Transformer은 Google이 발표한 [Attention is all you need]에서 제시된 모델이다. 이 논문은 기존의 attention을 활용하여 seq2seq를 구현하면서 성능과 속도의 개선을 보였다.
먼저 transformer의 구조는 아래와 같다.
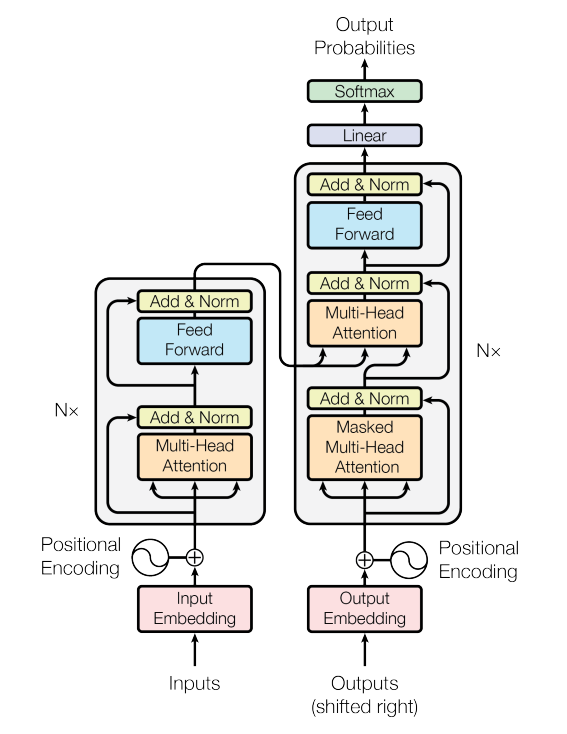
모델의 구조에서 볼 수 있듯이 정말 'attention'을 사용해 인코딩과 디코딩을 수행한 것을 볼 수 있다. Transformer의 sub-module은 크게 세가지로 나뉠 수 있다.
- self-attention : 이전 계층의 출력에 대해 attention 연산을 수행한다.
- attention : 기존의 seq2seq와 같이 인코더의 결과에 대해 어텐션 연산을 수행한다.
- feed-forward : attention의 결과를 취합하여 전달하는 역할을 수행한다.
인코더는 여러개의 self-attention block과 feed-forward block으로 이루어져 있고, 디코더는 여러개의 self-attention, attention, 그리고 feed-forward block으로 이루어져 있다. 그림에서 볼 수 있듯이 self-attention, attention, feed-forward 이전과 이후의 결과에 대해 residual connection이 존재하는 것을 볼 수 있다.
Encoder
Positional Encoding
RNN은 데이터를 순차적으로 받으며 자동으로 순서 정보가 기록되게 된다. 하지만, transformer은 RNN을 이용하지 않으므로 순서 정보를 제공해야 한다. 같은 단어라도 순서에 따라서 의미와 내포하는 말이 다르기 때문이다. 이를 위해 transformer에서는 word embedding vector에 positional encoding 값을 더해서 인코더의 input으로 넣어주게 된다.
Positional encoding은 다음과 같이 계산된다.
디코더의 구조에도 보면 positional encoding을 더해주는 부분이 존재한다. Transformer의 구조는 encoder의 output이 각 layer의 디코더의 input으로 들어가게 된다. 이 때, encoder의 output값에 위의 식으로 계산된 positional encoding
이 더해져 디코더의 input으로 들어가게 되는 것이다.
Multi-head Attention
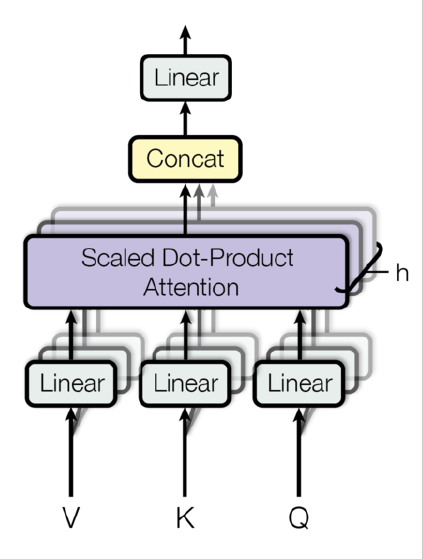
다시 인코더의 구조를 살펴보면, 먼저 Multi-Head Attention 모듈을 볼 수 있다. 이는 CNN에서 다양한 필터로 여러개의 feature을 뽑아내는 것과 비슷하다고 생각하면 될 거 같다. 하나의 input에 대해 다양한 query, key, value 값을 계산하여 이를 바탕으로 여러개의 attention 값이 구해지게 되는 것이다.
