기계독해 (MRC)
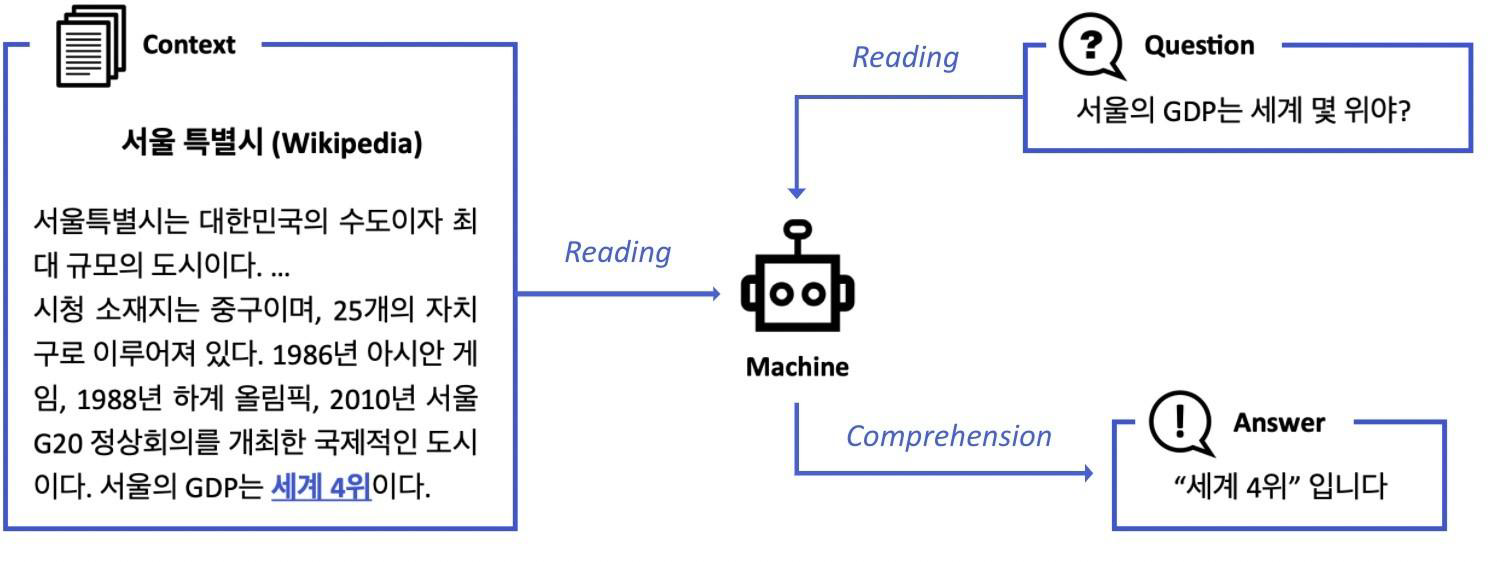
주어진 지문 (context)를 이해하고, 주어진 질의 (Query)의 답변을 추론하는 문제를 MRC라고 한다.
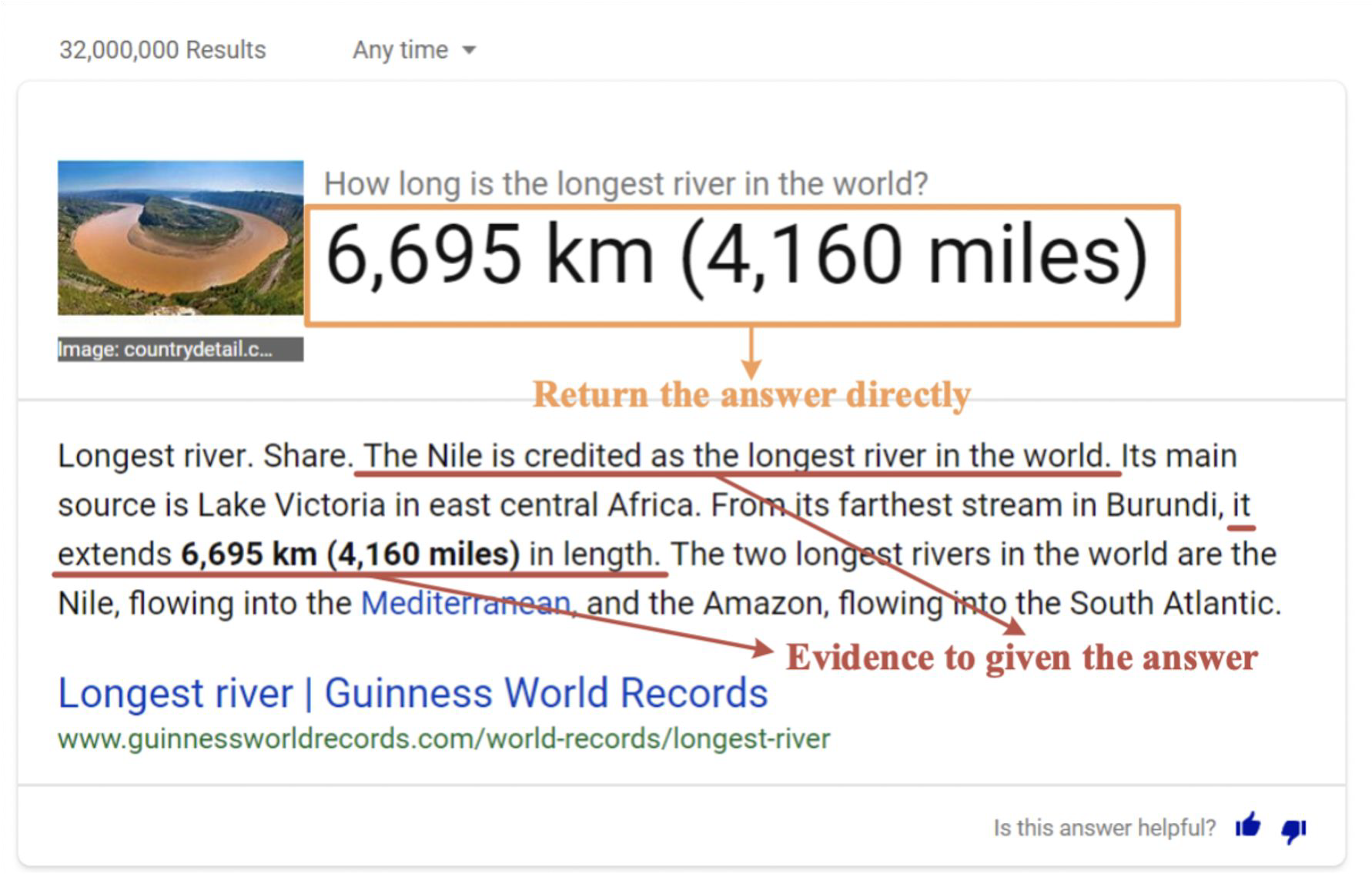
이는 검색엔진에서도 활용되는데, 만약 "세상에서 가장 긴 강의 길이는 얼마야?"라는 질의를 던지면, 위의 그림과 같이 6,695km (4,160 miles)라는 답을 해주면서 답을 찾은 지문을 함께 보여주고 있다.
MRC Datasets의 종류는 3가지로 분류할 수 있다.
1. Extractive Answer Datasets

