Passage Retrieval & Similarity Search
이전 포스팅에서 사용한 검색 방법은 brute-force(exhaustive) search 로, 저장해둔 모든 Sparse/Dense Embedding에 대해 일일이 내적값을 계산하여 가장 값이 큰 passage를 추출하는 방식을 활용했다. 그러나 이 방법은 Passage가 많아질수록 연산량 또한 커지기 때문에, 효율적으로 검색하는 방식에 대해 다룰 것이다.
MIPS (Maximum Inner Product Search)

주어진 Query 벡터 에 대해 Passage 벡터 들 중 가장 query와 관련된 벡터를 찾아야 한다. 여기서 관련성을 inner product 값이 가장 큰 것으로 한다.
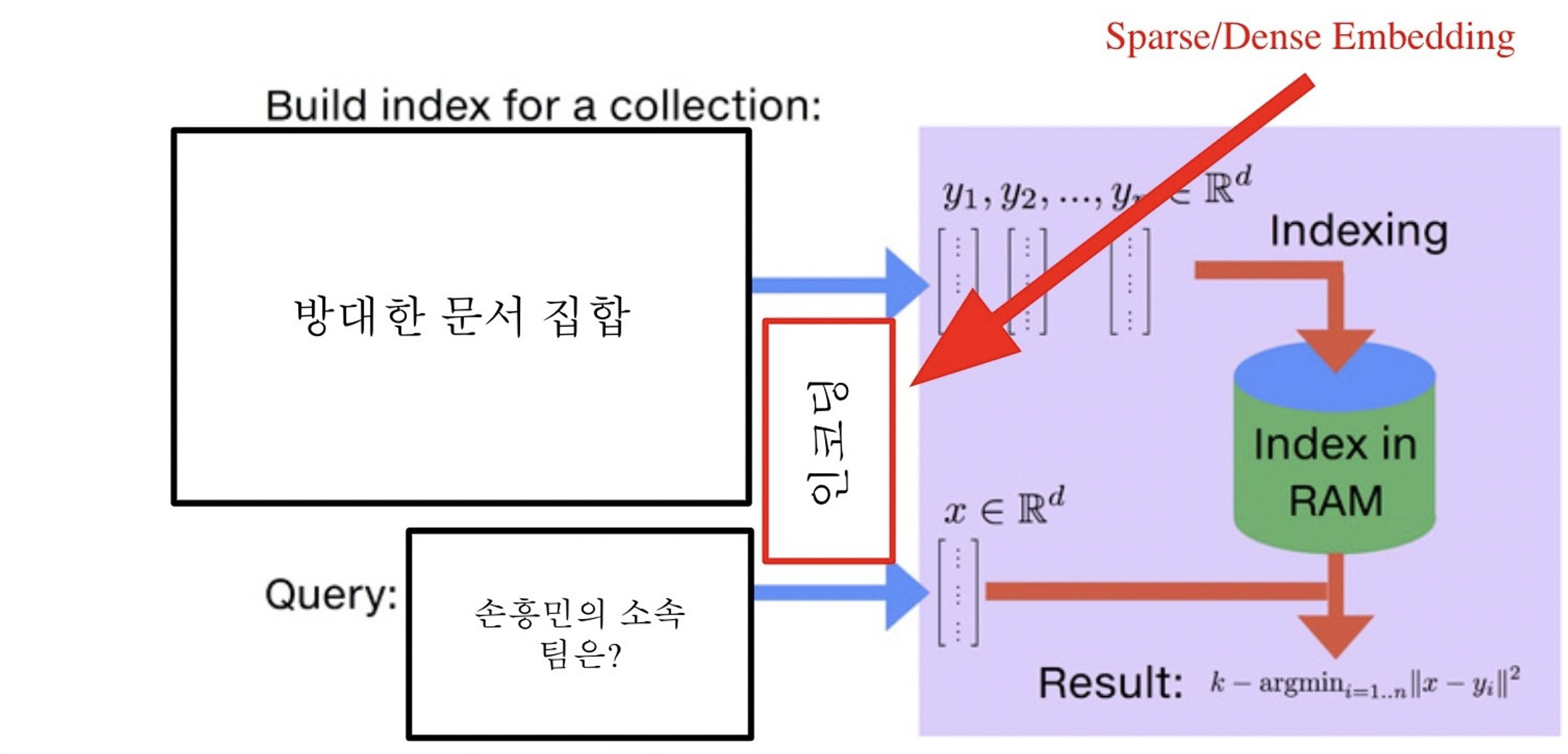
위의 그림처럼, query가 들어올 때마다 사전에 인코딩된 passage 벡터들과 비교하여 검색하는 방식을 사용한다.
