Sparse Embedding 한계
- 모든 단어를 벡터 공간 상에 표현하기 때문에 차원의 수가 매우 크다. (이는 compressed format으로 어느 정도 해결할 수 있음)
- zero values가 많다.
- Term overlap으로 측정하기 때문에 유사성을 고려하지 못한다.
Sparse embedding은 BoW 방식을 이용하기 때문에 특정 단어에 해당하는 벡터의 차원만 non-zero가 되고, 그 이외의 차원은 zero를 가지게 된다. 따라서 zero의 비율이 아주 큰 sparse matrix를 가지게 된다.
또한, sparse embedding의 가장 큰 문제점은 단어의 유사성을 고려하지 않는다는 점이다. 예를 들어 '시험'과 'exam'은 비슷한 의미를 가지고 있지만 다른 형태를 보인다면, 두 단어는 벡터 공간 상에서 각각 다른 차원을 구성하기 때문에 유사성을 고려하지 못한다.
Dense Embedding
Sparse embedding의 가장 큰 한계인 유사성의 관점을 보완하기 위해 Dense embedding을 사용한다.

Complementary to sparse representation by design
- 더 작은 차원의 고밀도 벡터 (length = 50~1000)
- 각 차원이 특정 term에 대응되지 않는다.
- 대부분의 요소가 non-zero 값을 가진다.
위의 표에서 나타난 것처럼 각 차원이 한 단어에 대응되지 않고, 벡터 공간 상에서 합쳐져서 나타나기 때문에 각 위치가 의미를 나타내어 좀 더 압축된 형태의 벡터 공간을 가지게 된다.
Sparse Retrieval vs Dense Retrieval
그렇다면 두 개의 embedding 방식 중 Retrieval에서 더 효과적인 방식은 무엇인가라는 의문이 생길 것이다. 각각 다른 장점을 가지고, 상황에 맞춰 사용하면 된다.
1. Sparse Embedding
- Sparse는 term overlap으로 측정하기 때문에 중요한 term들이 정확히 일치해야 하는 경우 retrival에서 좋은 성능을 보일 것이다.
- 그러나 Embedding이 구축되고 나서는 추가적인 학습이 불가능하다.
2. Dense Embedding
- Dense는 각 차원이 특정 term에 대응되지 않기 때문에 단어의 유사성 또는 맥락을 파악해야 하는 경우 성능이 뛰어나다.
- 또한 학습을 통해 embedding을 만들기 때문에 추가적인 학습도 가능하다.
- 최근 PLM이 등장하고, 검색 기술이 발전됨에 따라 Dense embedding 방식을 활발히 이용하고 있는 추세이다
Overview of Passage Retrieval with Dense Embedding
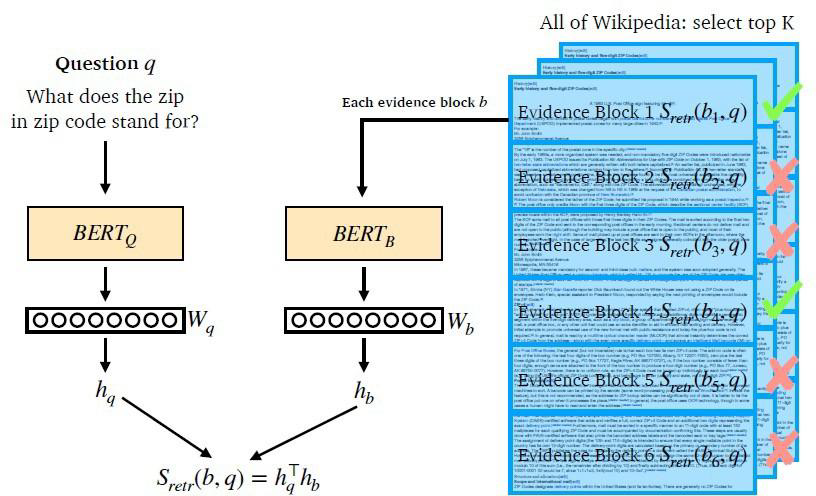
1. Dense Embedding을 생성한 Encoder 학습 진행
- Question과 Passage를 각각 BERT 모델에 입력시켜 벡터 와 를 얻는다. 여기서 두 개의 벡터 크기가 동일해야 한다.
