2017년 transformer 논문이 게재된 후 다양한 pre-trained model들이 제시되었다. 그 중 이번 글에서는 대표적인 pre-trained method인 ElMo, GPT, BERT를 짧게 소개하려고 한다.
ELMo
기존의 transforemer에서는 word embedding layer에서 trained된 word embedding method를 사용하였다. Word embedding이 진행되는 과정은 vector로 변환된 word들을 embedding matrix를 거치고 나면 embedded space에 따라 각 word마다 특정 vector값으로 대응되게 되는 것이다. 이 과정에서 embedding matrix가 일종의 look-up table이 되는 것이다.
이러한 과정에서의 한계점은 word를 특정 embedded vector로 표현하는 것이 가능하지만, 하나의 word가 문맥에 따라 서로 다른 의미를 가지는 경우까지 고려할 수 없다는 점이다. 이를 기반으로 ELMo에서는 새로운 word embedding 방법인 "Contextualized Word Embedding"을 제시한다.
Contextualized Word Embedding
기존의 word embedding은 embedding matrix가 존재하는 반면, ELMo는 이를 bi-LSTM layer로 대체한다.
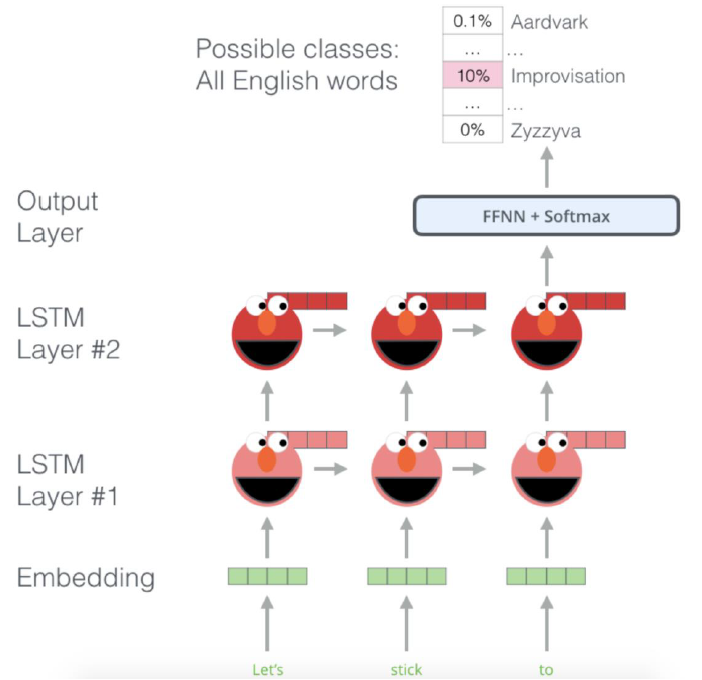
Word embedding 과정을 bi-LSTM으로 대체한 이유는 기존의 word embedding 방식의 한계인 contextual information을 포함하기 위해서이다. 위의 그림에서의 예제를 바탕으로 설명하면, 그림에서의 LSTM layer은 Bi-LSTM이므로, 각 forward, backward가 가능하다. 따라서 이를 통해 contextual information을 학습할 수 있으며, "Let's", "stick", "to"의 token이 들어왔을 때 다음으로 올 word를 예측하면서 unsupervised learning이 진행된다.
이와 같은 과정으로 ELMo를 training하고, 이렇게 pre-trained된 ELMo를 기존의 word embedding 대신에 사용하게 되는 것이다.