- 인덱싱(Indexing) : 방대한 양의 passage 벡터들을 저장하는 방법으로, 에 해당한다.
- 검색(Search) : 인덱싱된 벡터들 중 query 벡터와 가장 inner product 값이 큰 상위 k개의 벡터를 찾는 과정으로, 위의 수식이 이 과정에 해당한다.
실제로 검색해야 할 데이터는 엄청나게 많은 양이다. 위키피디아의 경우 5백만 개이지만, 다른 문서까지 포함한다면 수십 억, 조 단위까지 커질 수 있다. 즉, 해당 방식으로 모든 문서의 임베딩을 일일이 비교하면서 검색하는 것은 실질적으로 한계가 있다.
Tradeoffs of similarity search
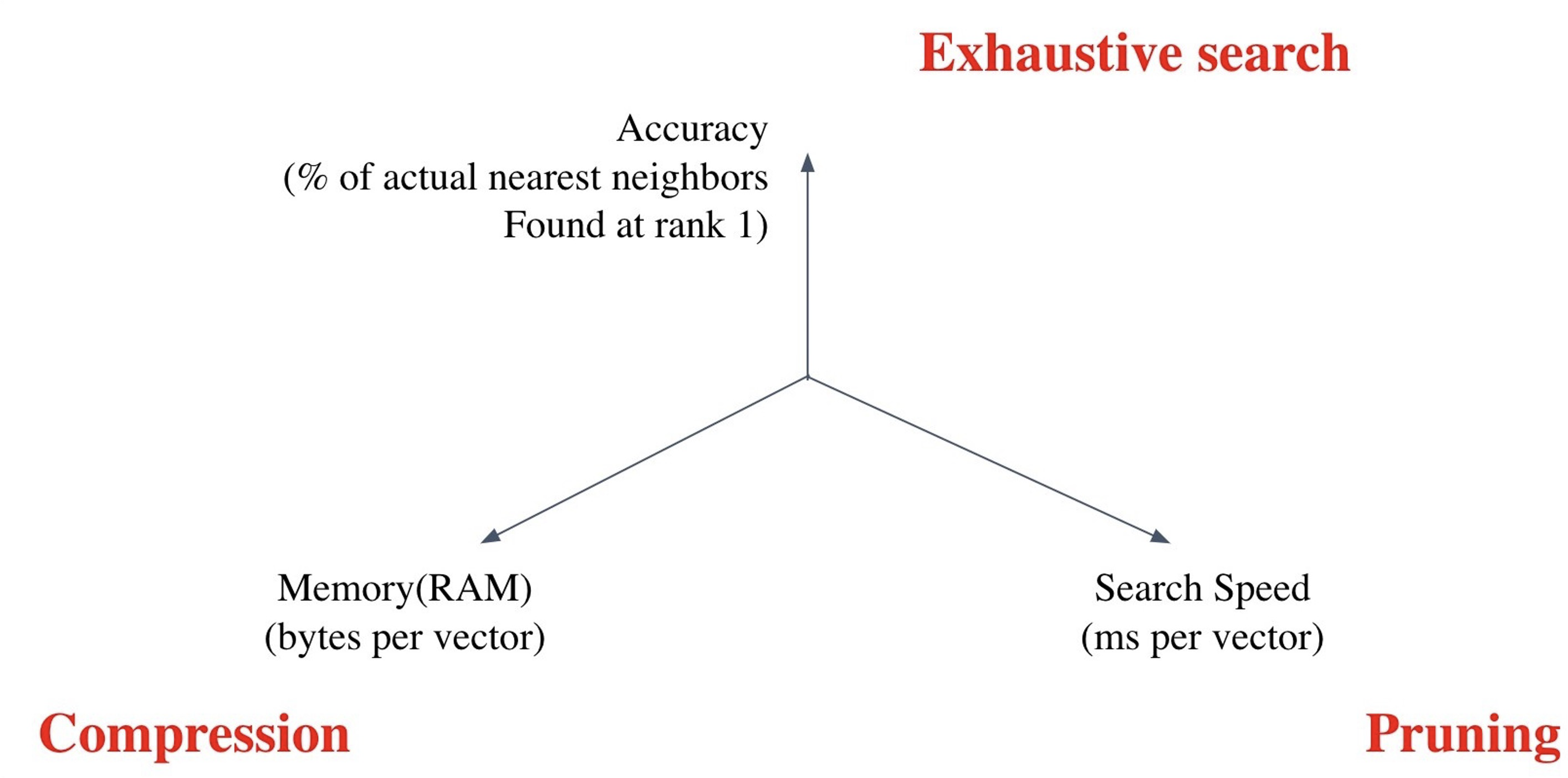
(1) Search Speed
Query 당 유사한 벡터를 k개 찾는데 얼마나 걸리는가?
