자료구조와 알고리즘
1.자료구조 와 알고리즘
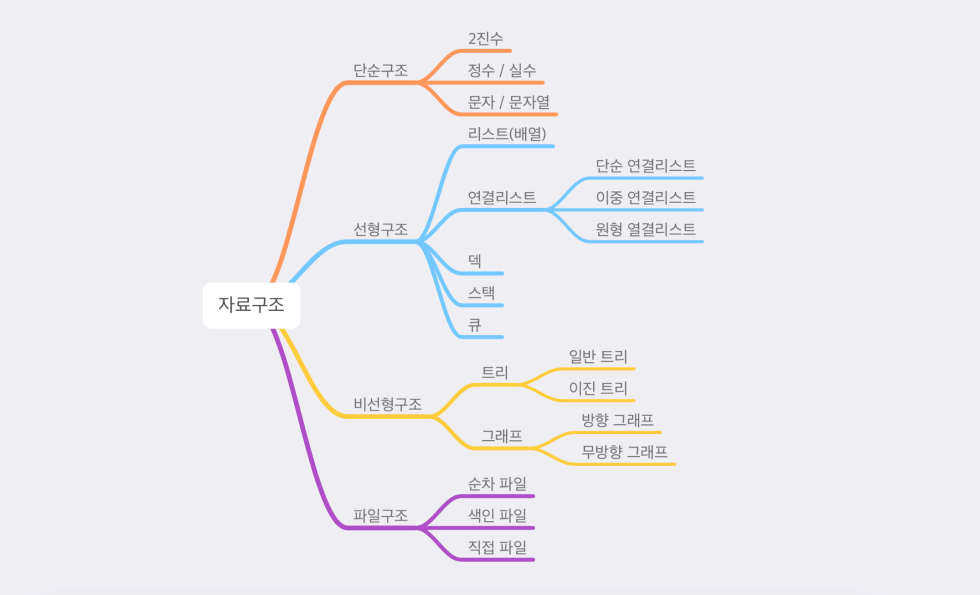
자료구조란 여러 데이터들의 묶음을 저장하고, 사용하는 방법을 정의한 것입니다.
2.탐색

탐색이란 다시 말해서 “데이터를 찾는 방법”을 의미한다. 대표적인 예로는 순차 탐색과 이진 탐색을 예로 들 수 있습니다.
3.정렬
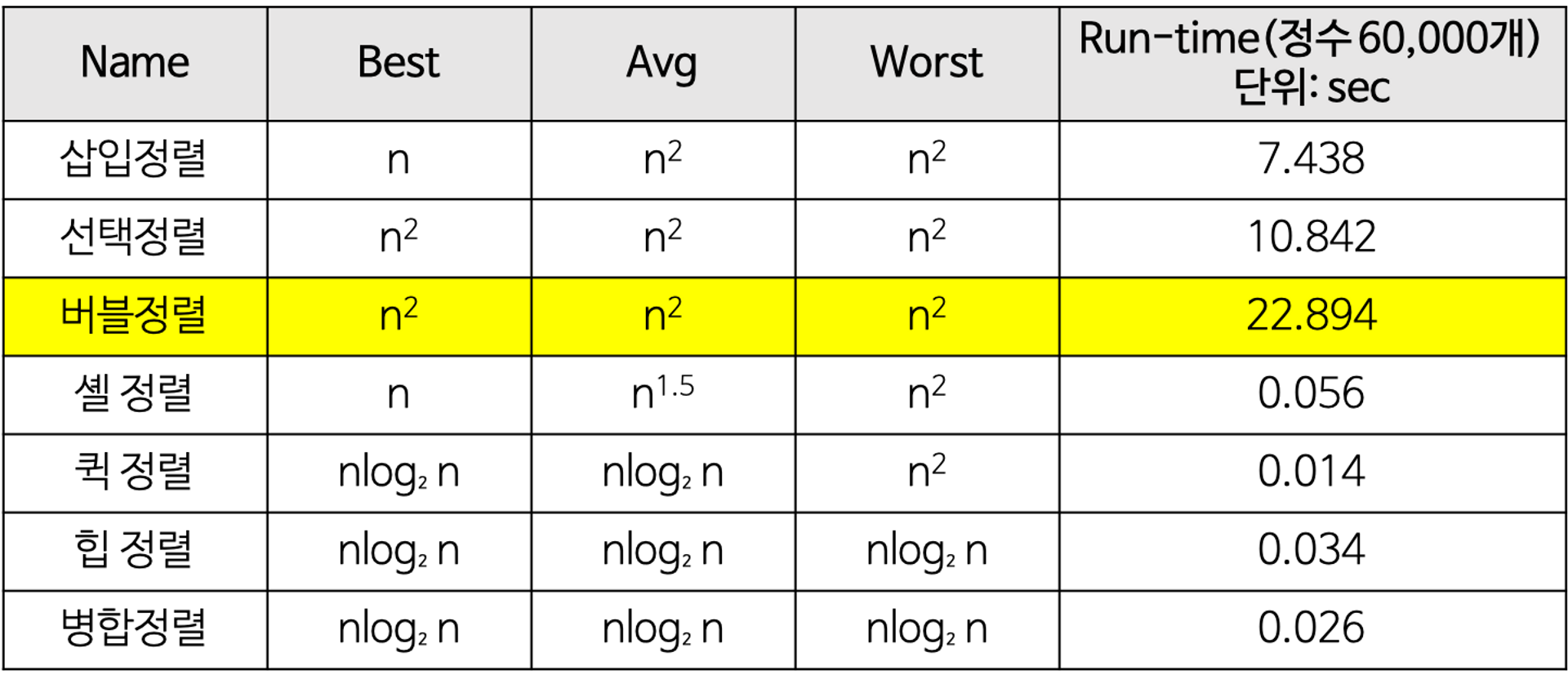
정렬(Sorting)은 이름, 학번, 키등 핵심 항목(key)의 대소 관계에 따라 데이터 집합을 일정한 순서로 줄지어 늘어서도록 바꾸는 작업을 말합니다.