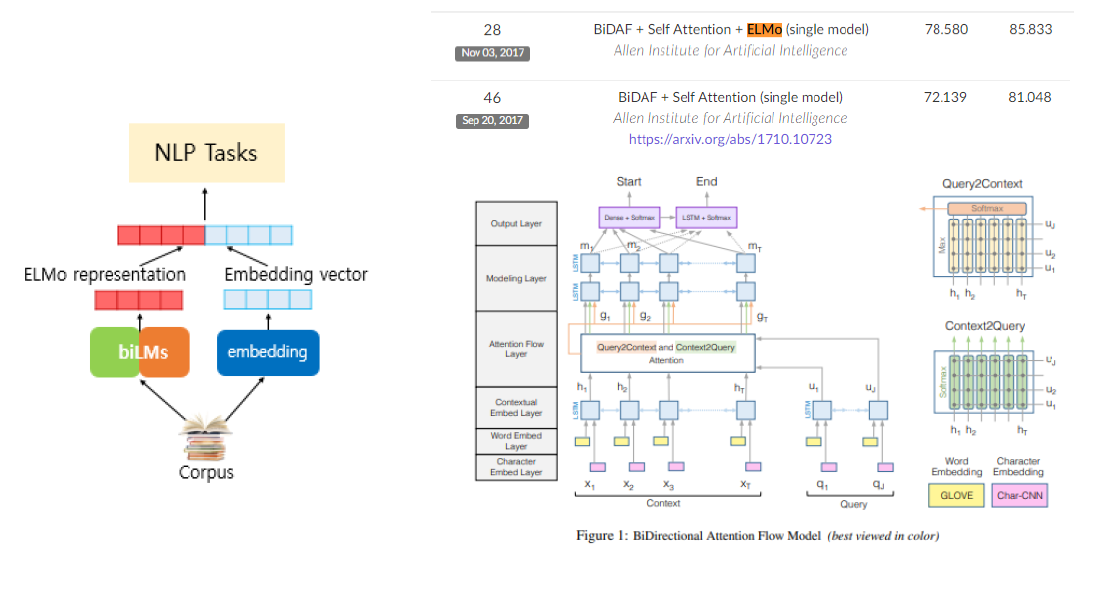
ELMo논문에서는 Transformer에 적용한 실험은 진행하지 않았고, BiDAF(Bidirectional Attention Flow)모델에 ELMo를 적용한 실험을 진행하였고, 위의 그림은 이에 대한 architecture을 그린 것이다.
ELMo가 제시되기 이전에는 GLOVE, Char-CNN을 대부분 사용하였지만, ELMo를 적용하는 것이 더 성능이 좋아 이후에는 대부분의 모델이 ELMo를 사용하였다고 한다.
GPT
ELMo의 구조는 transformer 기반 모델이 아닌, transformer와 비슷한 구조를 가지도록 설계한 모델이다. 이제부터 transformer 구조 기반의 pre-trained model인 GPT와 BERT를 설명하려고 한다.
먼저, GPT는 2018년 OpenAI에서 제시한 모델이며, transformer의 encoder, decoder layer 중 decoder block만 쌓아서 만들어진 모델이다. Transformer에 대한 설명은 이전 글을 참고하면 될 것 같다.
기존의 transformer은 base 모델이 총 12레이어(encoder-6, decoder-6)을 사용하였고, large 모델이 총 24레이어(encoder-12, decoder-12)를 사용한 것에 비해, GPT는 decoder 레이어를 각각 small이 12, medium이 24, large가 36, extra-large가 48 레이어를 사용하였다. Transformer의 decoder레이어를 그대로 가져와서 쌓은 구조이다.
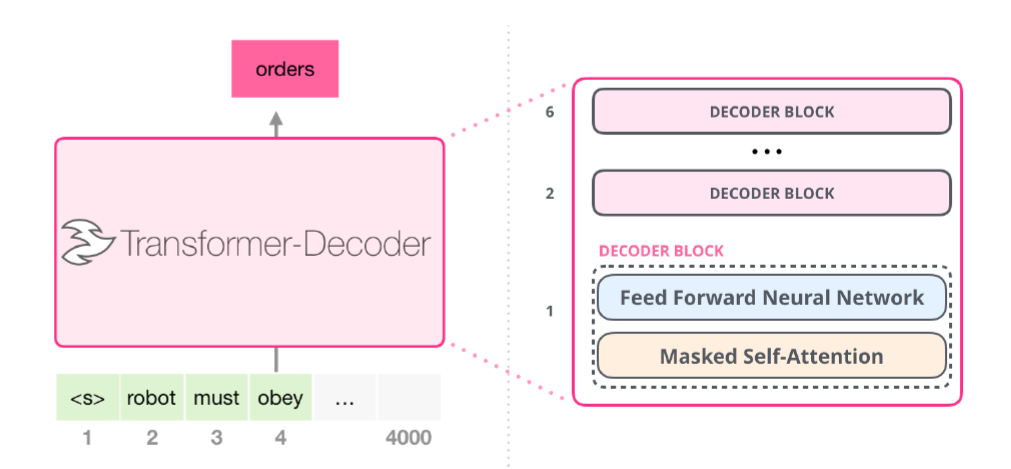
Transformer의 decoder의 구조를 간략하게 보면 다음과 같으며, 이전에서 설명한 것과 같이 masked self-attention 모듈이 있는 것을 확인할 수 있다.