=> 가지고 있는 벡터량이 클수록 더 오래 걸린다.
(2) Memory Usage
벡터를 사용할 때, 어디에서 가져올 것인가?
=> RAM에 모두 올려둘 수 있으면 빠르지만, 많은 RAM 용량을 요구한다.
=> 디스크에서 계속 불러와야 한다면 속도가 느려진다.
(3) Accuracy
brute-force 검색 결과와 얼마나 비슷한가?
=> 속도를 증가시키려면 정확도를 희생해야 하는 경우가 많다.
검색 속도(search time)와 재현율(recall)의 관계
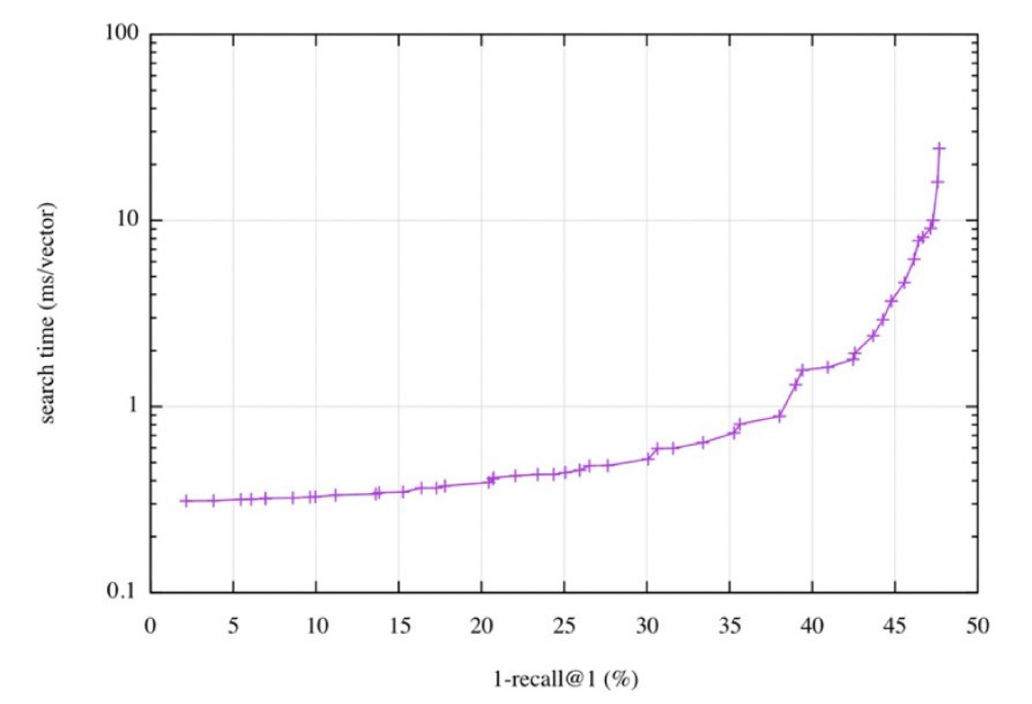
위의 그래프와 같이, 더 정확한 검색을 하려면 더 오랜 시간이 소모되는 것을 확인할 수 있다.
Increasing search space by bigger corpus
corpus의 크기가 커질수록 vector space의 차원이 커지기 때문에 탐색 공간이 커지고 검색이 어려워진다. 또한 저장해 둘 memory space도 많이 요구된다. 해당 문제는 term에 대Sparse embedding에서 훨씬 심각하게 나타난다.
