[Recommender System] Contents Based Filtering : 콘텐츠 기반 필터링 _ 유사도함수와 TF - IDF
Recommender_System

이번에는 콘텐츠 기반 필터링에 대해 더 자세히 개념을 알아보도록 한다.
1. Similarity Metrics : 유사도 함수란?
Contents Based Filtering은 비슷한 정도를 나타내는 지표인 유사도를 활용한 유사도 함수를 통해 추천을 진행한다. 따라서 어떠한 유사도 함수를 사용하는지 살펴보도록 한다.
2. 대표적인 유사도 함수 종류
대표적으로 사용하는 것은 총 4가지인데 크게 두가지 종류로 나뉠 수 있다.
- 거리 기반 유사도
: 좌표를 기준으로 가까운 위치에 있는 점들의 유사도가 높아지도록 측정- 예시 ) 유클리디안 유사도
- 각도 기반 유사도
: 좌표를 기준으로 방향이 비슷한 점들의 유사도가 높아지도록 측정- 예시 ) 코사인 유사도, 피어슨 유사도, 자카드 유사도
1) Euclidean Similarity ; 유클리디안 유사도
- 유클리디안 거리의 역수로 정의
- 유클리디안 수식
-
예시
Item A Item B Item C Item D User A 1 0 1 0 User B 0 1 1 0 User C 1 0 1 1 이와 같은 유저 아이템 선호 행렬이 있다고 했을 때, 유저 A와 유저 B의 유클리디안 거리는 다음과 같다.
따라서 유저 A와 B의 유클리디안 유사도는 이다.
이와 같은 방식으로 모든 행렬에 대한 값을 구하면 다음과 같은 Matrix를 얻을 수 있다.유저별 유클리디안 유사도User A User B User C User A ∞ 0.707 1 User B 0.707 ∞ 0.578 User C 1 0.578 ∞ ☁️ ∞ 표시 : 동일한 유저에 대해서는 거리가 0이기 때문에 무한대로 표시한다.
=> 유사한 유저 : 유저 A와 유저 C🖥
Coding Time
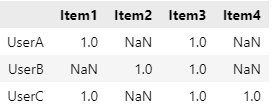
위와 같은 행렬이 있다고할 때 가장 먼저 해야하는 것은 결측치를 제거하는 것이다.이후 sklearn.metrics.pairwise의 euclidean_distance를 이용해 유클리디안 유사도를 구한다.
# 결측치 제거
df = df.fillna(0)
# 결측치 값을 다 0으로 채움 (이후 유사도를 계산하기 위해서는 결측치가 없어야 한다.)
#euclidean_distances에 X와 Y를 입력할 경우, X와 Y의 각 Row끼리 유클리디안 거리를 계산.
# 위에서 수식으로 계산한 유저 A와 B의 유사도를 구하기 위해 X와 Y에 각각 유저 A와 B의 컬럼을 입력하면 두 유저의 유클리디안 거리를 계산할 수 있다.
from sklearn.metrics.pairwise import euclidean_distances
euclidean_distances(X=df.loc[['UserA']],
Y=df.loc[['UserB']])
# euclidean_distances에 X만 입력할 경우, X의 모든 Row사이의 유클리디안 거리를 계산한다.
# 전체 데이터를 입력할 경우 모든 유저 사이의 유클리디안 거리를 계산할 수 있으며 위에서 보았던 전체 유저별 유클리디안 거리의 array형태를 결과로 반환한다.
euclidean_distances(df)
# 역수를 취해 최종적인 유클리디안 유사도를 구한다.
distance = euclidean_distances(df)
similarity = 1 / (distance + 1e-5)
similarity- euclidearn_distances(df)의 결과

2) Cosine Similarity : 코사인 유사도
-
두 벡터 간의 코사인 각도를 이용해 계산
-
코사인 수식
-
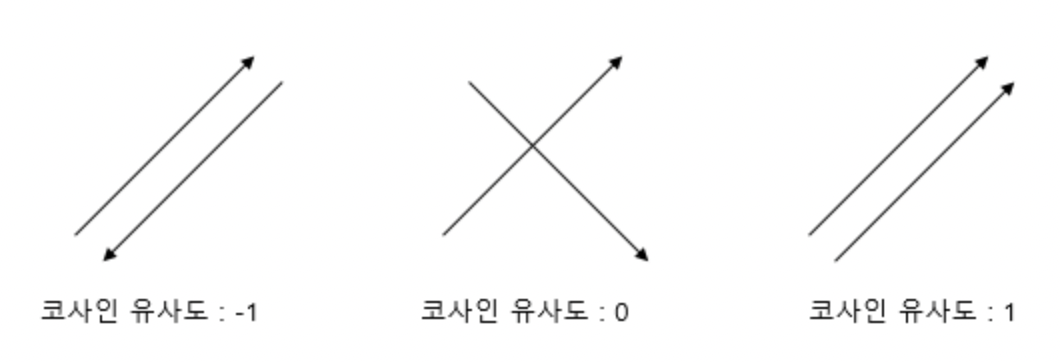
-1과 1 사이의 값으로 계산되며, 방향이 같은 경우 1이며 반대일 경우 -1의 값을 갖는다.
-
예시
Item A Item B Item C Item D User A 1 0 1 0 User B 0 1 1 0 User C 1 0 1 1 앞선 예시와 동일한 유저 아이템 선호 행렬이 있다고 할 때 ||A|| 와 ||B||의 값은 다음과 같다.
의 값은 이므로
유저 A와 유저B의 코사인 유사도는 이다.유저별 코사인 유사도User A User B User C User A 1 0.5 0.816 User B 0.5 1 0.408 User C 0.816 0.408 1 => 유사한 유저 : 유저 A와 유저 C
🖥
Coding Time
# 유클리디안 유사도를 구했던 방식과 동일하다.
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(
X=df.loc[["UserA"]],
Y=df.loc[["UserB"]],
)
cosine_similarity(df)3) 피어슨 유사도
두 벡터의 상관계수로 정의하여 유저 또는 아이템 별로 가지는 특성을 제거
4) 자카드 유사도
유저가 상호작용한 아이템의 합집합과 교집합의 비율로 계산
2. TF - IDF란?
- Term Frequency - Inverse Document Frequency
- 텍스트 기반의 컨텐츠의 특징 벡터를 추출하는 방법
- 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용해 각 단어들마다 중요한 정도를 가중치로 주는 방법
- 출현 빈도를 이용해 특정 문서 (d) 내에서 키워드(w)의 중요도를 측정
- 자주 등장하는 키워드는 낮은 중요도를 부여
- TF - IDF 수식✏️ TF - IDF 용어 정리
- TF : 특정 문서 내에 특정 키워드가 등장하는 빈도
- TF(w,d) = 문서 d에 속한 키워드 w의 수
- DF : 전체 문서 내에 특정 키워드가 등장하는 빈도
- DF가 큰 경우 보편적인 키워드임.
- IDF : DF의 역수
-
☁️ 를 씌우는 이유 > 값이 클 경우에 작은 값을 갖게 되기에 log를 씌워 스케일링을 한다. log를 사용하지 않았을 때, IDF를 DF의 역수만으로 사용한다면 총 문서의 수 n이 커질 수록, IDF의 값은 기하급수적으로 커지게 됩니다. 그렇기 때문에 log를 사용한다.
-
- TF : 특정 문서 내에 특정 키워드가 등장하는 빈도
