[Recommender System] Contents Based Filtering : 콘텐츠 기반 필터링 _ 영화데이터로 추천시스템 실습
Recommender_System

** 데이터는 캐글의 Movie data 이용
https://www.kaggle.com/rounakbanik/the-movies-dataset
1. 데이터 탐색
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from ast import literal_eval
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
data = pd.read_csv('./data/kaggle_movie/movies_metadata.csv')
data.head()
data.shape # (45466, 24)
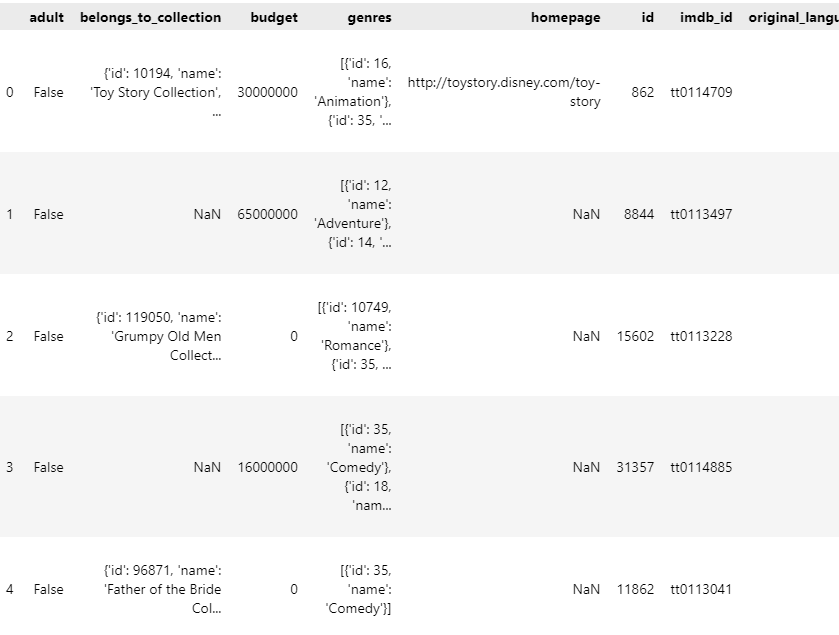
movies_metadata.csv의 경우 24개의 컬럼에 대해 영화에 대한 예산, 장르, id 등의 정보를 담고 있다.
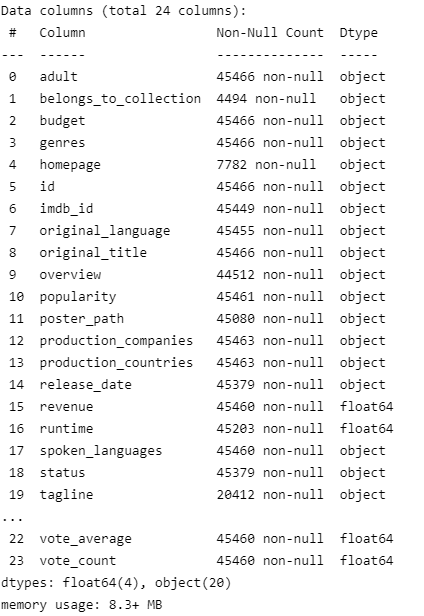
info를 확인해보면 숫자로만 구성되어 있는 column에 대해서도 object형으로 데이터타입이 설정되어 있는 것을 알 수 있다. 해당 예제에서는 다른 데이터프레임과의 결합이 필요하므로 이를 위해 우선적으로 필요 column에 대해 형 변환을 진행하도록 한다.
그전에 아래와 같은 형태의 데이터는 형변환이 안되며 잘못 들어간 데이터이므로 삭제처리한다.
# - 문자열을 가진 행 탐색
data[data['id'].str.contains('-')]
# 앞서 언급한 - 이 들어간 행 3개 삭제
data.drop([35587,19730,29503], axis=0, inplace=True)
# 형변환
data['id'] = data['id'].astype('int')영화에 대한 키워드 데이터가 필요한데, 이는 keyword.csv에 있다.
keyW = pd.read_csv('./data/kaggle_movie/keywords.csv')
keyW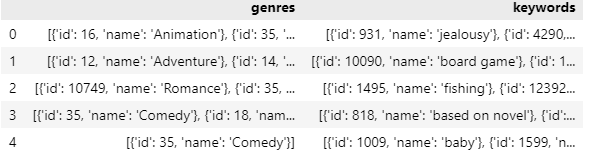
영화 id를 기준으로 데이터프레임을 merge한다.