Approximating Similarity Search
1. SQ (Scalar Quantization)
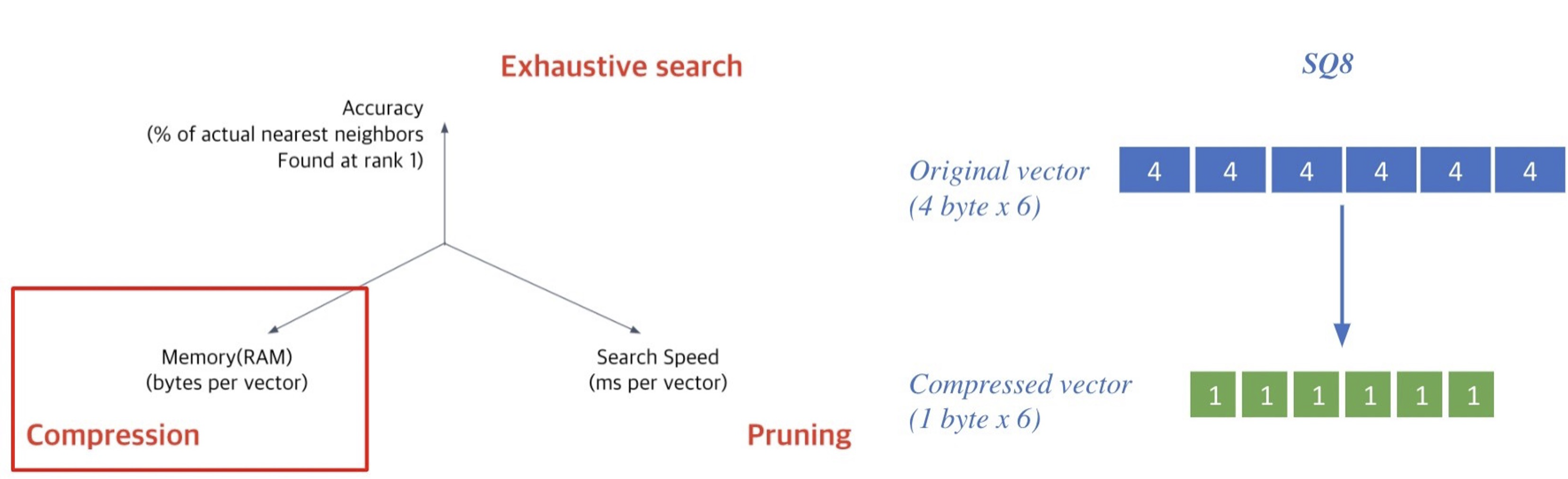
Compression의 방식 중 하나로 벡터를 압축하여, 하나의 벡터가 적은 용량을 차지하도록 하여 압축량은 늘리고, 메모리 사용량을 줄이는 방식이다. 그렇기 때문에 정보 손실량은 높다.
SQ는 4-byte floating point를 1-byte(8bit) unsigned integer로 압축한다.
2. IVF (Inverted File)
Pruning은 Search space를 줄여서 검색 속도를 개선하기 위한 방식으로, dataset의 subset만 방문한다. 보통 Clustering과 IVF를 활용하여 검색을 진행한다.
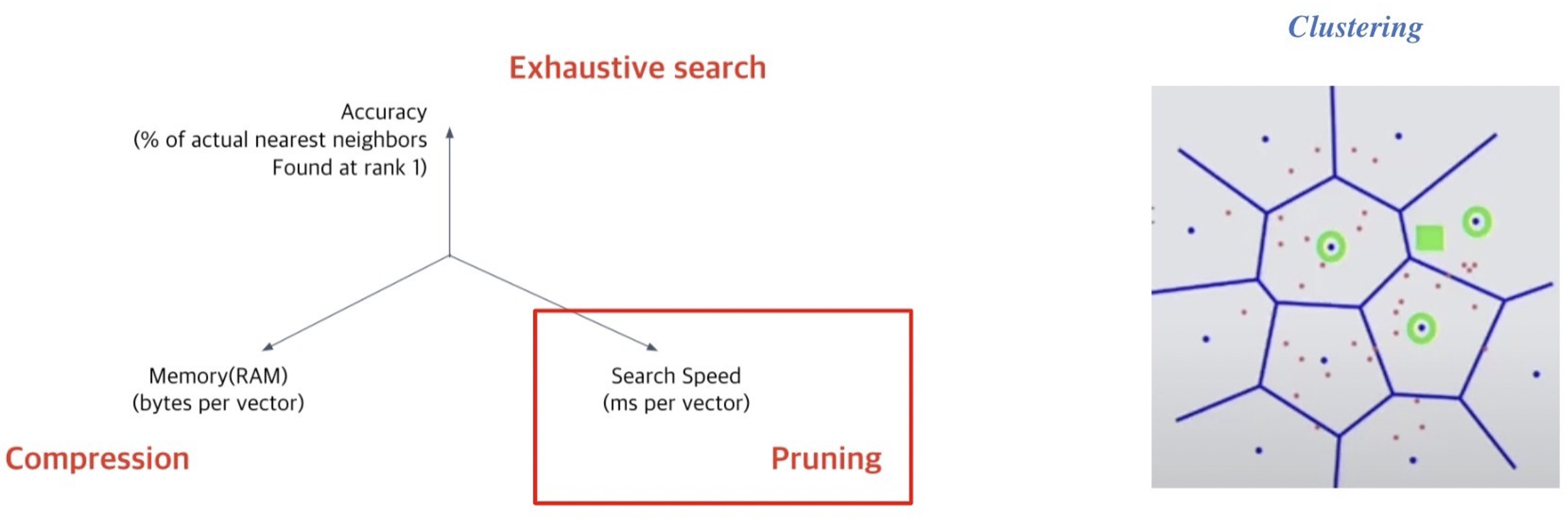
Clustering은 전체 vector space를 k개의 cluster로 나누는 방식으로, 대표적인 예로 k-means clustering이 있다. 이러한 cluster가 있을 때 query가 입력되면 근접한 cluster의 점들에 대해서만 비교를 한다. 위의 그림처럼 한 점(네모)에 대해 이웃하고 있는 cluster가 3개가 있고, 해당 군집 내에 있는 모든 점들과 exhaustive search로 비교하여 검색한다. 따라서 이러한 방식으로 비교하기 때문에 검색 속도를 훨씬 줄일 수 있다.