2. 질문과 문서를 비교하여 관련 문서 추출
- 벡터 와 의 유사도를 측정하기 위해 inner product를 한다. 모든 Question과 Passage에 대한 유사도를 측정하여 가장 높은 유사도를 가진 Passsage를 MRC에서 활용한다.
Training Dense Encoder
BERT와 같이 PLM(Pre-trained language model)을 많이 사용되고 있다. 그 외 다양한 NN(neural network) 구조도 사용 가능하다.
BERT 모델에서 [CLS] token을 임베딩하여 output으로 사용하는 것이 dense encoder에서의 목적이다.
Dense Encoder 구조
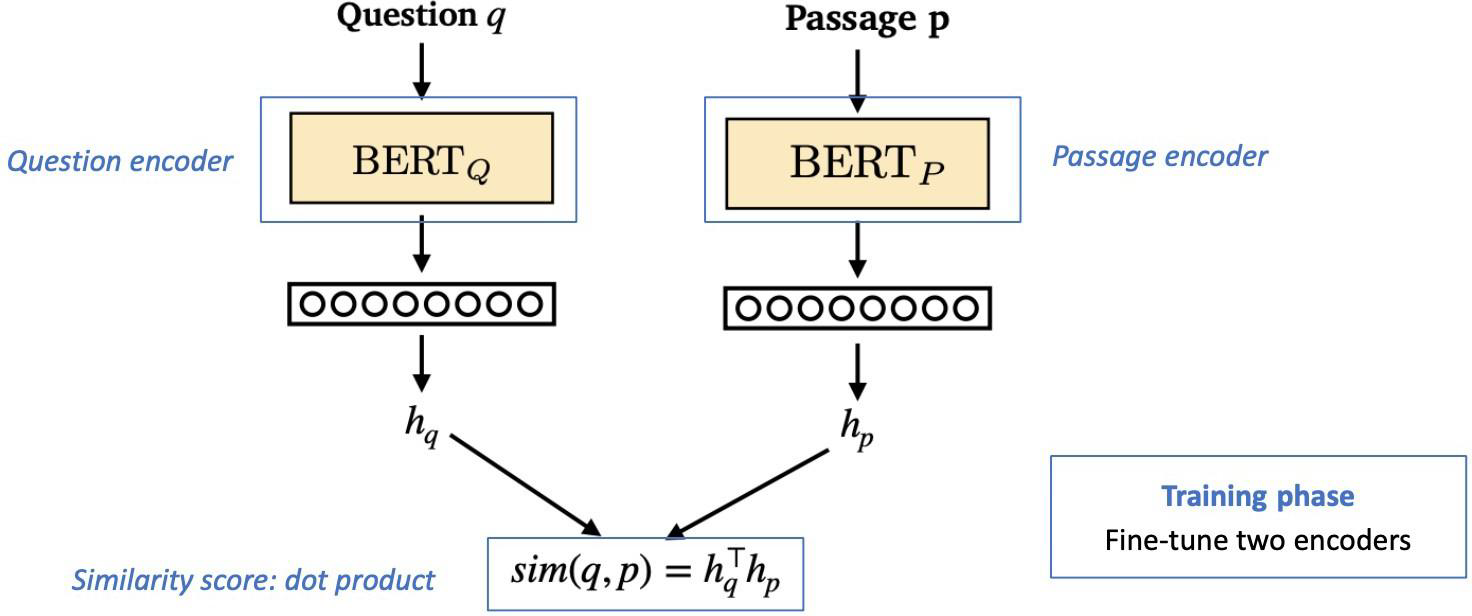
Retrieval은 Question과 Passage를 각각의 BERT encoder에 input으로 넣고, [CLS] 임베딩 토큰을 가지는 벡터 와 를 얻게 된다. 이 벡터를 내적하여 similarity score를 측정할 수 있다.