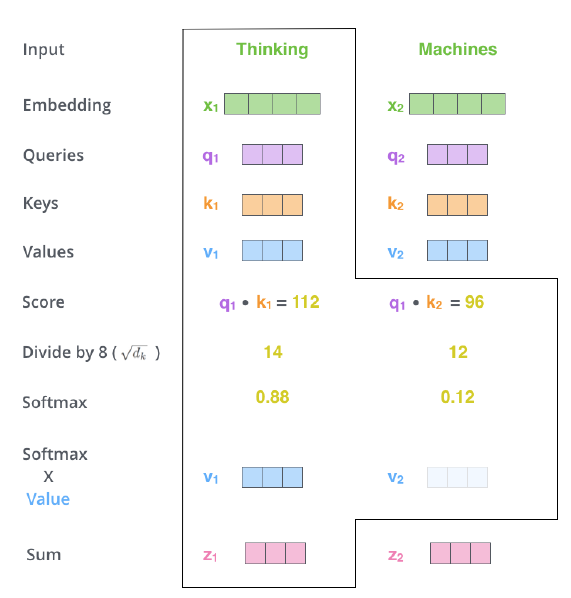
Query, key, value 값을 구하는 과정은 다음과 같다.
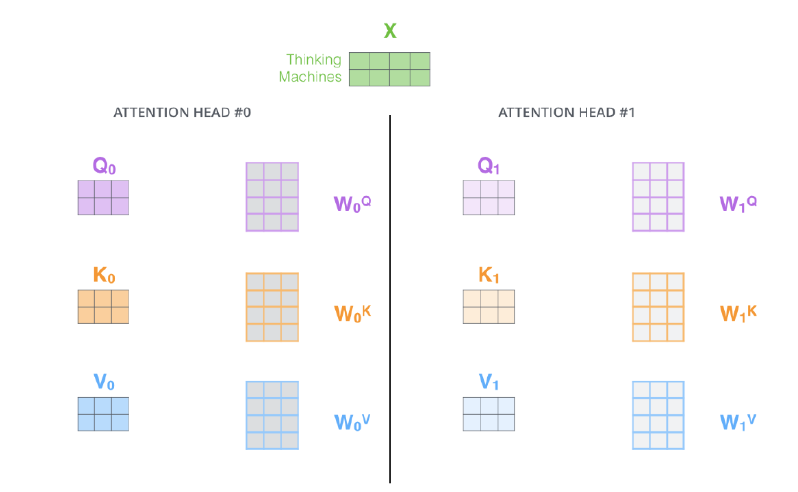
동일한 input 에 대해 서로 다른 weights 가 존재하며 이들은 모두 learnable paremeter이다. Linear dot product를 통해 이 계산되게 되고, 구해진 값들은 Scaled Dot-product Attention 과정을 통해서 Attention Score가 계산되게 된다.
Scaled Dot-Product Attention을 도식화하면 다음과 같다.
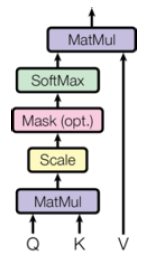
Scaled가 붙은 이유는 key의 차원()가 주어졌을 때, 행렬 곱 연산 결과를 로 나눠주기 때문이다.
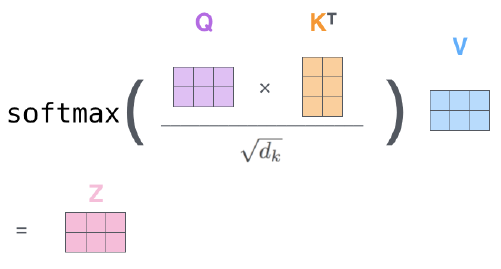
전반적인 Scaled Dot-product attention의 구조는 다음과 같다.
Multi-head attention이므로, 해당 과정을 head의 수만큼 진행하게 된다.
