Bias
- Inductive bias : 학습 시, overfitting을 막거나 사전 지식을 주입하기 위해 특정 형태의 함수를 선호하는 것을 의미한다.
- Historical bias : 현실 세계가 편향되어 있기 때문에 모델에 원치 않는 속성이 학습되는 것을 의미한다.
- Co-occurence bias : 성별과 직업 간 관계 등 표면적인 상관관계 때문에 원치 않는 속성이 학습되는 것을 의미한다.
- Specification bias : 입력과 출력을 정의한 방식 때문에 생기는 편향이다.
- Sampling bias : 데이터를 샘플링한 방식 때문에 생기는 편향이다.
- Annotator bias : annotator의 특성 때문에 생기는 편향이다.
Bias in ODQA
여기서는 Reader 모델에서의 bias의 초점을 맞추고 다룰 것이다.
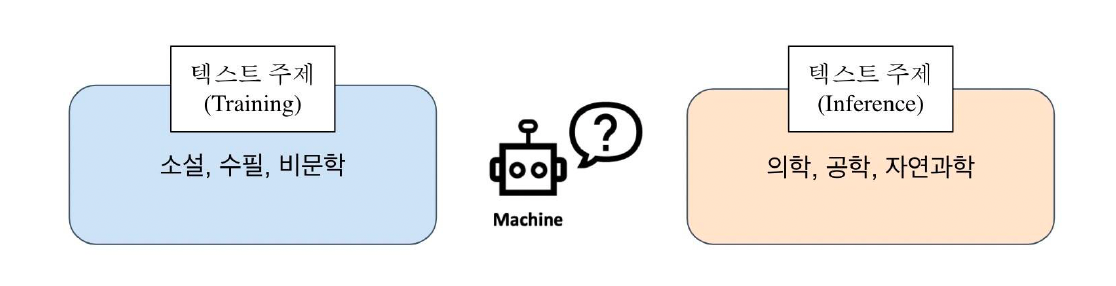
만약 Reader 모델이 한정된 데이터셋에서만 학습이 된다면, Reader는 항상 정답이 문서 내에 포함된 데이터쌍 (Positive)만 보게 될 것이다. 특히 SQuAD와 같은 데이터셋은 Context, Query, Answer가 모두 포함되어 있기 때문에 positive가 완전히 고정되어 있다.
그렇다면 추론할 때, 데이터 내에서 찾아볼 수 없었던 새로운 문서를 주게 된다면, Reader 모델은 문서에 대한 독해 능력이 매우 떨어질 것이고, 결과적으로 정답을 내지 못할 것이다. 즉, 소설, 수필, 비문학 관련된 주제에 대해서만 학습이 된 모델이고, 의학, 공학, 자연과학 주제를 추론 시 주게 된다면, 성능이 굉장히 떨어질 것이다.
How to mitigate training bias?
그러면 어떻게 해야 학습 과정에서 발생하는 bias를 줄일 수 있을까?
(1) Train negative examples
학습 과정에서 잘못된 예시도 함께 보여주어야 Retrieval가 negative한 내용들을 먼 곳에 배치할 수 있다. 여기서 negative sample도 완전히 다른 negative와 비슷한 negative의 차이에 대한 고려도 해야 한다. negative sampling 방식에 대해서는 이전 포스팅에 자세히 설명되어 있으니 참고하길 바란다.
(2) Add no answer bias
입력 시퀀스의 길이가 N일 때, 시퀀스의 길이 외 1개의 토큰이 더 있다고 생각하는 것이다. 즉, 훈련 모델의 마지막 레이어 weight에 훈련 가능한 bias를 하나 더 추가하는 것이다. Softmax로 answer prediction을 최종적으로 수행할 때, start end 확률이 해당 bias 위치에 있는 경우가 가장 확률이 높으면 이는 "대답할 수 없다"라고 취급하는 것이다.
Annotation Bias from Datasets