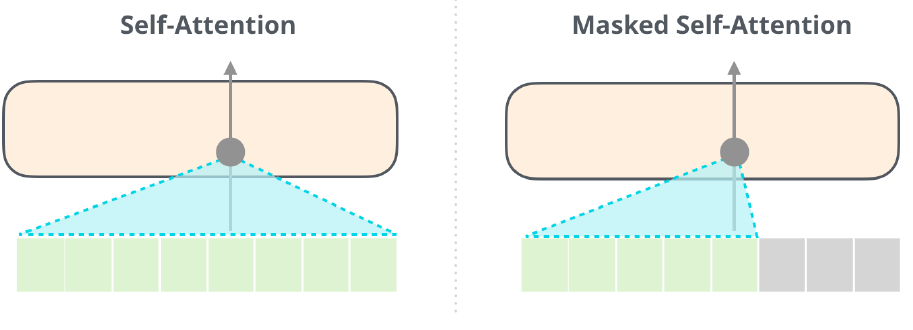
Maksed Self-Attention은 input에 masking된 token이 존재하며 decoder의 module인 만큼 sequential하게 input을 받게 된다. 이는 곧 auto-regressive method(forward direction)이며, next sentence prediction과 같은 generation task에 적합하게 된다. 위의 ELMo의 training 목적이 다음 단어 예측임을 고려하면 ELMo, GPT 두 모델의 task가 동일한 것이다.
GPT의 각 layer을 좀 더 세밀하게 보면 다음과 같다.
Input Encoding
먼저, token embedding, positional encoding은 기존 transformer와 동일하며 차이는 dimension의 크기이다. Token embedding과 positional encoding에서의 embedding size는 768(small), 1024(medium), 1280(large), 1600(extra large)이며, contect size는 1024로 기존 transformer가 512였던 것을 보면 두배 늘어났음을 알 수 있다. Token embedding, positional encoding을 거쳐 input이 masked self-attention layer로 들어가게 된다.
Self-Attention in GPT
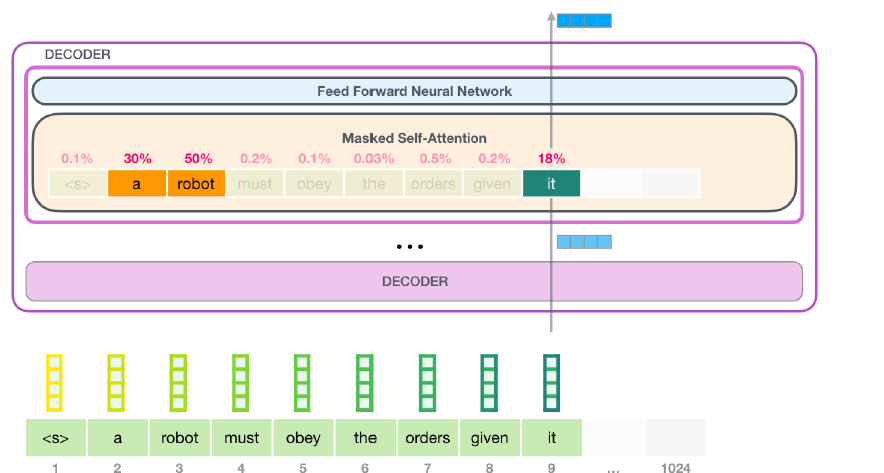
Encoding된 input이 masked self-attention layer로 들어오는 과정을 표현한 그림이다.