4.문자열 검색
문자열 검색이란? 문자열 검색이란 어떤 문자열 안에 다른 문자열이 들어 있는지 조사하고 들어 있다면 그 위치를 찾아내는 것을 말합니다.
5.트리
트리는 노드로 이루어진 자료구조로서 노드들이 나무 가지처럼 연결된 비선형 계층적 자료구조입니다.
6.[JAVA] 다이나믹 프로그래밍
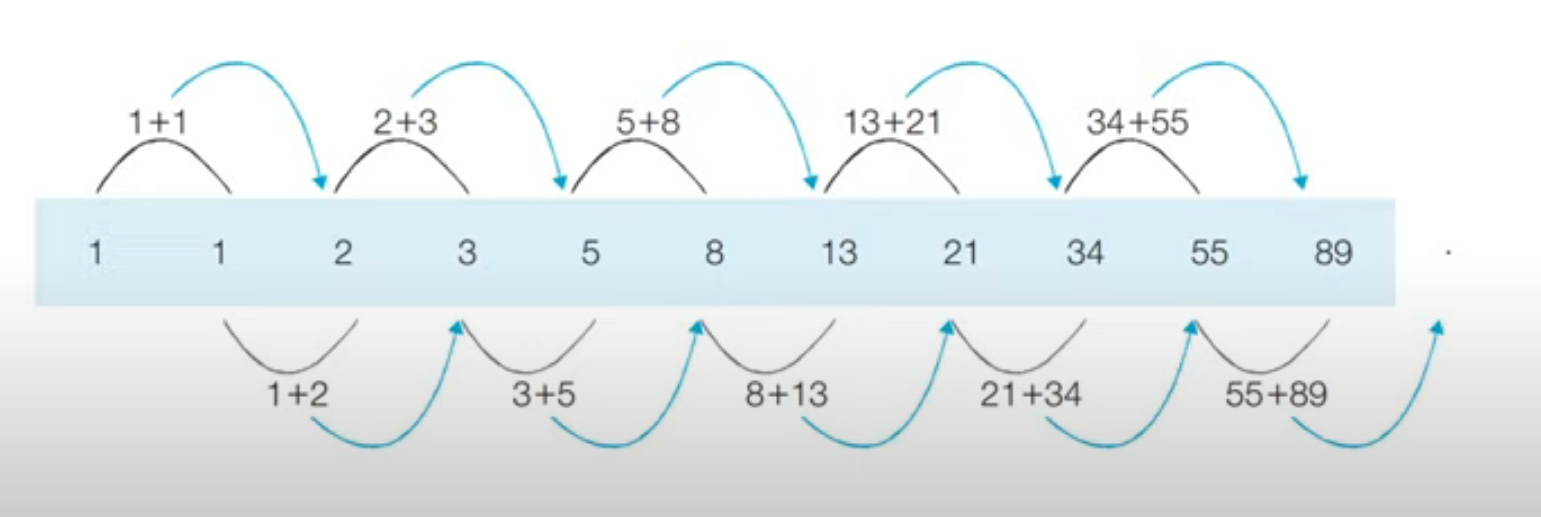
다이나믹 프로그래밍은 메모리르 적절히 사용하여 수행 식이나 효율성을 비약적으로 향상시키는 방법입니다.
