본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
Encoder-Decoder 모델
모델 간단 동작 설명
- 주로 Transformer, BART, T5 등에서 Encoder-Decoder 모델을 사용하고 있다.
- Encoder에서 정보를 해석하고, Decoder에서 생성하는 형태로 구성되어 있다. (즉, Encoder에서 정보를 가져와서 제한된 벡터 크기로 줄이고, 제한된 벡터를 Decoder에서 우리가 쓰는 일상적인 언어로 압축을 해제하는 역할을 하는 것이라고 보면 된다.)
- Encoder의 정보를 Decoder에서 Cross-Attention 연산을 통해 생성할 때 Encoder의 정보를 추가적으로 활용한다.
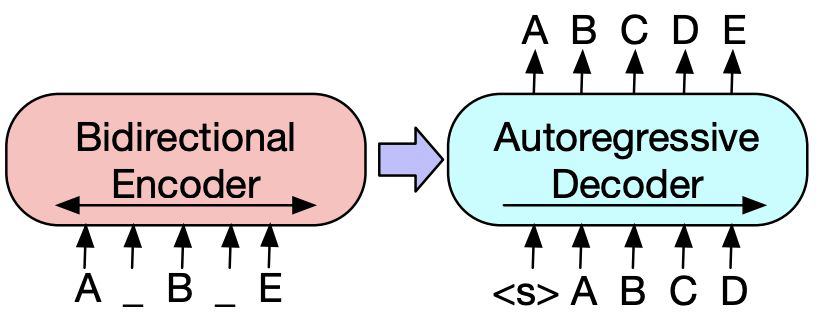
- 위의 그림과 같이, encoder는 A, B, E와 같은 불연속적(discrete)인 언어를 연속적인 벡터 공간으로 변환한다.
- 벡터 공간으로 이루어진 것들을 숫자로 표현하고, 숫자를 다차원으로 표현하는 것을 통해서 정보를 손실 및 압축을 시켜줄 수 있다.
- 이렇게 손실(압축)된 정보를 decoder에게 전달하면, 그 다음에 나올 토큰을 예측하거나 빈 자리에 올 토큰을 예측하는 역할을 수행하게 된다.
- 여기서 Bidirectional encoder는 마스킹 된 정보와 마스킹이 되지 않은 정보를 모두 양방향으로 본다.
- Autoregressive decoder는 A, B, C, D 이후에 올 정보는 생성하기 전에 알 수가 없기 때문에, 생성하기 전의 부분만 보고 뒤에 올 정보를 맞추는 형식으로 동작한다.
- Encoder만 사용하면 BERT, Deocder만 사용하면 GPT, 모두 사용하면 Transformer 모델이다.
모델의 활용 & 발전
- Machine Translation / Summary / Generative QA
- 생성 Task를 수행하면서 Decoder-only 모델의 성능을 보완한다.
- 여기서 생성 Task는 긴 Sequence를 입력으로 넣고, output은 비교적 짧은 sequence 또는 단어 수준으로 내는 것을 의미한다.
모델의 한계
- 효율성 : Encoder와 Decoder 각각에서의 Self-Attention 뿐만 아니라 연결부에서의 Cross-Attention에서 병목이 발생한다.
- 확장성 : Input으로 사용하는 context length가 짧기 때문에, In-Context Learning을 Encdoer에 최적화하는데 추가 비용 소모가 발생한다.

✨🐰🫧