 과정까지 사람의 개입은 상당하다. 또한, 언어쌍(ex.한국어-영어) 확장 시 매번 새로운 규칙을 찾아 적용시켜야한다.
Statistic-Based Machine Translation(SMT)는 Neural Network Machine Translation(NMT)이전에 구글이 번역 시스템에 도입하면서 더욱 유명해진 방식이다. 이는 대량의 양방향 코퍼스에서 통계를 얻어내 번역 시스템을 구성하며, 언어쌍 확장 시 RBMT보다 훨씬 유리했다.
이 후, 딥러닝을 이용한 방식이 제안되면서 기존의 방식들보다 훨씬 좋은 성능을 보여주었다. Neural Network Translation(신경망 기계번역)이 잘 동작하는 이유는 다음과 같다.
- end-to-end 모델 : 이전의 모델들은 모듈이 여러가지로 구성되어 있어 복잡도가 상당했지만, 신경망 기계번역 방식은 하나의 모델로 번역을 해결하였다.
- 더 나은 언어 모델 : 신경망 언어모델 기반의 구조이므로, 성능이 더 좋았으며, 희소성 해결, 자연스러운 문장 구성 등 강점을 나타내었다.
- 훌륭한 word embedding : word embedding 과정을 신경망으로 구성함으로써 embedding vector 생성에 적절했고, 노이즈나 희소성 문제에 훨씬 더 잘 대처가 가능했다.
seq2seq
seq2seq는 크게 3개의 서브 모듈인 encoder, decoder, generator로 구성된다.
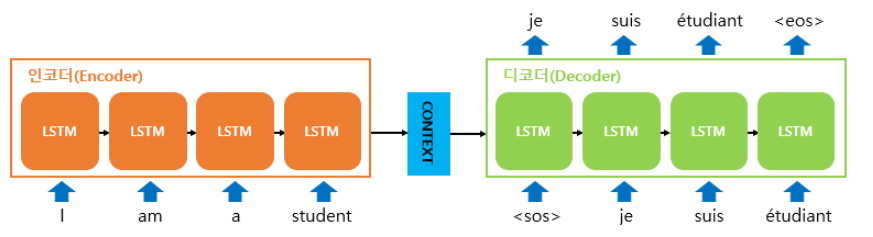
Encoder(인코더)는 여러개의 벡터를 입력으로 받아 word embedding vector로 만들어 낸다. 즉, 주어진 문장을 manifold를 따라 dimension을 reduction하여 해당 도메인의 latent space(잠재 공간)의 어떤 한 점에 투영하는 작업이다.
Decoder(디코더)는 NNLM(신경망 언어모델)의 연장선으로 Conditional Neural Networks Language Model(CNNLM)이라고 할 수 있다. 인코더를 거쳐 나온 word embedding vector와 이전 time-step까지 번역하여 생성된 단어들에 기반하여 현재 time-step의 단어를 생성한다.
Generator(생성자)는 디코더에서 각 time-step별로 output vector를 받아 softmax를 계산하여 target language의 단어별 확률값을 반환하는 작업을 수행하는 모듈이다. 즉, 결과값은 각 단어가 나타난 확률인 이산 분포가 된다.
이러한 seq2seq모델은 기계번역 뿐만아니라 챗봇, 요약, 음성인식, 이미지 캡셔닝, 시계열 데이터등 다양한 분야에 사용되고 있다. 하지만, seq2seq모델은 time-step이 증가하면 word embedding 부분에서의 압축 능력이 저하된다. 또한, 단순히 sequence 데이터로 다루는 경향이 있어 문장의 구조 정보를 사용하지 못하고 있다.