7.[Java] DFS & BFS
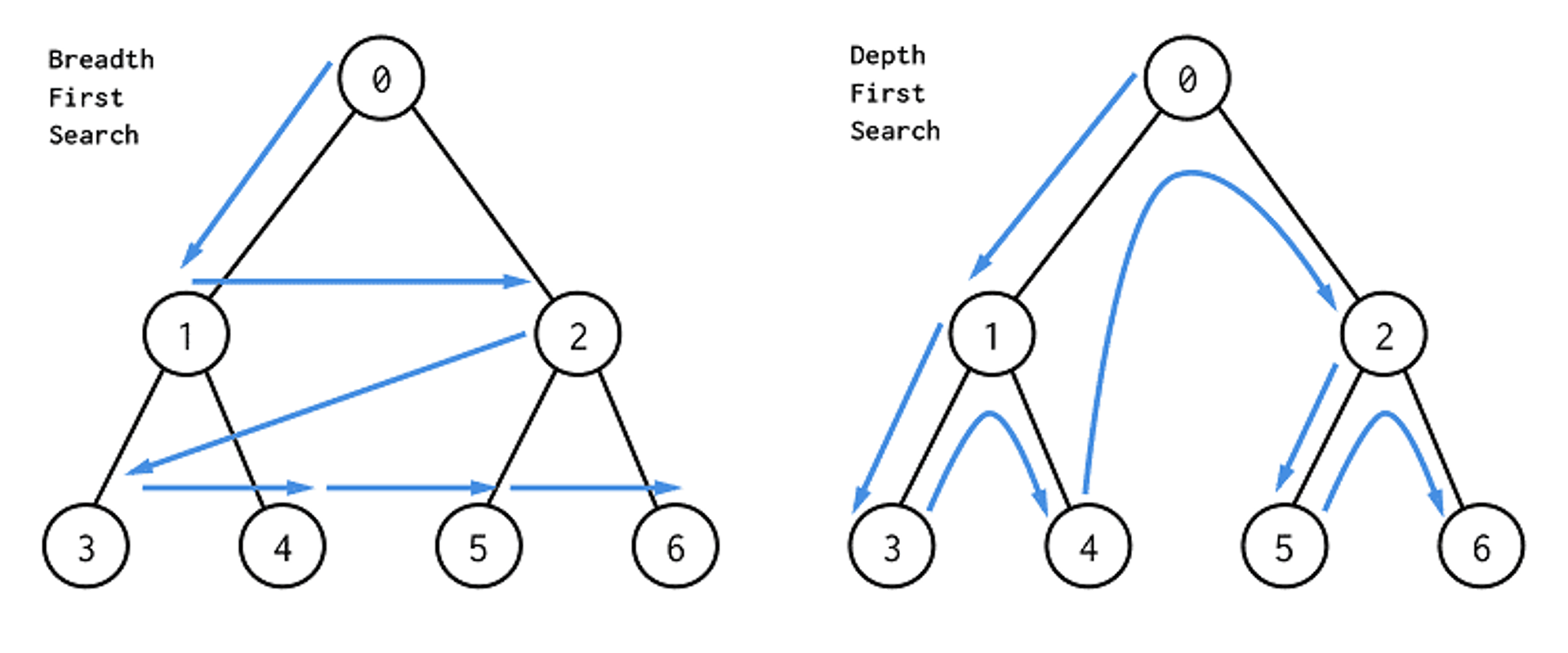
DFS는 깊이 우선 탐색으로, 한 노드에서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방식을 말합니다 BFS는 너비 우선 탐색으로, 특정 노드에서 탐색을 시작하여 같은 레벨에 있는 모든 노드를 탐색한 후 다음 하위 레벨로 내려가 탐색을 진행하는 방식입니다
8.[Java] 다익스트라(Dijkstra Algorithm)
음의 가중치가 없는 그래프에서 여러 개의 노드가 있을 때, 특정한 한 정점(=노드)에서 출발하여 다른 모든 정점으로 가는 최단 경로를 구하는 알고리즘입니다.