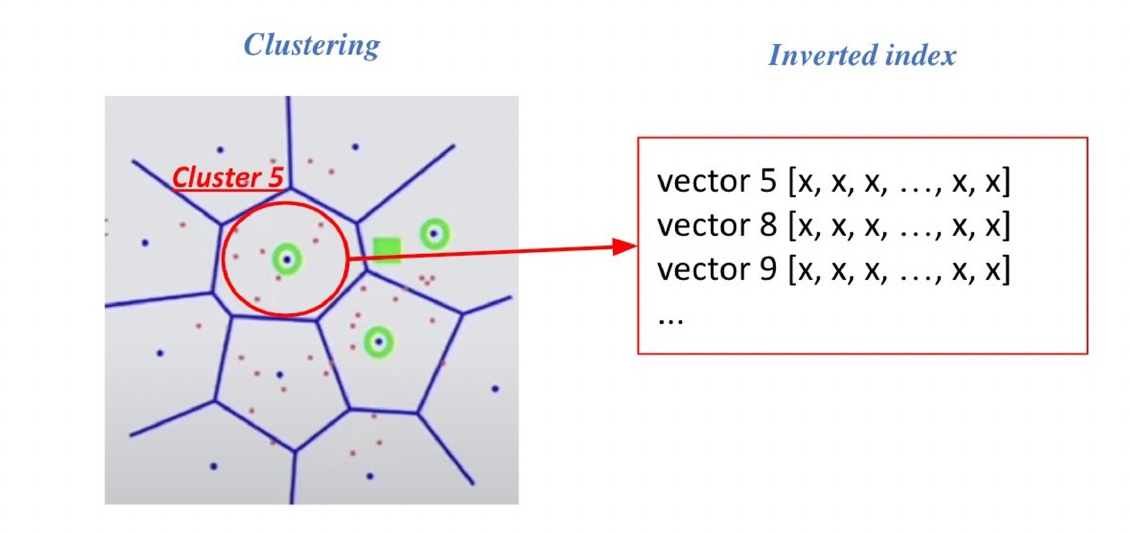
IVF는 벡터의 index를 inverted list structure로 간주하여 각 cluster의 centroid id와 해당 cluster의 벡터들이 연결되어 있는 형태로 되어 있다. 즉, 각 cluster에 포함되어 있는 점들을 역으로 인덱스로 가지고 있다는 것이다.
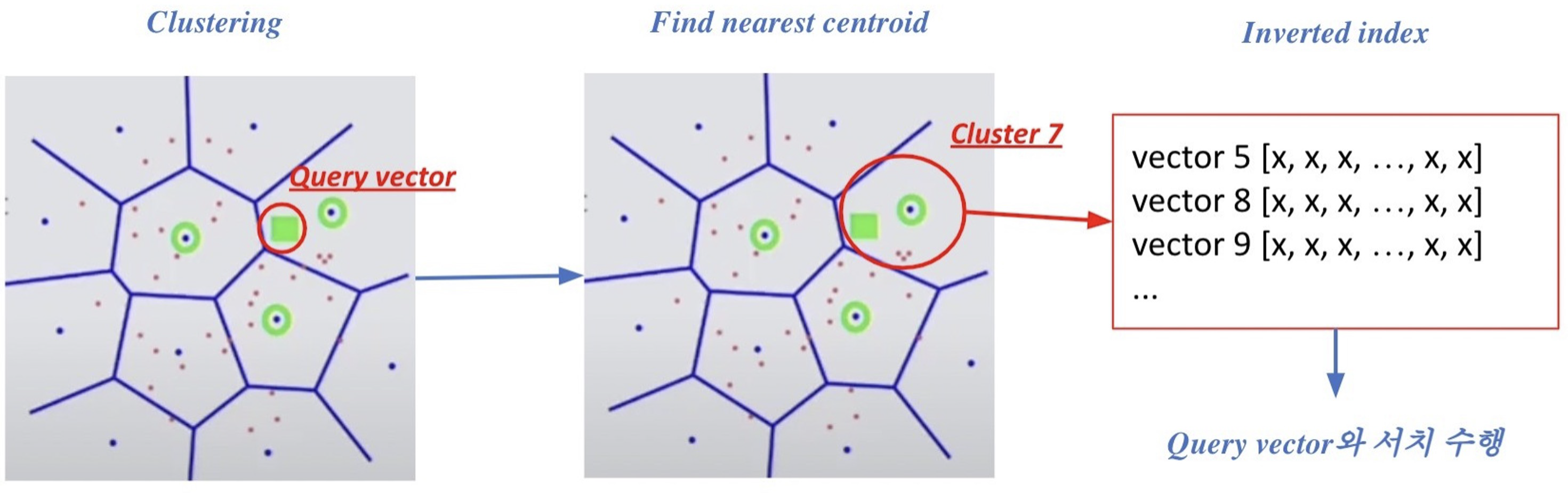
위의 그림은 Clustering과 IVF를 활용하여 검색하는 방식을 보여준다. 먼저 주어진 query vector에 대해 근접한 centroid vector를 찾는다. 그런 다음 찾은 cluster의 inverted list 내 vector들에 대한 search를 수행한다. 이러한 과정은 cluster에 속해 있는 벡터들을 빠르게 확보가 가능하기 때문에 search space를 많이 줄일 수 있다.