Dense encoder는 연관된 Question dense embedding과 Passage dense embedding 간의 거리를 좁히는 것 즉, inner product의 값을 높이는 것이 학습 목표이다. 다르게 말하면 높은 유사도를 가질 수 있도록 학습을 진행해야 한다.
학습 과정에서 BERT를 fine-tuning하여 정답인 경우 similarity score가 더 높게, 틀린 경우 스코어가 더 낮게 측정되도록 학습하여 모델링을 하는 것이다.
그러면 연관된 Question과 Passage를 어떻게 찾을 것인가라는 질문이 생기게 된다. 이는 기존의 MRC 데이터셋을 활용하게 되면, Question과 Passage를 하나의 pair로 묶을 수 있고, 그 외의 Passage들은 관련이 없는 것으로 판단할 수 있다. 아래에서 구체적으로 더 다뤄보겠다.
Negative sampling
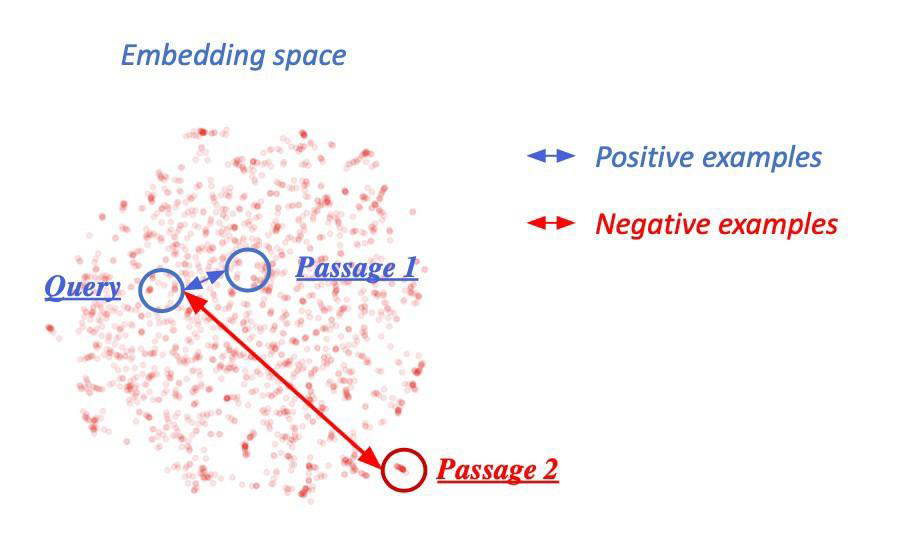
연관된 Question과 Passage 간의 유사도를 더 높이는 것을 Positive라고 하고, 반대로 연관되지 않은 Question과 Passage 간의 유사도는 없는 것은 Negative라고 하여 두 가지 방식으로 학습을 진행할 수 있다.
Negative examples을 뽑는 방식은 두 가지가 있다.
- Corpus 내에서 랜덤하게 뽑기
- 좀 더 헷갈리는 negative 샘플들 뽑기
최근에는 2번 방식을 더 선호하는데, 예를 들어 높은 TF-IDF score를 가지지만 답을 포함하지 않는 sample을 뽑아 학습할 수 있다.
