자연어처리에서는 각 단어가 갖는 의미가 서로 연관성이 있을 때도 있지만, 형태가 다른 경우 겉으로 보이는 형태만으로는 파악하기 어렵다. 따라서, 단어나 문장, 문서 전체를 벡터로 나타내는 것은 불가피하다. 이러한 이유로 자연어를 벡터로 mapping 해주는 함수를 만드는 과정은 매우 중요하다.
코퍼스로부터 단어의 특징을 추출하여 벡터로 만드는 과정에서 curse of dimensionality(차원의 저주)로 인해 결과물은 여전희 sparse vector(희소 벡터)로 나타내지게 된다. 하지만, 이러한 sparse vector(희소 벡터)로 나타내는 것 보다는 dense vector로 나타내는 것이 훨씬 유용하다.
Dimensionality Reduction
Principle Component Analysis (PCA)
차원 축소의 대표적인 방법으로 Principle Component Analysis (주성분 분석)이 있다. 주성분은 주로 sinpular value decomposition(SVD)를 통해 분석할 수 있다. 이때 주성분은 다음과 같은 조건을 만족해야 합니다.
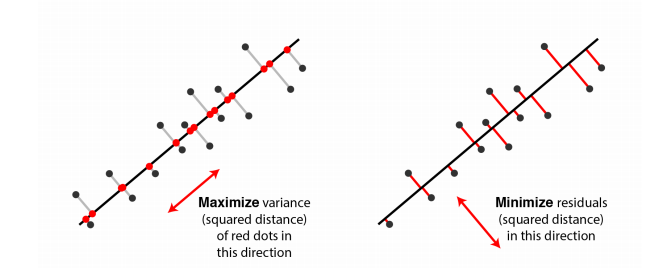
1. 데이터들을 임의의 hyperplane에 projection하였을 때, 투사된 점들간의 거리가 최대가 되어야 한다. 즉, 투사된 점들간의 분산이 최대가 되어야 한다.
2. 투사 전 벡터와 투사 후 벡터의 거리는 최소가 되어야 한다.
PCA를 통해 고차원 데이터를 낮은 차원으로 압축할 수 있지만, 투사 전 후의 벡터의 값과 위치가 달라지므로 정보의 손실이 생길 수 밖에 없다. 정보의 손실이 클 수록 효율적으로 학습이 불가능하기에 지나치게 낮은 차원으로 축소하거나 데이터가 비선형인 경우 힘들어지게 된다.
Manifold Hypothesis
위와 같은 한계로 인해 manifold hypothesis를 도입하게 된다. 고차원 데이터의 경우 이를 아우르는 낮은 차원의 manifold(다양체)가 존재한다는 것이 manifold hypothesis이다.
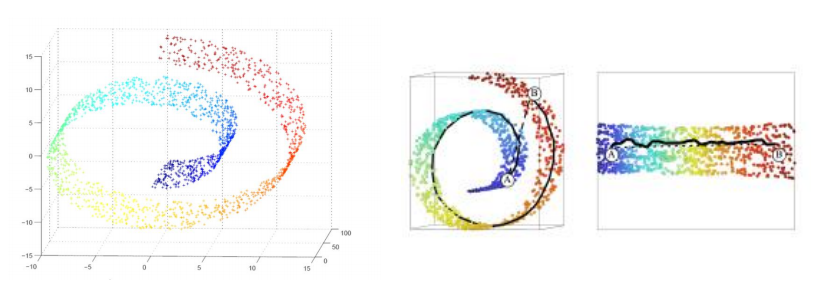
위의 그림처럼 실제 데이터는 3차원 공간내에 존재하지만, 소용돌이 모양의 2차원 manifold가 존재할 수도 있다. 따라서, manifold를 찾아 펼칠 수 있다면 PCA처럼 낮은 차원으로의 projection에서 생기는 손실을 최소화 할 수 있게 된다.
또한, 두번째 그림에서처럼 3차원 공간에서 가깝게 보이는 데이터 A와 데이터 B는 낮은 차원으로 mapping을 하게 되면 멀어질 수 있다. 그리고 저차원의 공간상에서 가까운 점끼리는 실제로도 비슷한 feature (특징)을 갖게 된다.
이처럼 차원축소는 결과적으로 manifold를 찾는 과정이며, PCA와 같은 방법은 선형적인 방식이다. 딥러닝도 task를 해결하기 위해 차원 축소를 수행하게 되는데 이는 비선형적인 방식으로 차원 축소가 진행되며 이 과정에서 task에 적합한 manifold가 자연스럽게 구해지게 된다.
