본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
Encoder-Only Model
BERT (Bidirectional Encoder Representation for Transformers)
- Mask 토큰을 예측하는 형태로 모델을 학습시키는 방식으로, Masked Language Model 중 하나이다.
- Self-supervised learning 방식을 활용하여, 입력 문장에 [Mask] 토큰을 넣어주어, 여기에 들어올 단어를 예측하는 작업을 진행한다.
- 위와 같은 작업으로, 빈칸 맞추기 모델을 Classification Task로 변환할 수 있다.
- 보통 언어 모델은 Vocab을 통해서 문장을 토큰 단위로 만들고, 토큰 단위로 쪼개진 문장을 학습할 수 있게 된다. 즉, vocab의 여러 단어들 중 [MASK]에 들어올 한 개의 단어를 찾는 과정을 진행하는 것이다.
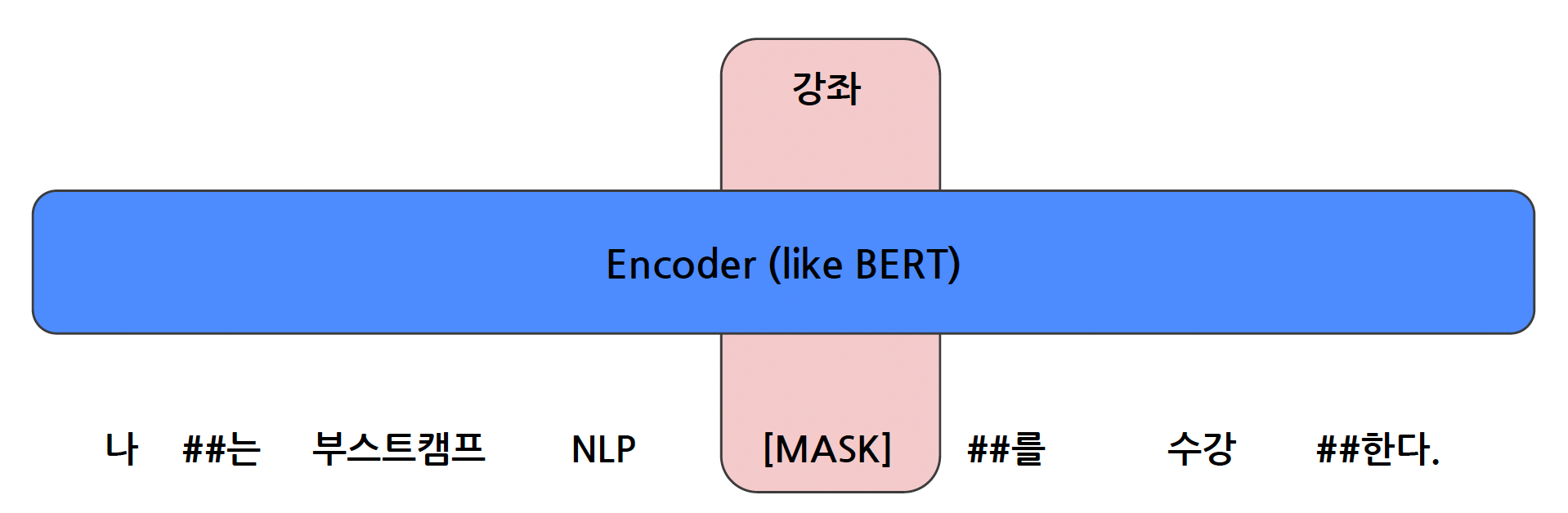
- BERT 모델은 15% 정도만 [MASK]로 설정하고, 85%만 정상 토큰에 해당하는 것이다. 즉, 85%의 토큰은 15%의 토큰을 예측하는 데에만 사용되는 것이고, 실제로 전체 문장을 예측하는 것은 15%의 토큰으로만 활용하는 것이다.
- 이때, 85%의 토큰도 학습 시 사용되지만 주변 토큰을 예측하는데 사용되고, decoder-only 모델처럼 직접 각 토큰을 예측하는데 사용되지 않는다.
모델 활용 & 발전
- 문서 분류 (감정 분석, 스팸 필터링 등)
- 정보 검색 (IR, 임베딩)
- Extractive QA (ex. 수능문제)
모델 한계
- Sequential Task에 대한 한계
- Auto-Regressive 형태의 Task를 제대로 수행하지 못한다.
-> BERT 모델은 사전 학습을 MLM으로 수행하고, 그 뒤에 nn.Linear는 단순 분류기로 학습을 하는 방식으로 구성되어 있다.
-> 그렇기 때문에 BERT의 학습을 위해서 사용했던 linear 모델은 사용하지 못할 뿐만 아니라, BERT 모델이 학습된 케이스와 실제로 쓰는 케이스가 너무 다르다.
-> 따라서, 언어모델이 BERT의 성능을 완벽히 가져와서 사용하지 못하기 때문에, 생성 Task에서 큰 약점을 가진다.

✨🐰🫧