FAISS
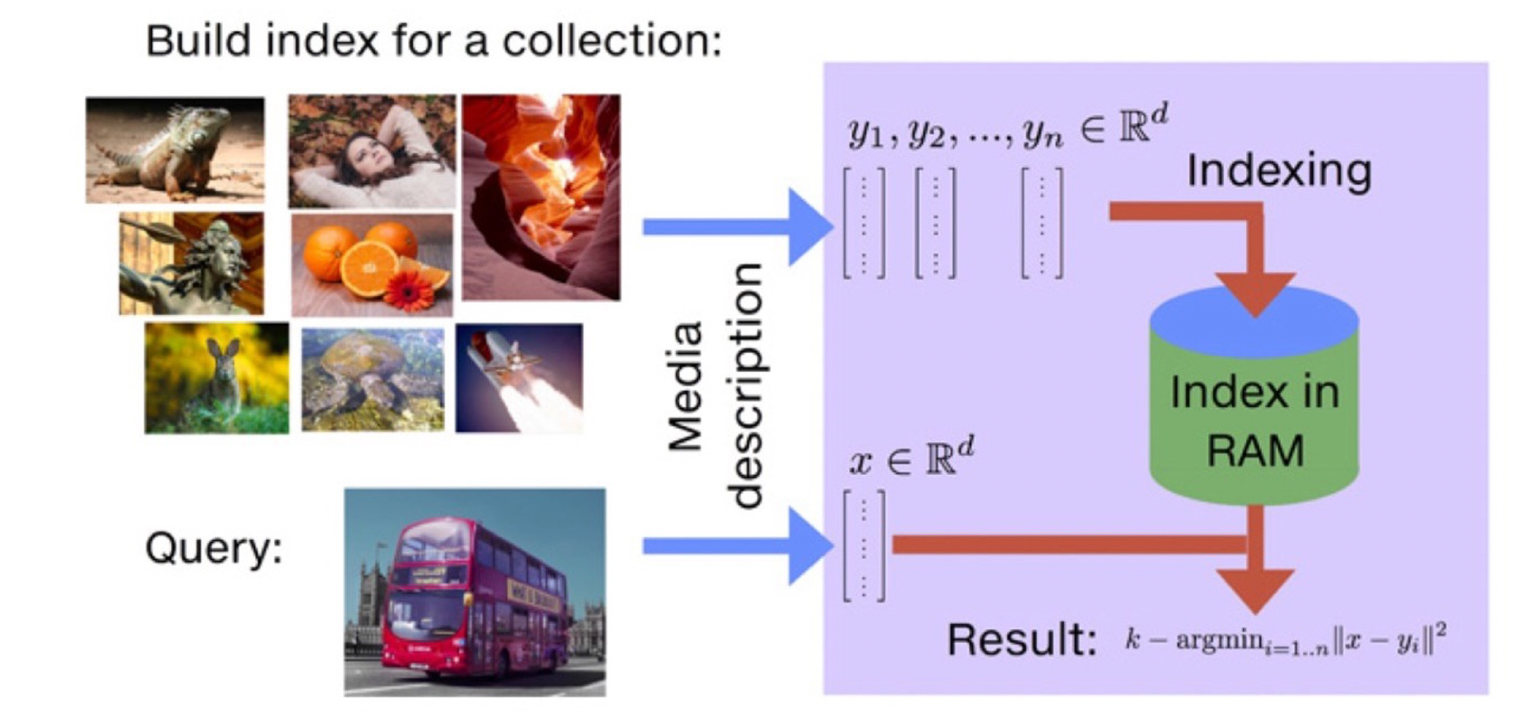
FAISS는 Facebook에서 개발한 것으로, 밀집 벡터의 효율적인 유사도 검색과 클러스터링을 위한 라이브러리이다. FAISS의 핵심개념은 인덱스 생성이다. 먼저 데이터를 양자화하여 인덱스를 생성하고, 이후 이 인덱스를 활용하여 벡터 공간에서 가장 가까운 벡터를 효과적으로 찾아내는 유사성 검색을 수행한다.