Objective function
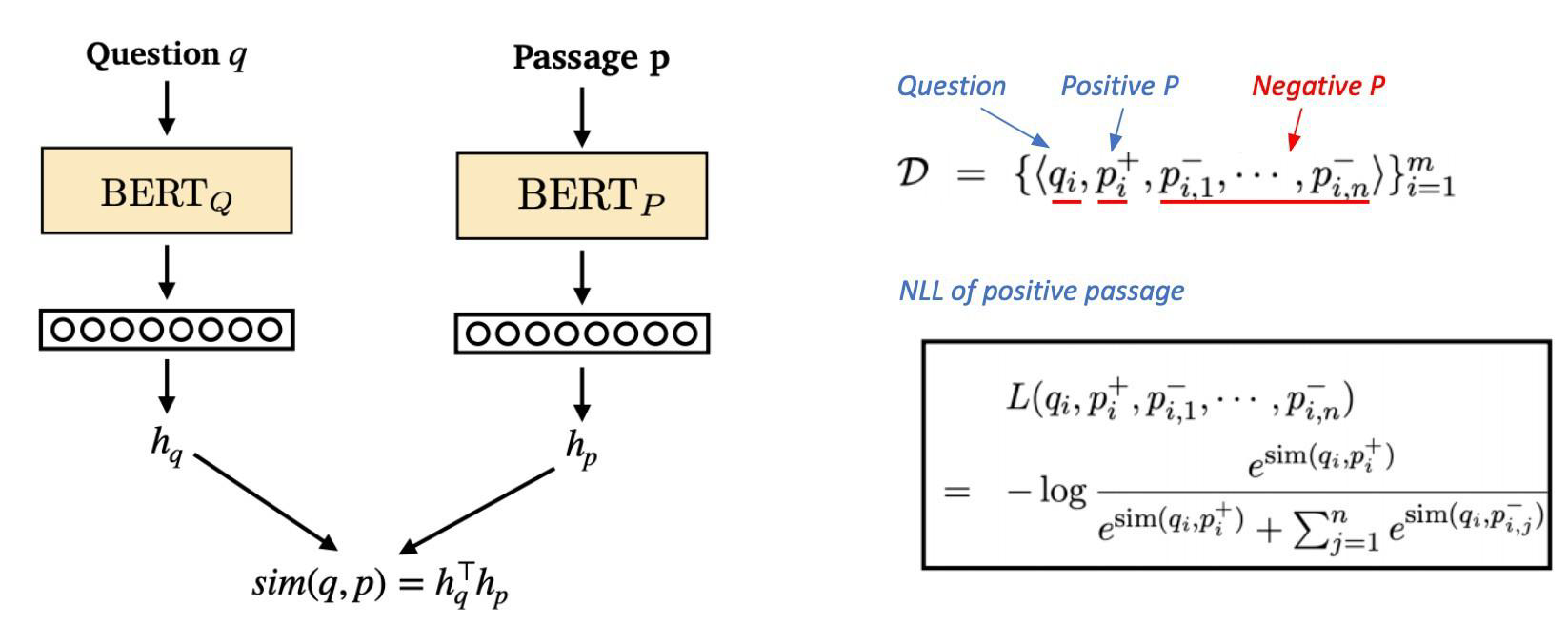
해당 방식은 Positive passage에 대한 NLL(negative log like) loss를 사용하여 positive passage의 score를 확률로 표현하는 것이다.
위의 수식을 보면 분자에는 Positive 값만 있고, 분모에는 Positive와 Negative의 합으로 이루어져 있다. 이 분수에서 -log를 취한 값이 NLL이다. (단, 값들은 softmax를 거친 값이다.)