현재 state의 input은 token "it"이며, masked self-attention layer에서 token "it"을 포함한 모든 단어와 "it"과의 attention score을 구하고, 이를 바탕으로 token "it"에 대한 새로운 representation을 만들게 된다.
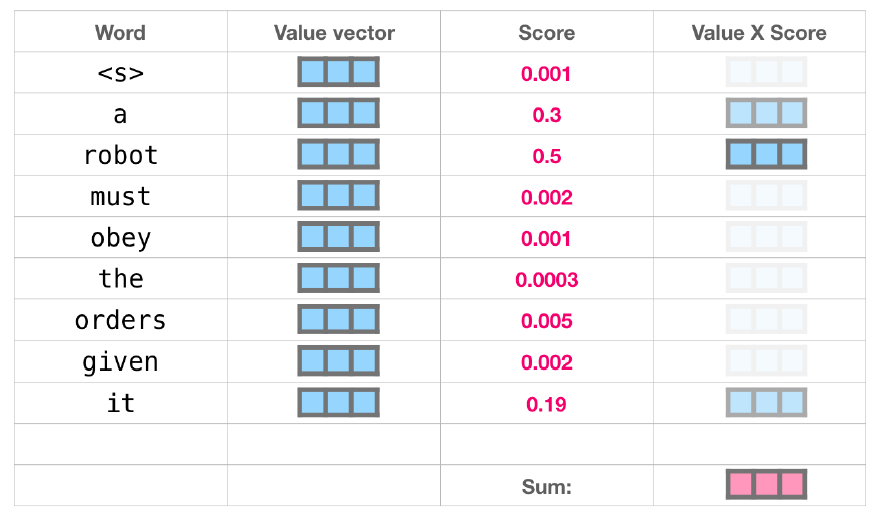
즉, 위의 그림처럼 score값이 계산되면 각각의 token의 value값과 attention score를 구해 summation을 통해 새로운 representation을 생성하는 것이다. 기존의 transformer과 마찬가지로 생성된 representation을 feed-forward layer, softmax 등을 거쳐서 최종적인 output이 계산되게 된다.
Output
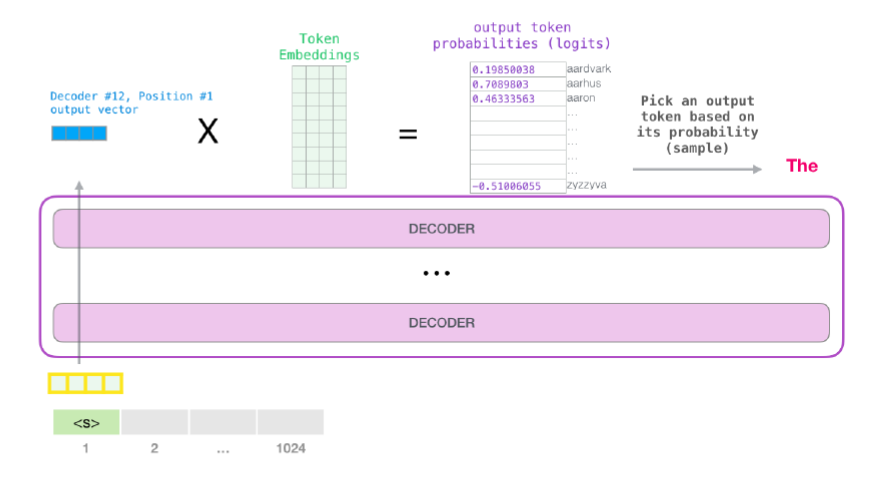
Decoder의 task는 generation이므로, 위의 예제에서 "it" 다음에 올 단어를 예측해야 한다. 이를 위해 모든 decoder layer을 거쳐서 최종적으로 생성된 output과 token embedded matrix를 곱해 probability를 구하고, 가장 높은 값을 가진 logit의 word로 다음 단어를 예측하게 되는 것이다.
Fine-tunning
방대한 양의 corpus를 통해 다음과 같은 과정을 거쳐서 pretraining을 진행하게 된다. Pre-trained된 GPT를 각 task에 맞는 downstream task를 진행하게 된다.