Autoencoder
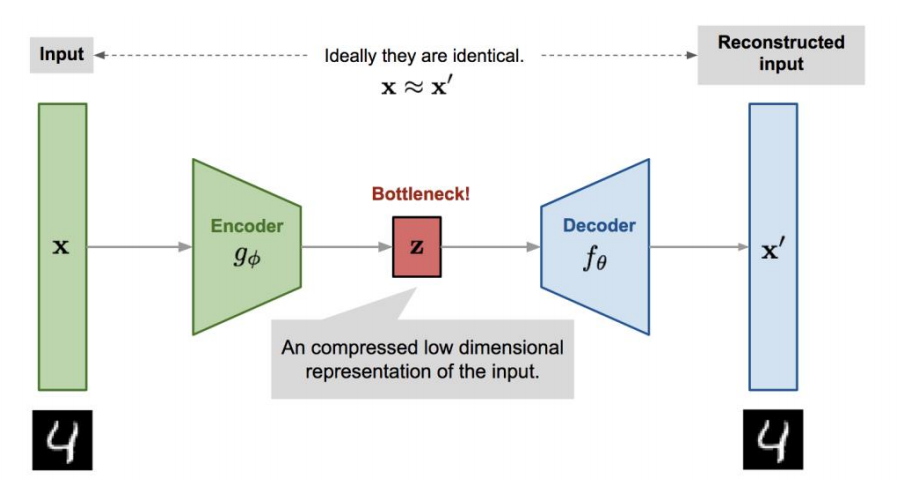
Autoencoder (오토인코더)는 다음과 같은 구조를 가진 딥러닝 모델로써, 고차원의 sample vector을 입력으로 받아 저차원으로 축소하여 bottle-neck 구간에서의 hidden vector로 표현되게 된다. 인코더를 거쳐 저차원으로 축소된 벡터를 디코더의 입력으로 받아 원래 데이터가 존재했던 고차원으로 복원하게 된다.
Bttle-neck 구간에서 압축되는 차원이 매우 낮기 때문에 autoencoder는 복원에 필요없는 정보는 모두 버려야하며, 이를 위해 모델 훈련시 복원 데이터와 실제 입력 데이터간의 차이를 최소화하도록 loss function을 구성하게 된다. Autoencoder를 사용하여 sparse feature vector을 입력으로 넣어 훈련했을 때, autoencoder의 bottle-neck layer의 결과값을 dense word embedding vector로 사용할 수 있다.
word2vec
토마스 미콜라프에 의해서 제시되었으며 CBOW[1]와 Skip-gram[1]을 제시한다. 두 방법 모두 함께 등장하는 단어가 비슷할수록 비슷한 벡터 값을 가질 것이라는 가정을 전제한다. 또한, 두 방법 모두 window size가 주어지게 되면, 특정 단어를 기준으로 윈도우 내의 주변 단어들을 사용하여 word embedding을 학습하게 된다.
CBOW / Skip-gram
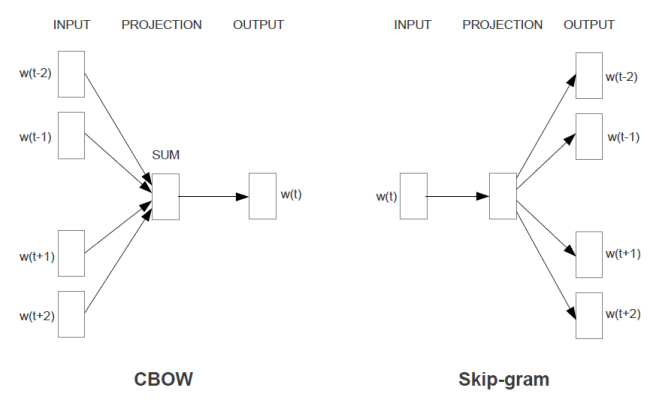
CBOW는 예측 할 단어 주변의 단어들을 one-hot encoded vector로 입력받아 해당 단어를 예측하게 된다.
Skip-gram은 대상 단어를 one-hot encoded vector로 입력으로 받아 주변 단어를 예측하게 된다.
이 두 방법의 차이는 CBOW는 Skip-gram보다 빠르며, 자주 나타나는 단어에 대한 예측 정확도는 높다. 하지만, Skip-gram은 작은 데이터로도 학습이 잘되며, 빈번하지 않은 단어나 구에 대해서도 잘 작동한다고 한다. 일반적으로 skip-gram이 CBOW보다 성능이 뛰어나다고 알려져 있으며, 더 많이 사용되고 있다.
GloVe
Skip-gram은 대상 단어를 통해서 주변 단어를 예측했다면, GloVe[2]는 대상 단어에 대해서 corpus에 함께 나타난 단어별 출현 빈도를 예측하게 한다. Skip-gram은 마지막 layer가 softmax로 구성되어 classification task를 위해 loss function이 MLE로 구성되었다면, GloVe는 출현 빈도를 근사하기에 regression task이고, 이를 위해 loss function은 MSE가 사용된다.
One-hot encoded vector을 입력으로 받아 입력 벡터와 함께 corpus에 출현했던 모든 단어의 동시 출현 빈도를 나타낸 벡터를 output으로 가지게 된다. 이 때, input vector의 출현 빈도가 높거나 또는 prior probability (사전확률)이 크면 loss function이 커지게 된다. 이처럼, 입력의 빈도와 확률에 MSE 값의 크기가 영향을 받게 되므로, 이를 반영하여 손실함수에 빈도에 따른 가중치가 부여되게 된다.
GloVe는 처음에 코퍼스를 통해 단어별 동시 출현 빈도를 조사하여 행렬을 만들고, 해당 행렬을 통해 동시 출현 빈도를 근사하게 된다. 따라서, 학습 과정동안 코퍼스 전체를 훑으며 대상 단어와 주변 단어를 가져와 학습하는 Skip-gram보다 학습이 빠르다. 또한, Skip-gram은 빈번하지 않은 단어에 대해서는 학습 기회가 적지만, GloVe의 경우는 이런 부분이 보완되었다고 한다.
참조
[1][Efficient Estimation of Word Representations in Vector Space](https://arxiv.org/pdf/1301.3781.pdf)
[2][GloVe: Global Vectors for Word Representation](https://www.aclweb.org/anthology/D14-1162.pdf)
