도수 정렬
도수 정렬이란?
도수 정렬은 요소의 대소 관계를 판단하지 않고 빠르게 정렬할 수 있는 알고리즘입니다. 요소의 출현 빈도(도수)를 기준으로 정렬하는 방법입니다. 각 요소가 몇 번 출현하는지를 셉니다. 그리고 출현 빈도를 누적해서 더해가면서 정렬 결과를 도출합니다.
도수 정렬은 요소를 비교할 필요가 없다는 특징을 가지며 4단계로 이루어 집니다.
동작 과정
- 도수분포표 만들기
- 누적도수분포표 만들기
- 목적 배열 만들기
- 배열 복사하기
특징
- 선택, 삽입, 퀵, 병합, 힙 정렬과 다르게 키 값의 비교가 불필요함
- 크기를 기준으로 개수만 세주어 위치를 바꿀 필요가 없음
- 모든 데이터에 한 번씩만 접근하여 되게 효율적
- 범위 조건이 있는 경우에 한해서 굉장히 빠름
장단점
장점
- 데이터의 비교, 교환 작업이 없어 매우 빠름
- 단일 for문만을 사용하여, 재귀 호출, 이중 for문 없어 매우 효율적
- 범위 조건이 있는 경우 시간복잡도 O(n) / 공간 복잡도 O(n), n = 배열의 최대값 - 최솟값
- 안정적인 알고리즘
단점
- 최솟값, 최댓값 미리 알고 있는 경우에만 사용 가능
- 최소값 최댓값 차에 의해 시간 공간 제약
- 데이터 타입이 일정해야 한다.
코드
동작 관련해서 자세한 내용은 코드를 통해서 살펴볼 수 있습니다.
void fSort(int[] a, int n, int max) {
int[] f = new int[max + 1];
int[] b = new int[n];
for(int i = 0; i < n; i++) f[a[i]]++; // 1단계: 도수분포표 만들기
for(int i = 1; i <= max; i++) f[i] += f[i - 1]; // 2단게: 누적도수분포표 만들기
for(int i = n - 1; i >= 0; i--) b[--f[a[i]]] = a[i]; // 3단게: 목적 배열 만들기
for(int i = 0; i < n; i++) a[i] = b[i]; // 4단계: 배열 복사하기
}코드가 굉장히 간단한 것을 확인할 수 있습니다.
먼저, 1단계로 0 ~ n까지 배열안의 요소들의 값을 Index로 갖는 f[] 배열에서 counting하면서 도수분포표를 만들어 줍니다.
2단계로 1단계에서 도수분포표를 만들었으니 ‘0부터 max 값을 가지는 요소까지 몇 개의 요소가 있는지’ 누적된 값을 나타내는 누적도수분포표를 만들어 줍니다.
3단계에서는 배열의 각 요솟값과 누적도수분포표 f를 대조하여 정렬을 마친 배열을 만드는 작업입니다. 이때, 중요한 점은 안정적인 정렬을 위해서 뒤에서부터 앞으로 스캔하면서 대조하는 작업을 수행합니다.
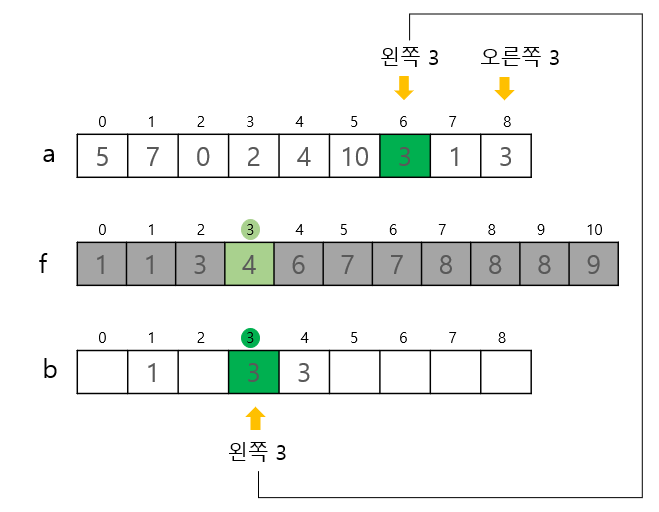
사진을 통해 예를 들어 설명하자면, 뒤에서부터 앞으로 스캔하기 때문에 오른쪽 3의 경우 Index 4에 배정받고 이후 앞으로 진행하면서 왼쪽 3을 마주칠 것입니다. 앞서 f[] 배열에서 Index 3의 value를 하나 낮춰났기 때문에 오른쪽 3 의 바로 앞에 정렬될 것입니다.
4단계에서는 이미 정렬이 완료된 배열을 다시 원래 배열인 a로 복사하는 것으로 마무리가 됩니다.
시간 복잡도
Reference

개발정리블로그