Query에 대한 답이 항상 주어진 지문 (Context)의 segment (or span)으로 존재한다. 즉, 답이 반드시 지문 내에 존재해야만 정답으로 판단한다.
2. Descriptive/Narrative Answer Datasets

답이 지문 내에서 추출한 span이 아니라, query를 보고 생성된 sentence (or free-form)의 형태로 MS MACRO, Narrative QA 등이 있다.
3. Multiple-choice Datasets

Query에 대한 답을 여러 개의 answer candidates 중 하나로 고르는 형태로, MCTest, RACE, ARC 등이 여기에 포함된다.
Challenges in MRC
-
단어들의 구성이 유사하지는 않지만 동일한 의미의 문장을 이해하는데 한계가 있다.

-
Unanswerable questions

-
Multi-hop reasoning : 여러 개의 document에서 query에 대한 supporting fact를 찾아야지만 답을 찾을 수 있다. (ex. HotpotQA, QAngaroo)

MRC 평가 방법/지표
(1) Exact Match(EM)
해당 방식은 extractive와 multiple-choice answer datasets에서 사용되는 평가 방법이다.
예측한 답과 ground-truth 값이 정확히 일치하는 샘플의 비율
(2) F1 Score
해당 방식은 extractive와 multiple-choice answer datasets에서 사용되는 평가 방법이다.
예측한 답과 ground-truth 사이의 token overlap을 F1으로 계산한 것이다.
(3) ROUGE-L
해당 방식은 descriptive answer datasets에서 사용되는 평가 방법이다.
예측한 값과 ground-truth 사이의 overlap recall
LCS (Longets common subsequence) 기반
(4) BLEU (Bilingual Evaluation Understudy)
해당 방식은 descriptive answer datasets에서 사용되는 평가 방법이다.
예측한 답과 ground-truth 사이의 precision
KorQuAD Datasets
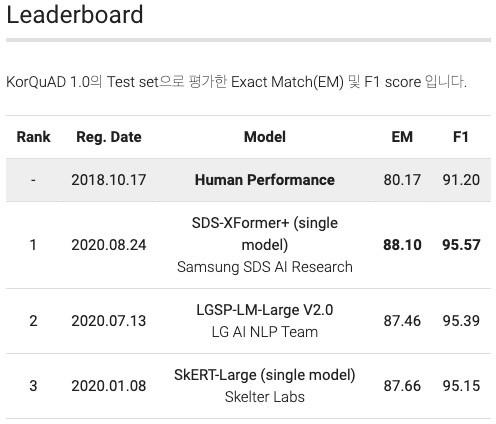
KoQuAD는 LG CNS가 AI 언어지능 연구를 위해 공개한 질의응답/기계독해 한국어 데이터셋이다. 이 데이터셋은 SQuAD v1.0의 데이터 수집 방식을 벤치마크하여 표준성을 확보했다.
특징은 다음과 같다.
- 1,550개의 위키피디아 문서에 대해서 10,649 건의 하위 문서들과 크라우드 소싱을 통해 제작한 63,952개의 QA 쌍으로 구성되어 있다. (Train 60,407 / Dev 5,774 / Test 3,898)
- 누구나 데이터를 내려받고, 학습한 모델을 제출하고 공개된 리더보드에 평가를 받을 수 있다. 이를 통해 객관적인 기준을 가진 연구 결과의 공유가 가능해졌다.
- 현재 v1.0과 v2.0을 공개되었는데, 2.0은 보다 긴 분량의 문서가 포함되어 있으며, 단순 자연어 문장 뿐만 아니라 복잡한 표와 리스트 등을 포함하는 HTML 형태로 표현되어 있어 문서 전체 구조에 대한 이해가 필요하다.
해당 데이터셋들은 HuggingFace datasets 라이브러리를 이용해서 사용할 수 있다.
from datasets import load_dataset
dataset = load_dataset('squad_kor_v1', split='train')이 라이브러리는 자연어 처리에 사용되는 대부분의 데이터셋과 평가지표를 공유할 수 있도록 만든 것으로, Numpy, Pandas, PyTorch, Tensorflow2와 호환이 가능한다. 접근 가능한 모든 데이터셋이 memory-mapped, cached 되어 있어서 데이터를 로드하면서 생기는 메모리 공간 부족이나 전처리 과정 반복의 번거로움 등을 피할 수 있다.
KorQuAD 예시