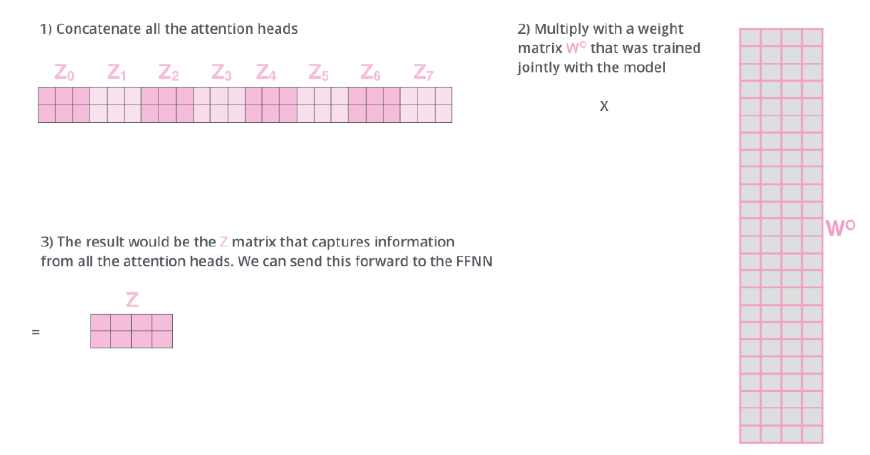
Multi-head attention을 거쳐서 나온 output에 query, key, value 값을 구해줄 때와 마찬가지로 weight 를 곱해서 최종적인 output을 구해주게 된다.
Transformer의 구조에서 보면 Add & Norm이 상당히 많은 것을 볼 수 있다. 여기서의 Add는 residual을 의미하는 것이고, norm은 layer normalization이다. 모두 동일하게 적용된다.
Add & Norm / Feed-Forward
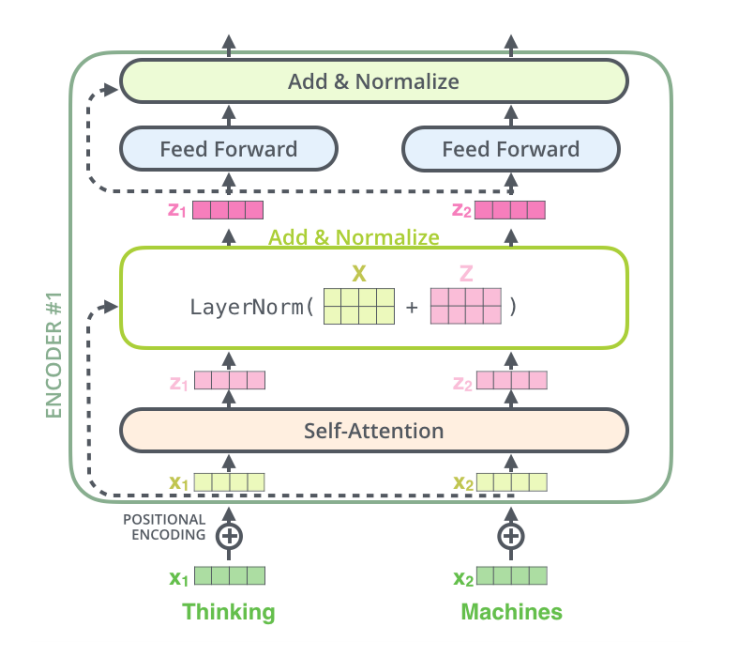
Self-Attention을 거쳐 생성된 output은 Add&Normalize의 input으로 들어가게 된다. Add&Norm의 layer은 이름 그대로 residual파트와 normalization파트로 구성되어 있다. Residual 파트는 encoder의 input을 다시한번 RNN처럼 의 구조처럼 더해주는 부분이고, normalization은 layer normalization을 진행하는 부분이다. 그림에서처럼 self-attention의 output 와 encoder의 input 를 더해서 layer normalization을 적용시키면 Add&Normalize의 최종 output이 계산되게 된다.
Add & Norm까지 거친 결과는 feed-forward의 input으로 들어가게 되고, feed-forward는 layer가 2개인 MLP이다. 이 논문에서는 sequence length(hyperparameter)을 512로 설정하였고, feed-forward의 각 layer의 neuron의 수는 512를 input layer, 2048을 hidden layer, 512를 output layer로 bottle-neck 구조를 도입하였다. Feed-forward의 역할은 multi-head attention으로 나온 다양한 정보들을 합쳐주는 역할을 한다고 생각하면 될 것 같다.