9.[Java] 벨만 포드(Bellman-Ford Algorithm)
다익스트라 알고리즘과 같이 최단 경로(Shortest Path)를 찾는 대표적인 기법 가운데 하나인 벨만 포드 알고르즘에 대해서 정리하겠습니다.
10.[Java] 플로이드 워셜(Floyd-Warshall Algorithm)
플로이드-워셜 알고리즘은 음수 사이클이 없는 그래프내의 각 모든 정점에서 각 모든 정점에 까지의 최단 거리를 모두 구할 수 있는 알고리즘입니다.
11.SPFA
SPFA(Shortest Path Faster Algorithm)의 경우 벨만-포드 알고리즘의 성능을 향상시킨 알고리즘으로서, 방향 가중치 그래프에서 단일 출발 정점 최단 거리를 계산합니다.
12.[Java] 버블 정렬(Bubble Sort)
서로 인접한 두 원소를 검사하여 정렬하는 알고리즘으로 크기를 비교하여 순서대로 되어 있지 않으면 서로 교환하는 방식을 가진다.
13.[Java] 단순 선택 정렬, 단순 삽입 정렬(Straight Selective Sort, Insertion Sort)
단순 선택 정렬 알고리즘은 가장 작은 요소부터 선택해 알맞은 위치로 옮겨서 순서대로 정렬하는 알고리즘입니다.단순 삽입 정렬(Straight Insertion Sort)은 선택한 요소를 그보다 더 앞쪽의 알맞은 위치에 삽입하는 작업을 반복하여 정렬하는 알고리즘입니다.
14.[Java] 셸 정렬(Shell Sort)
셸 정렬은 단순 삽입 정렬의 장점은 살리고 단점은 보완하여 좀 더 빠르게 정렬하는 알고리즘입니다.
15.[Java] 퀵 정렬(Quick Sort)
퀵 정렬은 일반적으로 사용되고 있는 아주 빠른 정렬 알고리즘입니다. 퀵 정렬은 분할 정복(divide and conquer) 방법을 통해 리스트를 정렬합니다.
16.[Java] 병합 정렬(Merge Sort)
분할 정렬은 배열을 반으로 나눈 다음, 각 부분에서 재귀적으로 정렬을 수행하는 정렬 알고리즘입니다.
17.[Java] 힙 정렬(Heap Sort)
힙 정렬(heap sort)는 힙(heap)을 사용하여 정렬하는 알고리즘입니다. 힙은 "부모의 값이 자식의 값보다 항상 크다(작다)"라는 조건을 만족하는 완전이진트리입니다.
18.[Java] 도수 정렬(Counting Sort)
도수 정렬은 요소의 대소 관계를 판단하지 않고 빠르게 정렬할 수 있는 알고리즘입니다. 요소의 출현 빈도(도수)를 기준으로 정렬하는 방법입니다.
19.[Java] 트라이(Trie)
트라이(Trie)는 문자열의 집합을 표현하는 트리 자료구조입니다.
20.[Java] 라빈 카프(Rabin-Karp)
라빈 카프(Rabin-Karp) 알고리즘은 특이한 문자열 매칭 알고리즘입니다. 항상 빠르지는 않지만 일반적인 경우 빠르게 작동하는 간단한 문자열 매칭 알고리즘이라는 점에서 자주 사용됩니다.
21.[Java] KMP
브루트-포스법에서는 다른 문자를 만나면 패턴에서 검사했던 위치 결과를 버리고 다음 텍스트의 위치로 1칸 이동한 다음 재검사를 했습니다. 하지만, 이것은 비효율적입니다. 그래서 KMP법은 검사했던 위치 결과를 버리지 않고 이를 효율적으로 활용하는 알고리즘입니다.
22.[Java] 보이어-모어(Boyer-Moore)
Boyer-Moore법은 브루트-포스법을 개선한 KMP법보다 효율이 더 우수하기 때문에 실제로 문자열 검색에서 널리 사용하는 알고리즘입니다.
23.[Java] 이진 트리(Binary Tree) + 이진 탐색 트리(Binary Search Tree)
이진 트리(Binary Tree)는 자식 노드가 최대 두개인 노드들로 구성된 트리를 의미합니다.