Auto Regression(AR)
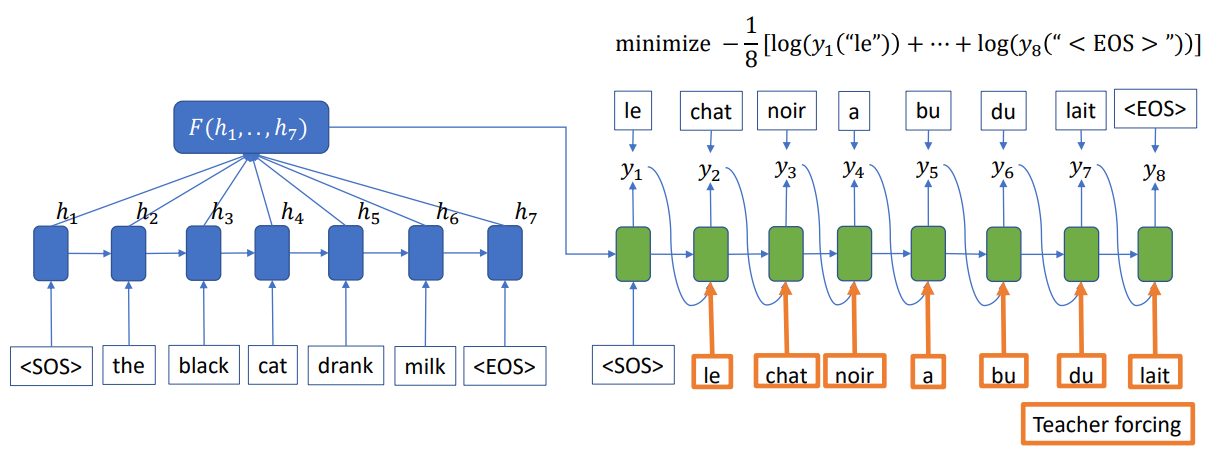
실제 구현된 코드를 보면 seq2seq 훈련 시 디코더의 입력으로 이전 time-step의 출력이 들어가는 것이 아니라 이전 step의 예측값()이 아닌 실제 값()이 들어가게 된다. 하지만, inference 과정에서는 실제 값이 존재하지 않으므로 이전 step의 예측값이 들어가게 된다. 이러한 방법을 teaching forcing이라고 부른다. 학습시 실제 값이 들어가는 이유는 auto regression(자기 회귀) 때문인데, 예측값이 input으로 들어가게 되면 잘못된 예측이 현재에도 영향을 미쳐 문장의 구성이 바뀔 뿐 아니라 길이마저도 달라지게 된다.
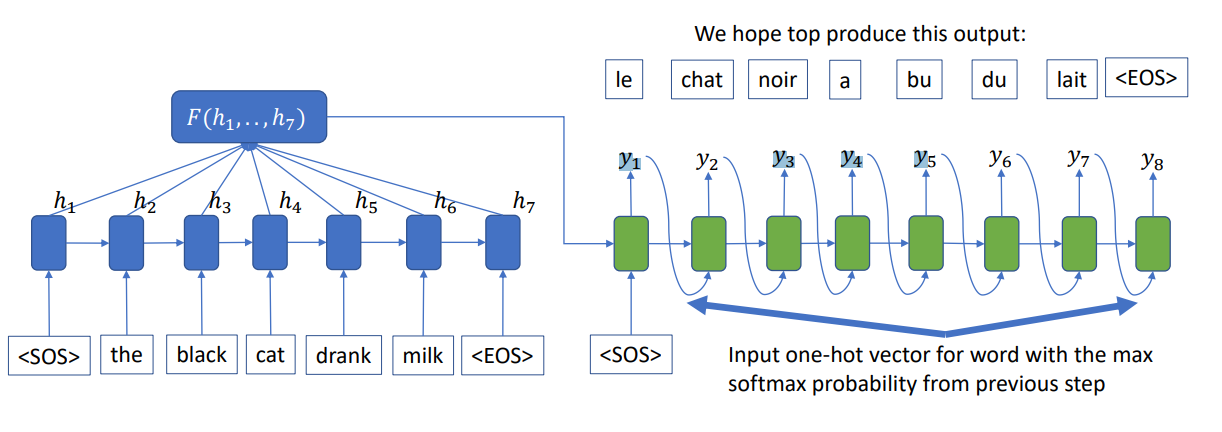
반면에 훈련 시 실제값()이 존재하지 않고 입력()만 주어져 예측값()을 추론하는 경우도 존재한다. 이러한 과정을 추론 또는 탐색이라고 부른다. 이는 search algorithm(탐색 알고리즘)에 기반하며, 단어들 사이에서 최고의 확률을 갖는 경로를 찾는 것이다.
먼저 정확한 방법은 매 time-step별 softmax의 결과대로 샘플링 하여 최종적으로 EOS가 나올 때 까지 반복하는 것이다. 하지만, 이 방식은 같은 input에 대해 매번 다른 결과를 만들어낼 수 있는 문제가 있다.
다음은 greedy search algorithm을 활용해 softmax 결과 중 가장 확률이 큰 index를 뽑아 해당 time-step의 예측값()으로 사용하는 것이다. 하지만, 이는 최적의 해를 보장하지 않는다는 문제가 있다.
