DL Basics
1.Markov Chain
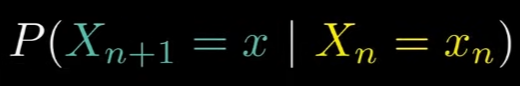
Markov Chain은 특정 상태에서 다음 상태로 넘어갈 때, 다음 상태의 확률은 오직 바로 전 단계의 상태에만 의존한다는 성질을 가지고 있다.
2.Gradient
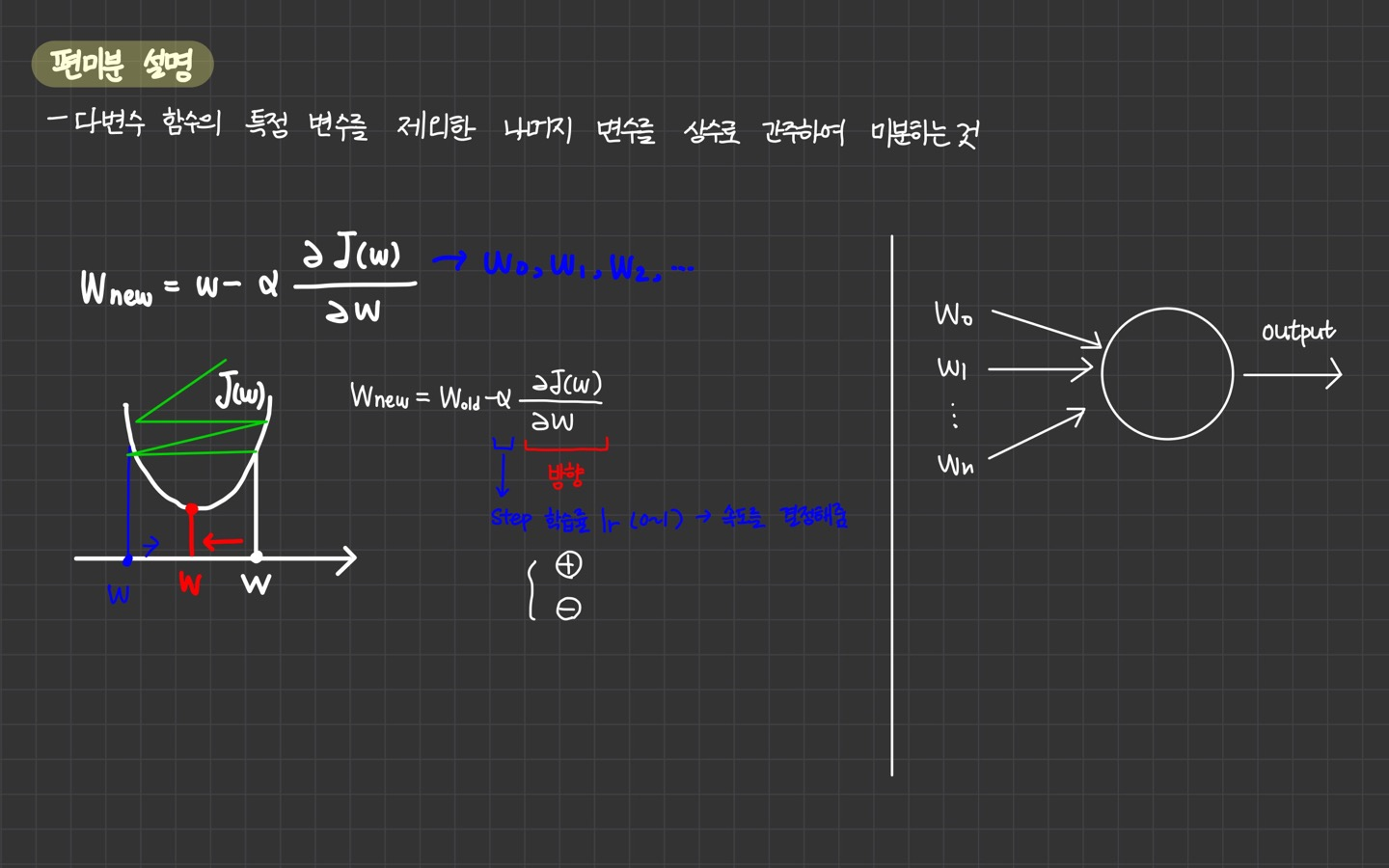
"A gradient measures how much the output of a function changes if you change the inputs a little bit." — Lex Fridman (MIT)
3.Gradient Descent
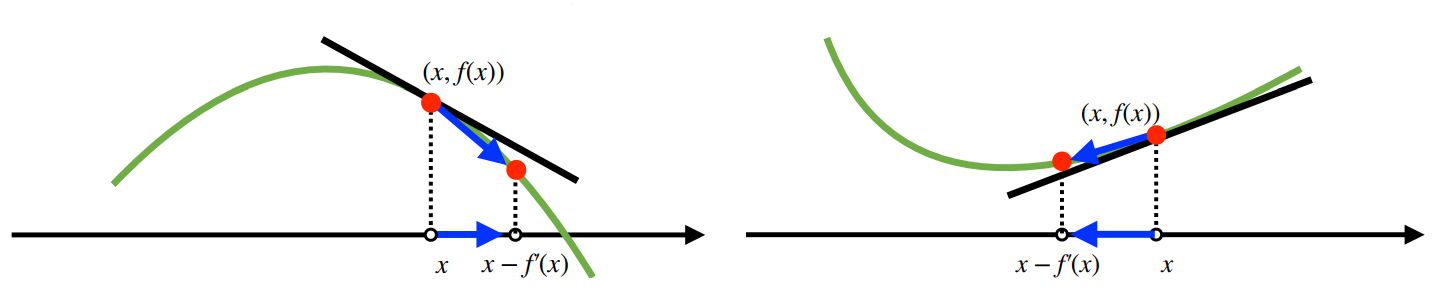
경사하강법(Gradient Descent)는 함수 f의 주어진 점 (x, f(x))에서 x에 미분값을 빼는 것이다. 경사하강법을 통해 함수의 극소값의 위치를 구할 수 있다. 목적함수를 최소화할 때 사용한다.
4.Parameter & Hyper-parameter

파라미터(Parameter)는 모델 내부에서 결정되는 변수이다. 값은 데이터로부터 결정된다.
5.Backpropagation
Gradient Descent에 기반한 학습 진행시, weights와 biases 값들을 반복적으로 변화시켜 목적 함수가 최소가 되도록 한다. 역전파(Backpropagation)가 가중치와 편향 값을 조절할 때, '어떻게'의 역할을 맡는다.