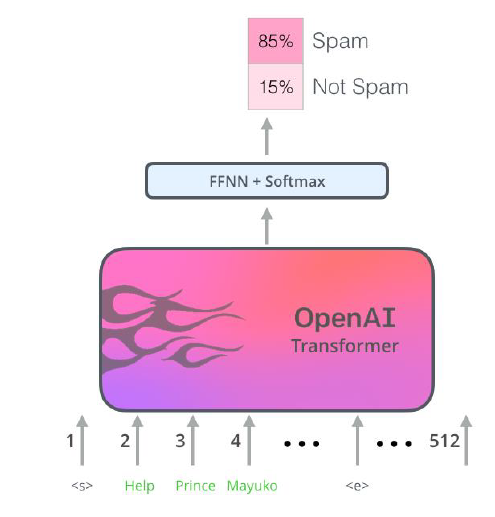
이는 위의 과정으로 pre-trained된 model을 바탕으로 spam/not spam인지를 분류하는 task를 한 예이다.
BERT
다음은 transformer 기반의 pre-trained model인 BERT이다.
GPT와 달리 BERT는 transformer의 encoder 구조만 가져와 쌓아서 만든 모델이다. BERT base는 12layer, BERT large는 24 layer로 구성되어 있으며, hidden units의 dimension은 각각 768, 1024이다.
Architecture
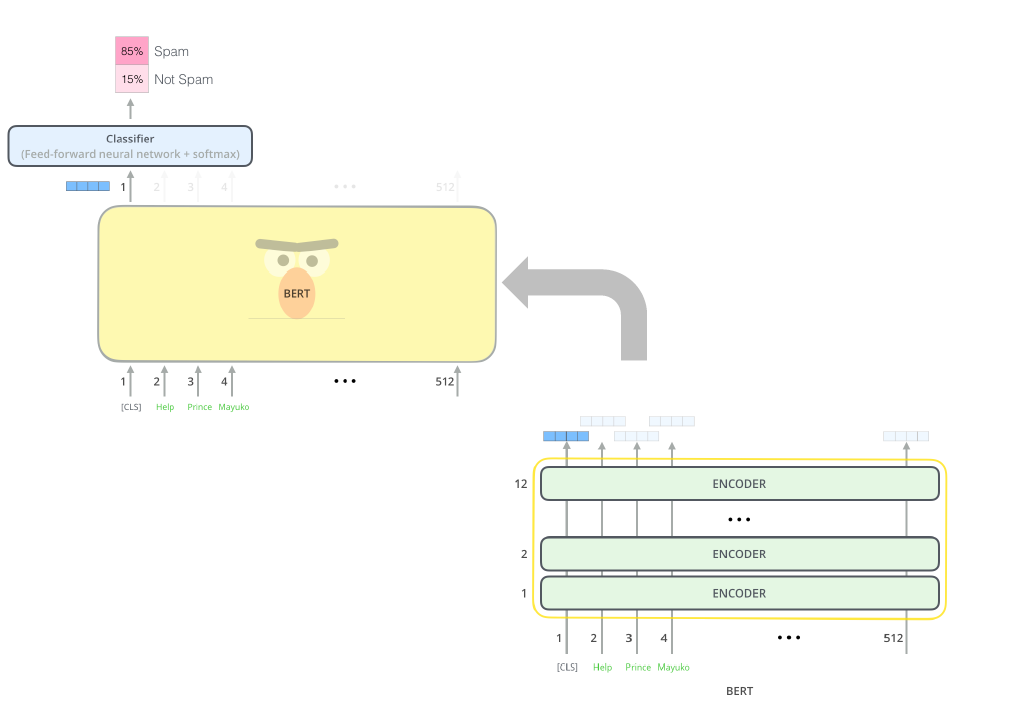
BERT의 개괄적인 구조이며, encoder(BERT라고 표기된 부분)와 Classifier로 나뉘는 것을 볼 수 있다. BERT에서 classifier은 기존 transformer의 encoder 구조에서 feed-forward+softmax를 나타내며, 그 이전의 모듈들을 encoder라고 부른다. GPT와 BERT의 task에도 차이가 있는데, GPT는 generation 기반의 task를 진행한 반면, BERT는 classification, MRC등 generation을 제외한 다양한 downstream task를 진행하였다.
