
- 전체보기(104)
- TIL(73)
- Spring(44)
- 트러블슈팅(20)
- 내배캠(17)
- sql(15)
- Java(11)
- JPA(10)
- Springboot(8)
- aws(7)
- kubernetes(6)
- git(4)
- html(4)
- JWT(3)
- websocket(2)
- CSS(2)
- Spring boot(2)
- Railway(2)
- docker(2)
- redis(2)
- Ninety(1)
- SMTP(1)
- CI/CD(1)
- ec2(1)
- Nginx(1)
- mongodb(1)
- jquery(1)
- mysql(1)
- 내배갬(1)
- Vercel(1)
- github(1)
- reactnative(1)
- kafka(1)
- 마이그레이션(1)
- devops(1)
- docker compose(1)
- 채팅(1)
- emmet(1)
- container(1)
- MiniPc(1)
- http(1)
- ubuntu(1)
- linux(1)
- S3(1)
- Thymeleaf(1)
- React(1)
- 정보처리기사(1)
- 개인프로젝트(1)
- 알고리즘(1)
- 서버운영(1)
- 클라우드(1)
Thymeleaf에서 React(Vercel)로 프론트 분리하며 겪은 모든 것
Spring Boot + Thymeleaf 모놀리식 구조에서 React(Vercel) + Spring Boot(Docker) 분리 배포까지, 실전에서 마주한 삽질과 해결 과정을 공유합니다.기존 마이니치 니홍고 프로젝트는 Spring Boot + Thymeleaf로 프론

[Spring] Spring Modulith: MSA가 부담스러울 때 선택한 우아한 모놀리스
"팀 규모는 작은데 코드는 점점 스파게티가 되어간다..." 🍝개발하다 보면 누구나 겪는 딜레마. 모놀리스(Monolith)로 빠르게 시작하긴 했는데, 기능이 늘어날수록 의존성이 뒤엉켜서 '거대한 진흙 덩어리(Big Ball of Mud)'가 되어버린다. 그렇다고 당장

Mini PC에 Ubuntu를 설치하고 Railway에서 마이그레이션해보며 깨달은 점
최근에 Mini PC를 구매해서 직접 Ubuntu를 설치하고, 기존에 Railway에서 운영하던 서비스를 Mini PC로 마이그레이션하는 작업을 진행했다.처음엔 단순히 “클라우드 비용을 아껴보자”는 생각이었는데, 실제로 직접 서버를 구성해보니 예상보다 훨씬 많은 걸 배
TIL - 서브넷과 서브넷 마스크 완벽 정리
정보처리기사 실기 준비 중 서브넷 개념과 문제 풀이 방법을 정리했습니다.서브넷은 하나의 큰 네트워크를 여러 개의 작은 네트워크로 나누는 기술입니다. 이를 통해 네트워크를 효율적으로 관리하고 보안을 강화할 수 있습니다.서브넷 마스크는 IP 주소에서 네트워크 영역과 호스트

Docker Compose 기반 Spring Boot 백엔드, Railway 배포 완전 정복 (Redis/MongoDB/MySQL 포함)
최근 사이드 프로젝트로 Spring Boot 기반의 RESTful API 서버를 개발하고 있었습니다. 로컬 환경에서는 Docker Compose를 활용해 Redis, MongoDB, MySQL을 함께 운영하며 개발을 진행했는데, 배포 단계에서 고민이 많았습니다.AWS
Ninety 프로젝트에서 게임 리소스 관리 방식 고민하기
프로젝트 소개 최근에 Ninety라는 습관 트래킹 앱에 간단한 게임 요소를 추가하는 작업을 했다. 방 꾸미기와 펫 수집/육성 기능을 넣어서 사용자들이 습관을 달성할 때마다 재미를 느낄 수 있도록 만들었다. 처음에는 단순하게 시작했지만, 게임 요소가 들어가면서 여러 가