Dense Encoder의 평가지표
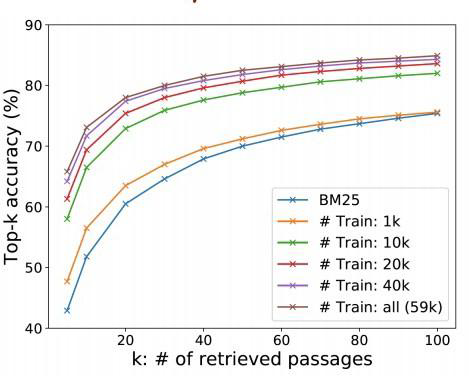
Retrieval의 성능 측정 방식은:
1. Ground truth passage를 알고 있기 때문에 Retrieve된 Passage 중에서 ground truth passage가 있는지 확인하기
2. Top-k retrieval accuracy: MRC와 관련이 있는 metric으로 최종 MRC의 답을 포함하는 passage의 비율 확인하기
(Upper bound: 원하는 값 k를 초과한 값이 처음 나오는 위치를 찾는 과정)
Passage Retrieval with Dense Encoder
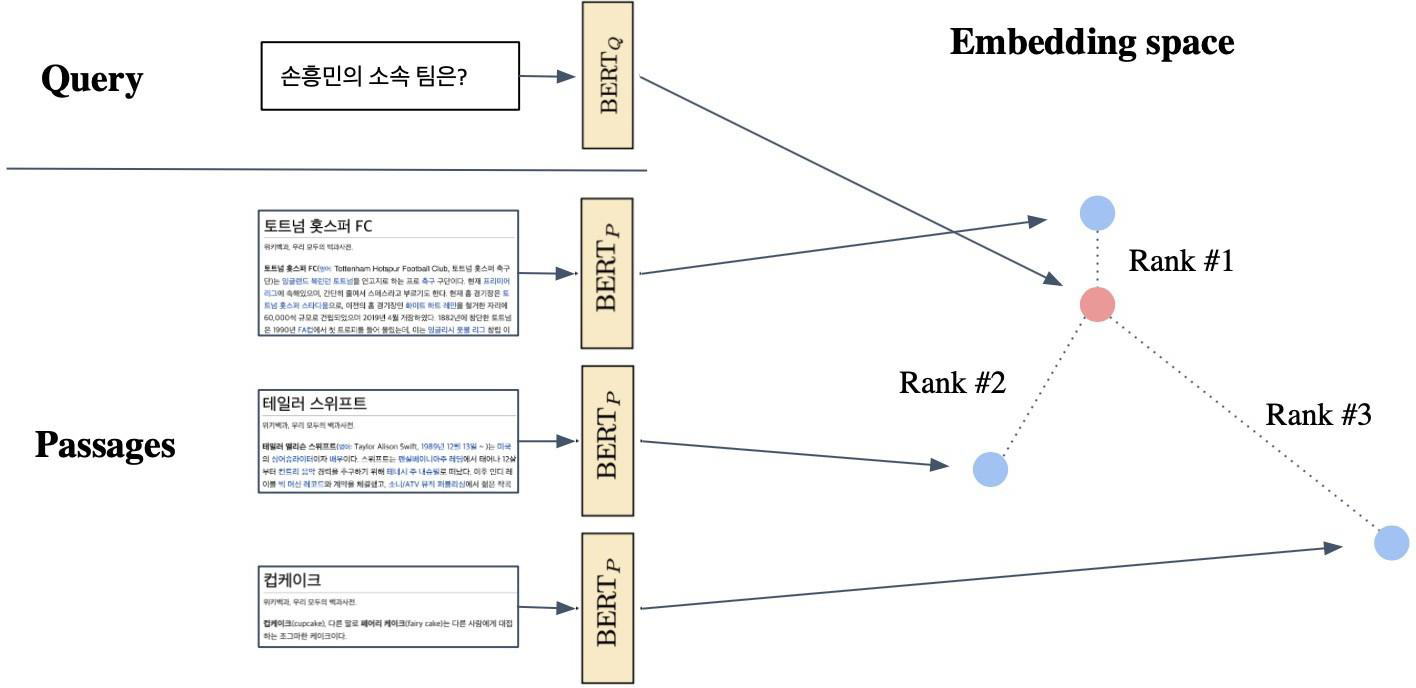
위에서 인코딩이 끝나면 retrieva을 진행한다. Passage embedding은 미리 진행한 뒤 로컬 또는 오프라인에 저장해놓는다. Question이 주어질 때마다 embedding을 구한 뒤, 사전에 저장해놓은 Passage embedding과의 내적을 구하고, 가장 유사도가 높은 Passage를 반환하는 방식으로 진행된다.