Passage Retrieval with FAISS
1. Train index and map vectors
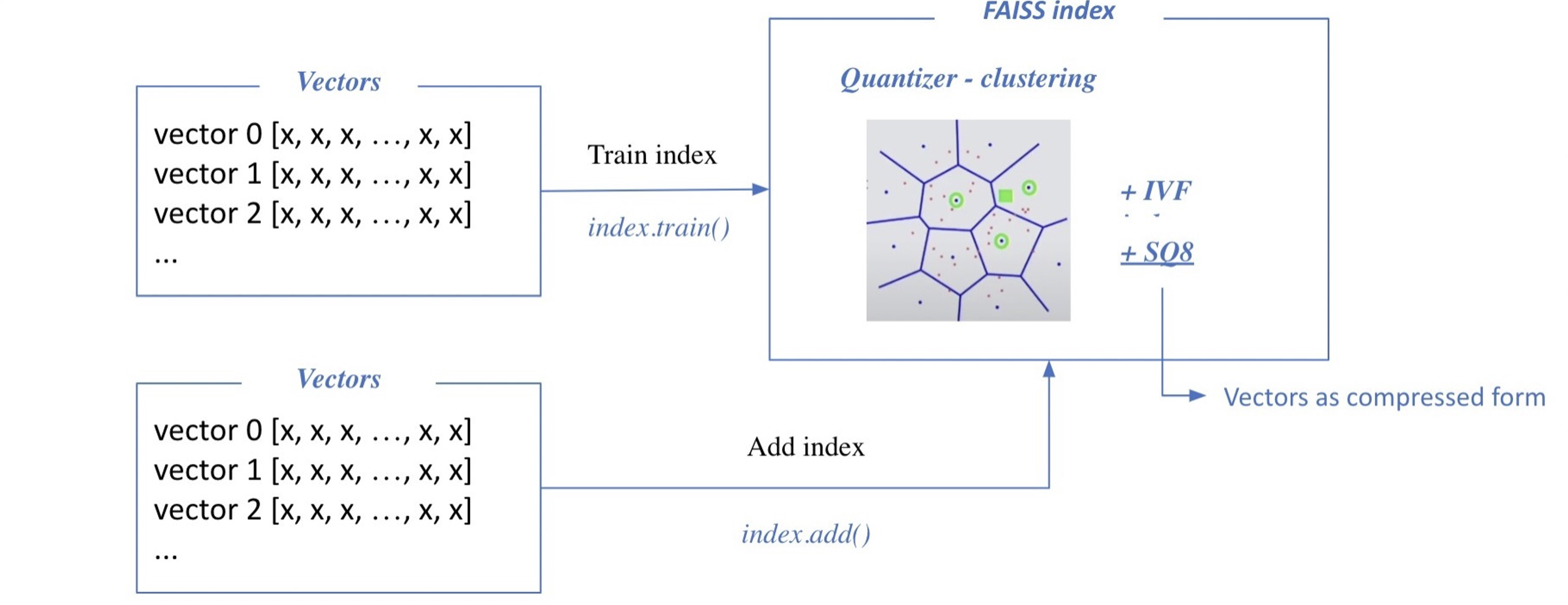
2. Search based on FAISS index
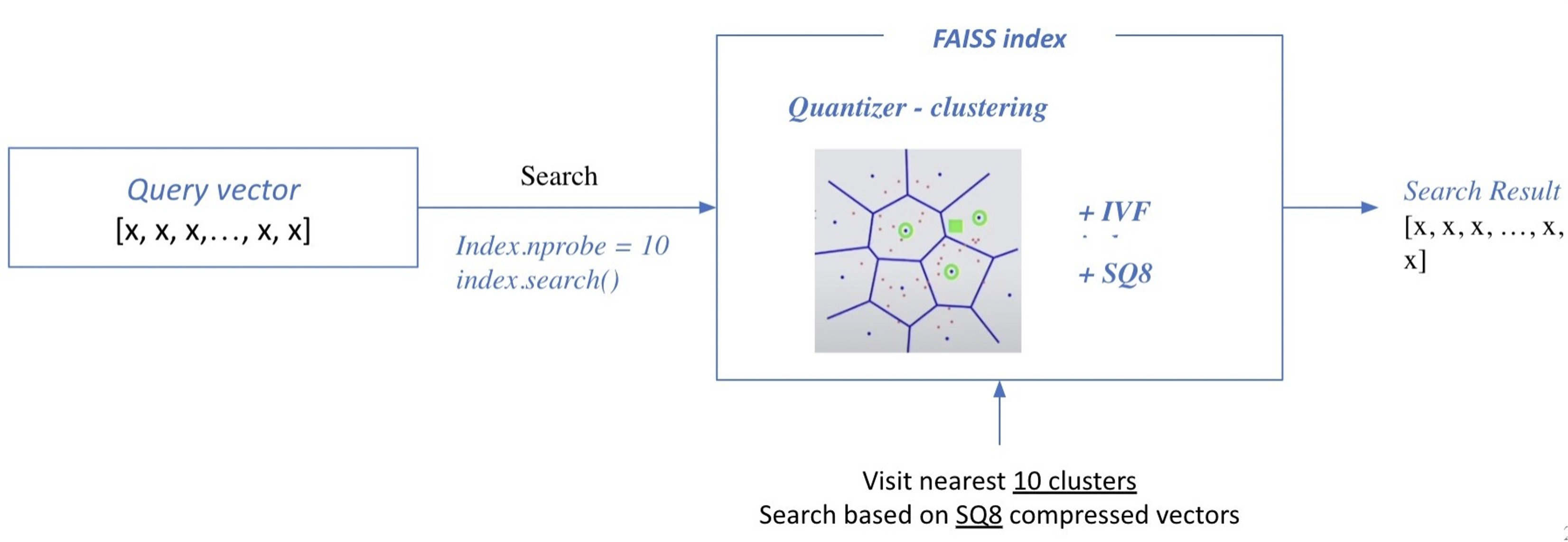
추론할 때는 query가 들어오면 검색을 통해 가장 가까운 cluster들을 접하게 되고, cluster 내에 있는 모든 벡터와 비교하여 Top-k를 뽑게 된다.
(nprobe : 몇 개의 가장 가까운 cluster를 방문하여 search 할 것인지)
Scaling up with FAISS
먼저 brute-force로 모든 벡터와 query를 비교하는 가장 단순한 인덱스를 만든다.
d = 64 # 벡터의 차원
nb = 100000 # 데이터베이스 크기
nq = 10000 # query 개수
xb = np.random.random((nb, d)).astype('float32') # 데이터베이스 예시
xq = np.random.random((nq, d)).astype('float32') # query 예시index = faiss.IndexFlatL2(d) # 인덱스 빌드
index.add(xb) # 인덱스에 벡터 추가k = 4 # 가장 가까운 벡터 4개
D, I = index.search(xq, k) # 검색
# D: query와의 거리
# I: 검색된 벡터의 인덱스IVF with FAISS
- IVF 인덱스 만들기
- 클러스터링을 통해서 가까운 cluster 내 벡터들만 비교
- 빠른 검색 가능
- 클러스터 내에서는 여전히 전체 벡터와 거리 비교 (Flat)
nlist = 100 # 클러스터 개수
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFFlat(quantizer, n, nlist) # Inverted File 만들기