JPA JOIN FETCH 와 Optional 조합 시 발생하는 NonUniqueResult 오류 해결
Spring Boot 프로젝트에서 날짜별 콘텐츠를 조회하는 기능을 구현하던 중, 다음과 같은 오류가 발생했다.처음에는 동일한 날짜에 여러 개의 레코드가 존재하는 것으로 생각했다. 하지만 MySQL에서 직접 쿼리를 실행해보니 예상과 달랐다.MySQL에서는 1개의 결과만

대규모 이메일 발송 테스트 중 겪은 커넥션 누수 문제 해결하기
Spring Boot로 운영 중인 프로젝트에서 대규모 이메일 발송 성능 테스트를 수행하다가, 두 가지 문제를 겪고 원인 분석 및 해결까지 진행한 경험을 공유합니다. 배경 프로젝트에 구독자에게 일본어 학습 이메일을 매일 발송하는 기능이 있습니다. 실제로 수천 명의 유저

TIL - Spring Boot에서 동시성 제어 : 언제 무엇을 써야 할까?
예전에 Lock에 대해 공부하면서 동시성 제어라는 말을 접했었다. 하지만 동시성 제어를 할 수 있는 방법으로는 많은 방법이 있고 어떤 상황에 어떻게 대처해야 될지 의문점이 생겨 공부한 내용을 정리해 보려고한다.동시성 문제는 실제 서비스에서 생각보다 흔하게 발생한다. 특
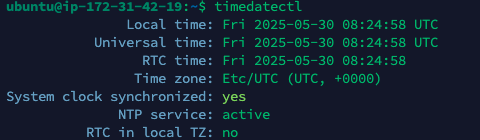
EC2 환경에서 Spring Boot 크론잡(@Scheduled)이 실행되지 않을 때 체크할 것!
로컬에서는 정상 작동하던 크론잡이 EC2 서버에서는 정상적으로 실행되지 않았다.크론잡(@Scheduled)은 서버 시간대(Timezone)를 기준으로 작동한다.로컬은 'Asia/Seoul', EC2는 'UTC' 시간대를 사용하고 있었다. 즉, 크론 표현식 기준 시간이

트러블슈팅 - 크로스 플랫폼 배포 시 HttpOnly RefreshToken이 전달되지 않는 문제
현재 GiSync라는 인디밴드 커뮤니티 웹 어플리케이션을 개발하고 있다.프론트엔드 : Vite + React (localhost:5173)백엔드 : Spring Boot (localhost:8080)인증 방식 : JWT + Refresh Token (HttpOnly C

Kafka와 WebSocket을 이용한 채팅 시스템 구현 & 구현 중 발생한 문제점들
Apache Kafka는 분산 스트리밍 플랫폼으로 대용량의 데이터를 빠르고 안정적으로 처리할 수 있는 메시지 브로커 시스템이다. 기본적인 구성 요소는 다음과 같다.Producer : 메시지를 발행하는 주체Broker : 메시지를 저장하고 관리하는 Kafka 서버Topi

트러블슈팅 - HttpOnly Refresh Token이 로컬 개발 환경에서 쿠키에 안 보이는 문제
Spring Boot + JWT 인증 구조에서 로그인 시 refreshToken을 HttpOnly 쿠키에 담아 응답하도록 설정했다.그러나 로컬에서 http://localhost로 서버를 실행했을 때, 브라우저에 쿠키가 저장되지 않았다.쿠키 설정에서 아래 두 옵

TIL - JWT + Spring Security + Redis 기반 로그아웃 처리 방식
오늘은 Spring Boot에서 JWT 인증 방식을 사용하는 환경에서 Redis를 활용한 로그아웃 처리 및 Refresh Token 관리에 대해 정리했다. 구현하며 느꼈던 포인트들과 코드 중심으로 정리해본다.JWT는 서버에 세션을 저장하지 않는 Stateless 방식이
트러블슈팅 - S3에 업로드한 이미지가 다운로드만 뜨는 문제 해결하기
Spring Boot에서 게시글 생성 시 파일(이미지, 동영상)을 첨부해 AWS S3에 업로드하도록 구현했다.하지만 Postman으로 테스트하던 중 다음과 같은 에러가 발생했다.파일 업로드 자체가 실패했고, 이후 S3 버킷을 확인해도 업로드된 파일은 applicatio