Transformer / BERT
Encoder의 구조는 기존의 transformer와 동일하지만, transformer와 BERT의 차이점은 세가지 정도가 존재한다.
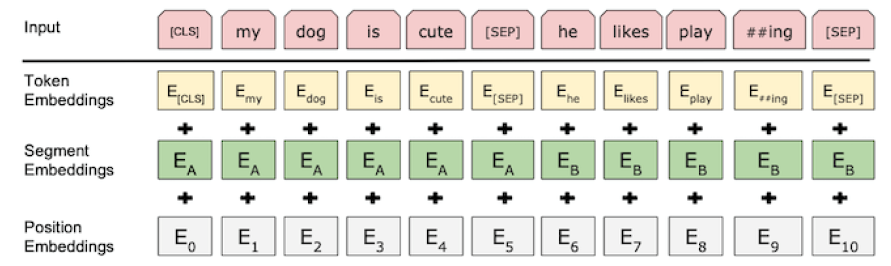
첫번째로, [CLS] token을 사용하였고, 이는 classification을 할 때 사용되는 token이다. 위의 그림에서 볼 수 있듯이 encoder을 거친 vector들 중 첫번째 vector을 가져와 classifier에 넘겨주는 것을 볼 수 있다. [CLS] token은 encoder layer을 거치면서 나머지 token들의 정보를 바탕으로 representation이 생성되며, 이는 곧 나머지 token의 정보를 모두 담고 있다는 의미이다. 이와 같은 이유로 [CLS] token의 output을 classifier에 넘겨주게 되는 것이다.
두번째로, position encodings이 아닌 position embeddings로 표현된 것을 확인할 수 있다. Position encoding은 고정된 값(sinusoid)인 반면 position embedding은 특정 값으로 initialize시키지만, learnable하게 값을 넣어주게 된다.
세번째로, [SEP] token이 존재하며, 이는 heterogeneous한 input을 구별하기 위한 token이다. Question & Answering 같은 경우 질문과 답이 이어지는 문장이 아닌 서로 독립적인 문장이다. 이를 구별없이 넣어주게 되면 학습 과정에서 문제가 생길 수 있으며, 이를 방지하기 위한 것이 [SEP] token이다. [SEP] token만으로 이를 구별해주기는 부족하여 BERT에서는 추가적으로 Segment embedding layer가 존재하며, 결과적인 input은 transformer(word embedding + position encoding)과 달리 word embedding + position embedding + segment embedding으로 들어가게 된다.