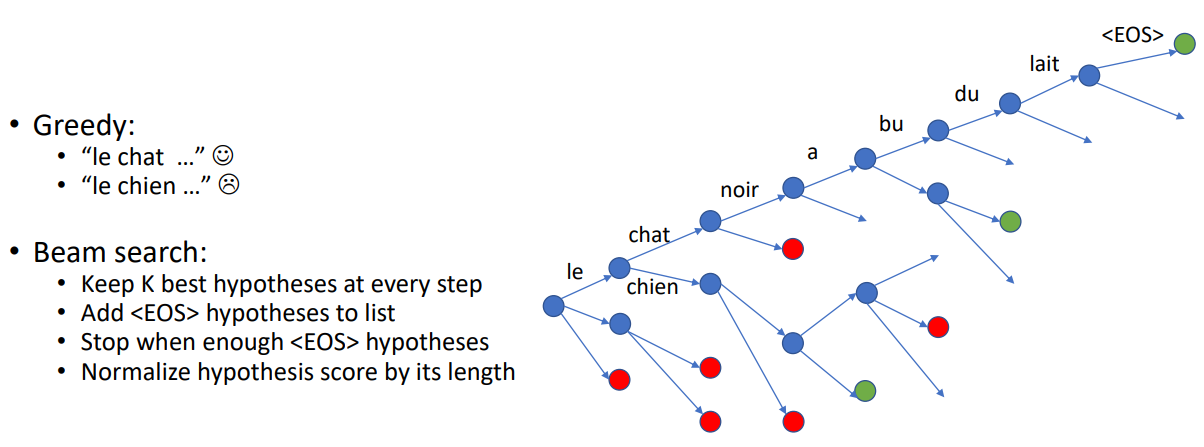
마지막으로 beam-search이고, greedy search에서 k개의 후보를 더 추적하는 것이다. 즉, 현재 time-step에서 최고 누적 확률을 가진 k개의 단어의 index를 뽑아 다음 time-step에 대해 k번의 inference를 수행하고, 이 중 다시 최고 누적 확률 k개를 뽑아 다음 time-step으로 넘겨준다. 이 방법은 기존 탐색보다 성능은 올라가지만, k개 만큼의 번역을 수행해야하므로 속도 저하가 일어나게 된다.
Attention
Attention(어텐션)은 Query(쿼리)와 비슷한 값을 가지는 Key(키)를 찾아서 Value(값)을 얻는 과정이다. 번역과정에서 인코더의 각 time-step별 출력값을 key와 value로 삼고 현재 time-step의 디코더 출력을 query로 삼아 계산한다. 즉, key, value의 소스는 인코더의 출력값이고, query의 소스는 디코더의 이전 step까지의 출력인 것이다.
어텐션을 다음과 같이 계산하게 되는 이유는 기존의 seq2seq모델에서 디코더의 input은 인코더의 embedded된 vector이며, 이를 바탕으로 hidden state를 만들어내는데, 이 과정에서 문장의 모든 정보를 전달하기 어려워진다. 문장이 길어질수록 이 문제는 더 심각해지게 된다. 따라서, 현재 디코더의 hidden state를 구하기 위해 디코더의 매 time-step마다 인코더의 마지막 hidden state를 추가적으로 입력으로 넣어주게 되는 것이다.

Key, value와 query의 소스 언어와 대상 언어가 다르기 때문에 이 두 언어의 embedded latent space가 선형관계에 있다고 가정하여 내적 연산을 수행하기 전 linear transformation을 수행하고, 이를 통해 현재 상태에 따라 필요한 query를 만들어내고 인코더의 key값들과 비교하여 weighted sum(가중합)을 하는 것이다. 따라서, 현재 디코더의 상태에 따라 필요한 정보가 무엇인지를 스스로 판단하여 선형 변환을 통해 query를 만들어 낸다.
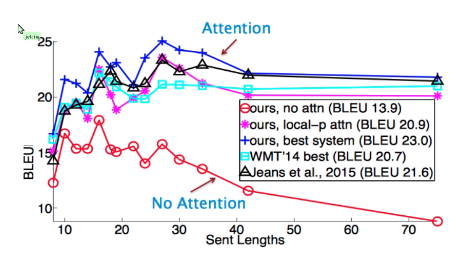
seq2seq와 어텐션의 성능을 비교하면, 문장이 길어질수록 seq2seq의 성능은 급격하게 하락하는 반면, attention모델은 성능이 크게 하락하지 않음을 알 수 있다.
Evaluation
PPL
기계 번역도 매 time-step 마다 가장 높은 확률을 갖는 단어를 선택하는 작업이므로 기본적으로 분류에 속하게 된다. 따라서 perplexity(PPL)로 성능을 측정할 수 있다.
BLEU(Bilingual Evaluation Understudy)
BLEU는 정답 문장과 예측 문장 사이에 일치하는 n-gram 개수의 비율의 기하평균에 따라 점수가 매겨진다. 즉, 각 n-gram 별 precision의 평균을 백분율로 나타낸 것이다. 또한, brevity penalty는 예측된 번역문이 정답 문장보다 짧을 경우 점수가 좋아지는 것을 방지하기 위한 부분이다.
성능 평가 결과를 해석할 때, PPL은 낮을수록, BLEU는 높을수록 좋은 모델이다.