# keyword data와 movie data 연결시키기 (by id)
data = pd.merge(data, keyW, on='id')
data.shape # (46482, 25) 주요 컬럼에 대한 설명은 다음과 같다.
- genres : 영화 장르
- keywords : 영화의 키워드
- original_language : 영화 언어
- title : 제목
- vote_average : 평점 평균
- vote_count : 평점 카운트
- popularity : 인기도
- overview : 개요 설명
2. Precprocessing (전처리)
# 사용할 컬럼들 먼저 뽑아주기
data = data[['id','genres','vote_average','vote_count','title','keywords','overview','original_language']]1) Vote Average값 변경해주기
많은 사람이 평가할 수록 평점이 5점(만점)이 될 확률은 낮다. 따라서 평점이 많은 영화에 대해서는 높은 평점을 받는 것이 어렵기에 불공평해진다. 따라서 이를 방지하기 위한 전처리가 필요하다.
- R = 개별 영화 평점
- V = 개별 영화에 평점을 투표한 횟수
- m = Top n위 안에 들어야 하는 최소 투표 (사용자 지정)
- c = 전체 영화에 대한 평균 평점
# 여기서 m은 460으로 가정하여 진행.
# 전체 데이터가 약 4만 6천개이므로 0.01%정도가 이에 속함.
tmp_m = data['vote_count'].quantile(0.99)
tmp_data = data.copy().loc[data['vote_count'] >= tmp_m]
tmp_data.shape # (465, 8)
# 상위 1% 가정하여 진행
del tmp_data
m = data['vote_count'].quantile(0.99)
c = data['vote_average'].mean()
# 앞서 살펴본 weighted rating의 수식을 구현하기 위한 함수
def weighted_rating(x, m=m, c=c):
v = x['vote_count']
R = x['vote_average']
return (v / (v + m) * R) + (m / (m + v) * c)
# 위의 수식을 적용한 값인 score 컬럼 생성
data['score'] = data.apply(weighted_rating, axis = 1)
# 각 행이 x로 들어가고 각 행에 대한 컬럼 값을 v와 R로 받아와 값을 계산함.2) Genres, Keywords 변환
genres, keyword 컬럼을 보면 리스트 안의 딕셔러니 구조가 object 데이터타입으로 데이터가 구성되어있다. 우리가 원하는 각각 장르와 키워드에 있는 name의 value값이므로 이 값들만 가져오는 처리를 하도록 한다.
# ast 내의 literal_eval 패키지 이용 -> list와 dic 형태로 변환된다.
data['genres'] = data['genres'].apply(literal_eval)
data['keywords'] = data['keywords'].apply(literal_eval)그 후 각 컬럼에 대해 원하는 값만 가져온다.
# id를 제거한 후 name만 뽑아내면 된다. (장르가 무엇인지, 키워드가 무엇인지가 중요하므로 )
data['genres'] = data['genres'].apply (lambda x: [d['name'] for d in x]).apply(lambda x : " ".join(x))
data['keywords'] = data['keywords'].apply(lambda x : [d['name'] for d in x]).apply(lambda x : " ".join(x))
# 데이터 저장
data.to_csv('./data/kaggle_movie/main_data.csv', index=False)- 위 코드에 대한 작동을 생각해보면 x는 data['genres']이고 d는 리스트 내 하나의 딕셔너리 데이터를 의미하는 듯하다.
3. Content Based Filtering
콘텐츠 기반 필터링은 비슷한 콘텐츠를 사용자에게 추천하는 것이다. 해당 데이터에서는 '장르'를 이용해 추천 시스템을 진행해보도록 한다.
1) TF - IDF 벡터화
movie_data = pd.read_csv('./data/kaggle_movie/main_data.csv')
movie_data = movie_data.loc[movie_data['original_language'] == 'en', :]
movie_data = movie_data[['id','title','original_language','genres']]
print(movie_data.shape)
movie_data.head()
movie_data.isnull().sum()
# null 데이터가 있으면 벡터화가 안되므로 전부 삭제 처리
movie_data.dropna(axis=0, inplace = True)
TF - IDF는 TF와 IDF를 곱한 값을 의미하는 데, 문서를 d, 단어를 t, 문서의 총 개수를 n이라고 표현할 때 다음과 같이 정의 가능하다.