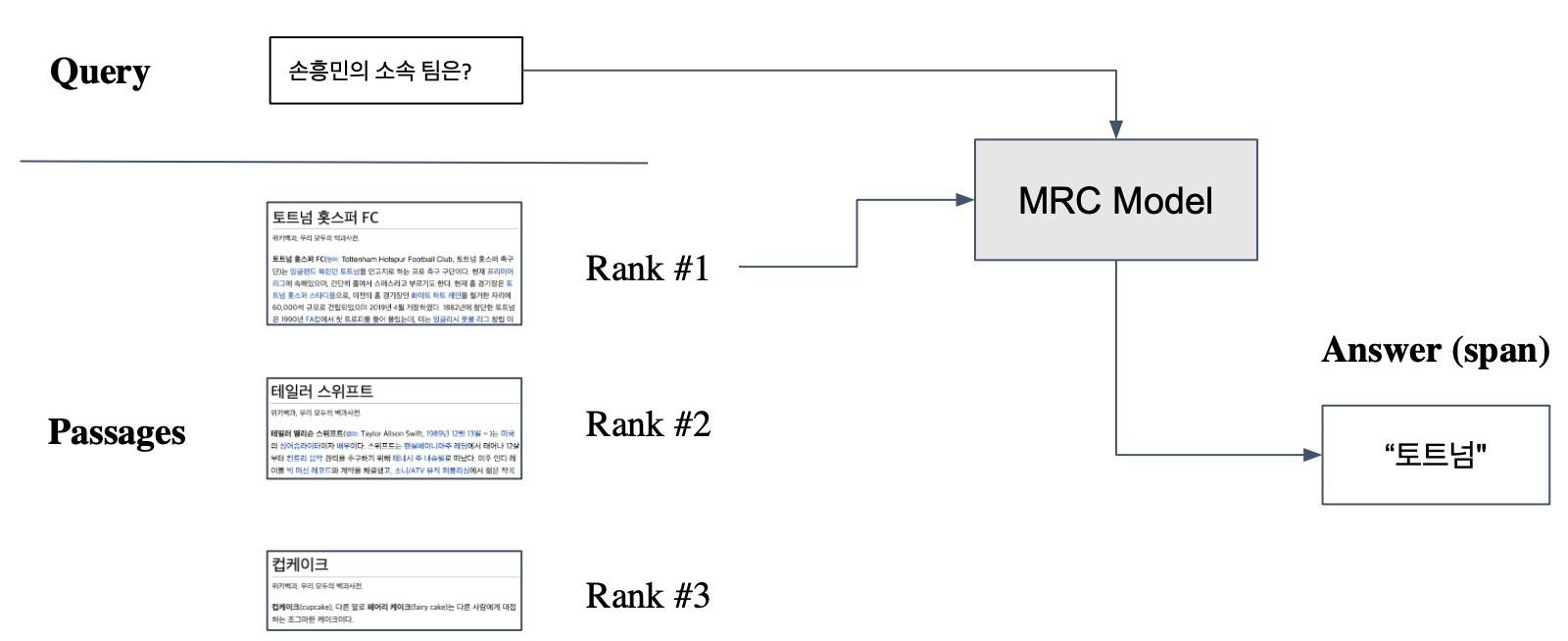
이렇게 Retrieval을 통해 찾아낸 rank 1의 Passage와 Query를 MRC 모델에 넘겨주어 최종적인 답을 찾을 수 있다.
Dense Encoding 성능 향상을 위한 고려사항
- 학습 방법 개선 (ex. DPR)
- Encoder 모델 개선 (ex. BERT 보다 크거나 정확한 PLM)
- 데이터 개선 (데이터 증강, 전처리, 후처리 등)