Pre-training
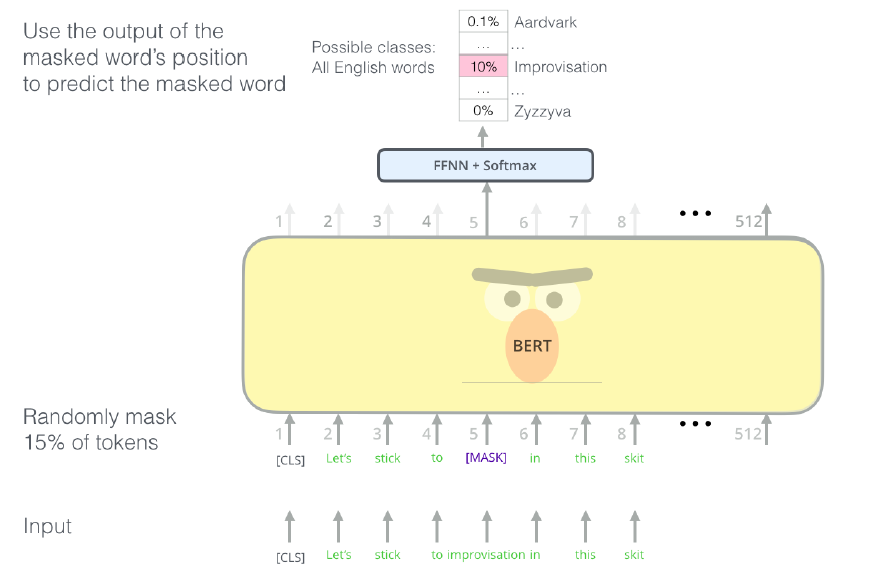
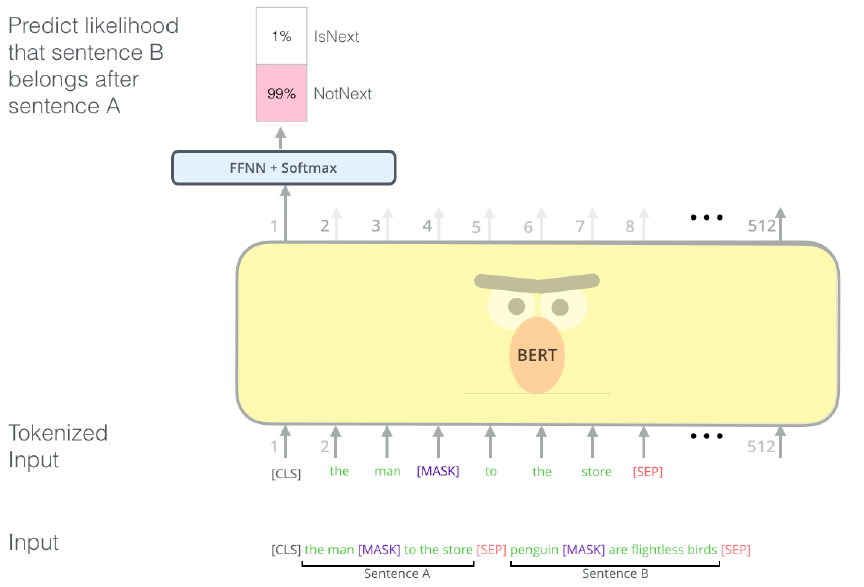
BERT를 pre-training하는 과정에서의 task는 masked LM + next sentence prediction이다.
Masked LM
Next Sentence Prediction
Fine-tuning
Pre-trained된 BERT를 바탕으로 다양한 downstream task를 진행하였다. 이 뿐만아니라 BERT는 feature extraction에도 사용 가능하다고 한다.
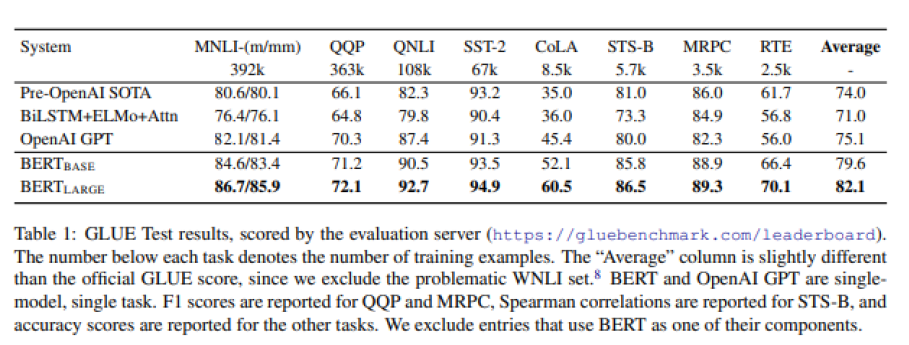
Table에서 볼 수 있듯이 performance가 상당히 증가한 것을 볼 수 있다.
Overall
Transformer는 상당히 많은 parameter을 동반한다. 따라서, xavier initialization이나 random initialization의 방법등을 통해 parameter들을 initialization하여 학습을 진행하게 되면 최적 parameter로 학습되기는 매우 힘들다. 따라서, pre-trained된 parameter들을 가져옴으로써 downstream에 맞는 task learning이 진행될 때 좀 더 나은 학습의 시작점을 제공하는 것이다. Scratch부터 model을 학습하는 것보다 pre-training 후 task에 맞게 transfer learning을 하게 되면 성능이 더 좋아진다는 실험 결과가 해당 논문들에 제시되어 있다.