- TF(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
- DF(t) : 특정 단어 t가 등장한 문서의 수
- IDF(d,t) : df(t)에 반비례하는 수
tfidf_vector = TfidfVectorizer()
# 장르와 키워드를 하나로 합친 후 tf-idf 벡터로 만들어 줌.
tfidf_matrix = tfidf_vector.fit_transform(movie_data['genres'] + " " + movie_data['keywords']).toarray()
tfidf_matrix_feature = tfidf_vector.get_feature_names()
tfidf_matrix.shape # (32170, 11429)
# shape = (train 문장 수 , 사전의 단어 수)
# 장르와 키워드를 하나의 문장으로 합쳤기때문에 이는 하나의 row가 하나의 문장으로 들어간 것과 같다.
# 따라서 32170개의 행(=문장)과 11429개의 단어로 이루어진 matrix가 생성된다.
# 이는 32,170개의 영화를 표현하기 위해서 총 11,429개의 단어가 사용되었음을 의미
tfidf_df = pd.DataFrame(tfidf_matrix, columns = tfidf_matrix_feature, index = movie_data.title)
print(tfidf_df.shape)
tfidf_df.head()
# 각 row는 한 영화에 대한 정보를 나타내므로 영화 타이틀을 인덱스로 가져온다.
2) 유사도 구하기
%%time
# 코사인 유사도 사용 - 영화 개수(n)만큼 n x n matrix 형태의 output
cosine_sim = cosine_similarity(tfidf_df)
cosine_sim.shape # (32170, 32170)
cosine_sim_df = pd.DataFrame(cosine_sim, index = movie_data.title, columns = movie_data.title)
print(cosine_sim_df)
cosine_sim_df.head()
3) Content Based Recommend
-
target title : 추천 결과를 조회할 영화 제목에 따라서 코사인 유사도를 구한 matrix에서 유사도 데이터를 가져온다.
-
유사도 데이터 중 가장 유사도 값이 큰 데이터를 가져온다. (top K개)
-
해당 추천 값 출력
cosine_sim_df.loc[:,'The Dark Knight Rises'].values.reshape(1,-1).argsort()[:,::-1].flatten()[1:10+1]
# 추천시스템 구현 함수
def genre_recommendations(target_title, matrix, items, k=10):
recom_idx = matrix.loc[:, target_title].values.reshape(1,-1).argsort()[:, ::-1].flatten()[1:k+1]
recom_title = items.iloc[recom_idx, :].title.values
recom_genre = items.iloc[recom_idx, :].genres.values
target_title_list = np.full(len(range(k)), target_title)
target_genre_list = np.full(len(range(k)), items[items.title == target_title].genres.values)
d = {
'target_title' : target_title_list,
'target_genre' : target_genre_list,
'recom_title' : recom_title,
'recom_genre' : recom_genre
}
return pd.DataFrame(d)
genre_recommendations('The Dark Knight Rises', cosine_sim_df, movie_data)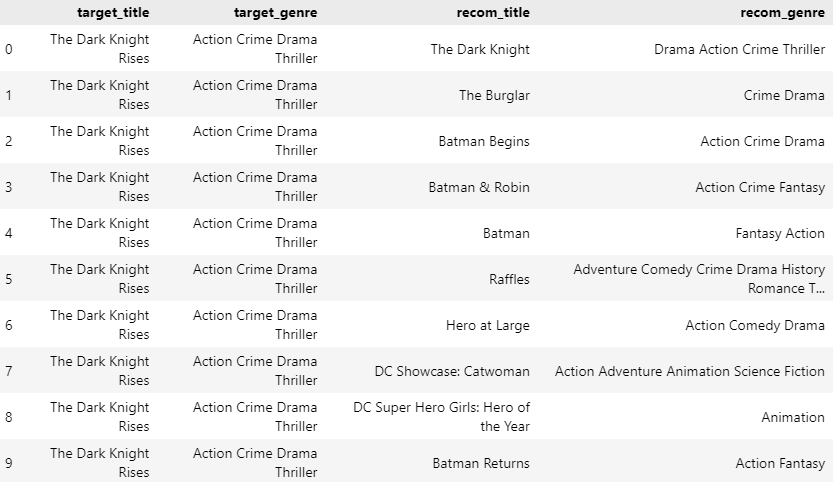
위 사진과 같이 사용자가 지정한 K(10)개에 대한 The Dark Kniht Rises와 관련된 영화를 추천해주는 시스템을 구현했다.
여기를 참조하여 해당 코드 실습을 진행했습니다.