6.Softmax 함수
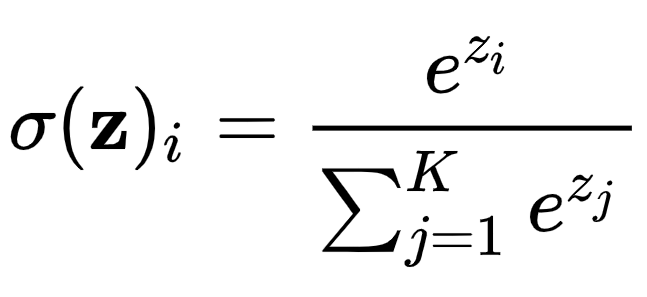
소프트맥스 함수는 다중 클래스 분류를 위해 사용된다. 결과를 확률로 해석할 수 있도록 해준다.
7.엔트로피 (Entropy)
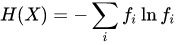
일반적으로 엔트로피는 불확실성을 가르킨다. 확률이 낮을수록, 어떤 정보일지 불확실하다. 이때, '정보가 많다', '엔트로피가 높다'라고 표현한다. 정보를 더 많이 알수록 새롭게 알 수 있는 정보는 적어진다.
8.Kullback–Leibler Divergence
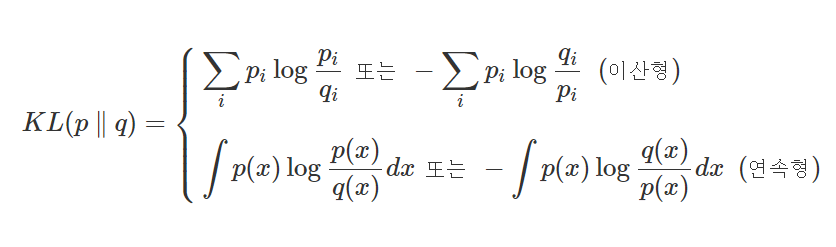
Kullback–Leibler Divergence (KLD)는 두 확률분포의 차이를 계산하는 데에 사용하는 함수로, 한 분포를 근사하는 다른 분포를 사용해 샘플링을 한다면 발생할 수 있는 정보 엔트로피 차이를 계산한다.
9.Focal Loss
Focal Loss는 Object Detection 중 one-stage detector의 성능을 개선하기 위해 고안되었다고 한다. One-stage detector의 문제점은 학습 중 클래스 불균형 문제가 심하다는 것이다.