index.train(xb) # 클러스터 학습하기
index.add(xb) # 클러스터에 벡터 추가하기
D, I = index.search(xq, k) # 검색IVF-PQ with FAISS
- 벡터 압축 기법 (PQ) 활용하기
- 전체 벡터를 저장하지 않고 압축된 벡터만을 저장
- 메모리 사용량을 줄일 수 있다.
nlist = 100 # 클러스터 개수
m = 8 # subquantizer 개수
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8) # 각각의 sub-vector가 8bits로 인코딩 됨
index.train(xb)
idnex.add(xb)
D, I = index.search(xq, k) # 검색Using 1 GPU with FAISS
- GPU의 빠른 연산 속도를 활용할 수 있다.
- 거리 계산을 위한 행렬곱 등에서 유리하다. - 다만, GPU 메모리 제한이나 메모리 random access 시간이 느린 것 등이 단점이다.
res = faiss.StandardGpuResources() # 단일 GPU 사용
index_flat = faiss.IndexFlatL2(d) # 인덱스 (CPU) 빌드하기
gpu_index_flat = faiss.index_cpu_to_gpu(res, 0, index_flat) # GPU 인덱스로 옮기기
gpu_index_flat.add(xb)
D, I = gpu_index_flat.search(xq, k) # 검색Using Multiple GPUs with FAISS
- 여러 GPU를 활용하여 연산 속도를 한 층 더 높일 수 있다.
cpu_index = faiss.IndexFlatL2(d)
gpu_index = faiss.index_cpu_to_all_gpus(cpu_index) # GPU 인덱스로 옮기기
gpu_index.add(xb)
D, I = gpu_index.search(xq, k) # 검색