Decoder
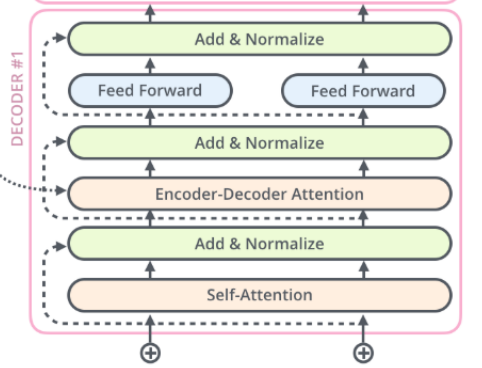
Decoder의 multi-head attention 구조는 encoder과 크게 다르지 않다. 다만, encoder에는 attention layer가 self-attention layer만 존재했지만, decoder에는 self-attention layer, encoder-decoder attention layer가 존재한다.
Decoder의 input부터 self-attention, add&normalize까지의 과정은 encoder와 동일하게 계산이 되어진다. Encoder-decoder attention 부분이 차이점이며, 이 부분을 설명하자면 다음과 같다.
기존의 self-attention을 구하기 위해서는 동일한 input을 바탕으로 서로 다른 Q, K, V 벡터가 계산되는 것에 비해, encoder-decoder attention 부분에서는 Query 값을 구할 때는 이전 layer의 output을 input을 사용하는 반면, Key, Value 값을 구할 때는 encoder의 output으로부터 계산되어진다.
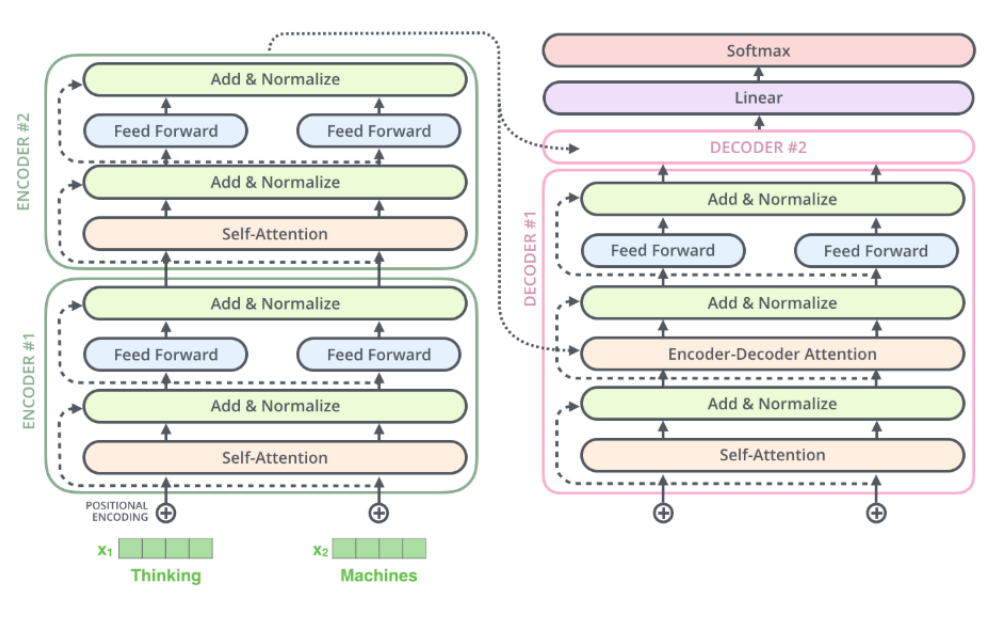
Encoder와 decoder가 연결 된 부분을 한번에 보면, 위의 그림과 같다. 그림에서처럼 매 decoder layer에는 encoder-decoder attention layer가 존재하므로, 매번 동일한 encoder의 output을 넣어주게 된다.
여러개의 decoder layer을 지나면 마지막에 linear layer와 softmax layer가 존재하는 것을 볼 수 있다. Transformer은 machine translation 모델이므로, source input을 바탕으로 target output을 내뱉어야하고, target language에 맞는 word를 예측하는 것이 목적이다. 따라서, decoder의 output에 linear layer을 붙여 logit을 계산하고 계산된 logit에 softmax를 씌워 logit probability를 구해 그 중 가장 높은 확률을 가진 단어가 source에 의해 구해진 target word가 되는 것이다.
Decoder의 multi-head attention 이전에 masked multi-head attention layer가 존재한다. Input token 중 임의의 token들을 masking해서 넣어주고, masked된 token들 간에도 attention score는 계산되기 때문에 인위적으로 구해진 self-attention score을 상당히 큰 음수값으로 바꿔주면서 softmax를 적용했을 때 0 값이 나오도록 해주게 된다. Masked multi-head attention의 output은 위에서 설명한 것 처럼 Query 값을 구하기 위해 사용되어진다.