TIL - Kubernetes 스터디 내용 정리 5 (Pod 오토스케일링, 배포 전략)
HPA는 애플리케이션의 리소스 사용량(CPU, 메모리 등)을 기준으로 Pod 수를 자동으로 조절하는 오브젝트이다.일반적으로 Deployment, ReplicaSet, StatefulSet에 적용 가능하다.리소스 사용량을 기반으로, 정의된 임계치를 넘기면 Pod의 수를

TIL - Kubernetes 스터디 내용 정리 4 (Persistent Volume, StatefulSet, Job/CronJob)
쿠버네티스에서 Persistent Volume(PV)는 클러스터에서 관리하는 스토리지 리소스이고, Persistent Volume Claim(PVC)는 사용자가 해당 스토리지를 요청하는 방식이다.Persistent Volume(PV)관리자가 설정한 정적인 스토리지 리소

TIL - Kubernetes 스터디 내용 정리 3 (Service, Ingress, Deployment)
kubernetes에서 Pod는 동적으로 생성되고 사라지므로, 특정 Pod의 IP 주소는 고정되지 않는다. 따라서 안정적인 네트워크 통신을 위해 Service가 필요하다.ClusterIP (기본값)클러스터 내부에서만 접근 가능한 서비스kubectl expose depl
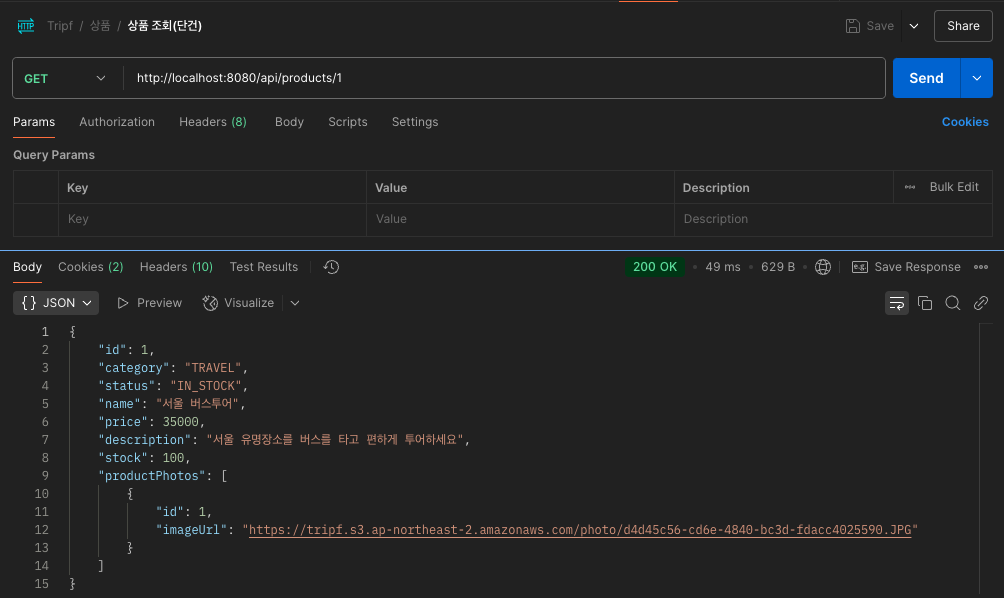
Spring Boot JPA에서 LOB필드 조회 시 JpaSystemException 발생 해결
Spring Boot + JPA 환경에서 상품 단건 조회 API를 호출했을 때 다음과 같은 예외가 발생했다.문제가 된 코드Product 엔티티는 @Lob 타입의 description 필드를 포함하고 있음ProductPhoto 엔티티와 @OneToMany 관계를 맺고 있
Kubernetes 유용한 명령어 정리
| 명령어 | 설명 | |------------|----------| | aws eks --region update-kubeconfig --name | EKS 클러스터와 로컬 kubectl을 연결 | | kubectl get nodes | 클러스터의 노드 상태 확인