24.[Java] 이진 힙(Heap)
완전 이진 트리의 일종을 우선순위 큐를 위하여 만들어진 자료구조입니다.여기서, 우선순위 큐를 위해서 만들어졌다고 했는데, 우선순위 큐가 무엇인지 간단히 소개하고 넘어가겠습니다.우선순위의 개념을 큐에 도입한 자료 구조라고 생각하면 됩니다.기존의 큐(Queue)같은 경우에
25.[Java] 세그먼트 트리(Segment Tree)
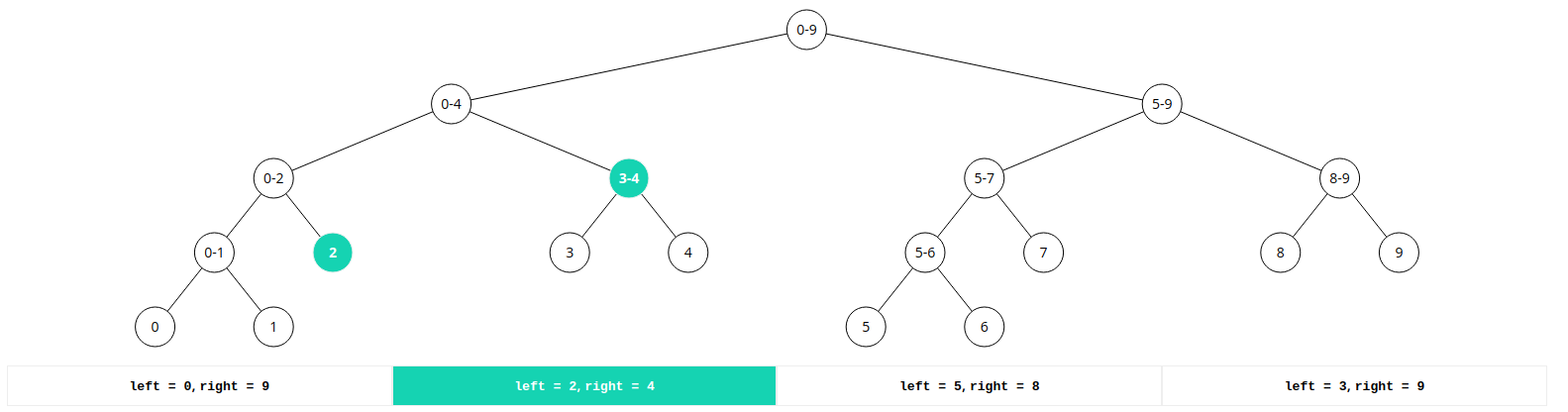
세그먼트 트리는 리프 노드를 제외한 다른 모든 노드는 항상 2개의 자식을 가집니다.
26.[Java] LCA

최소 공통 조상(LCA, Lowest Common Ancestor)은 트리 구조에서 임의의 두 정점이 갖는 가장 가까운 조상 정점을 의미한다.
27.[Java] 느리게 갱신되는 세그먼트 트리 (Segment Tree with Lazy Propagation)

구간 내의 값을 변경하거나 값에 추가적인 연산을 할 경우 굉장히 효과적인 방식입니다.
28.[JAVA] LIS 알고리즘
LIS(Longest Increasing Subsequence)는 불연속 상관없이 가장 길이가 긴 증가하는 부분 수열입니다.
29.[DP][JAVA] LCS 알고리즘
❗ LCS는 Longest Common Subsequence의 줄임말로, 공통 부분 문자열 중 가장 길이가 긴 문자열을 말합니다.
30.[JAVA] 조합과 순열
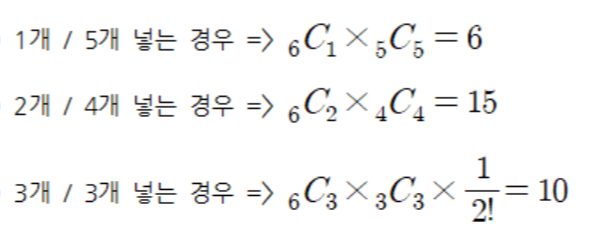
이번 블로그 정리의 목적은 간단한 개념 정리 및 코드 구현이 아닌 좀 더 심화된 내용을 다뤄볼까 합니다.