Decoder-Only Model의 특징
- Auto Regressive : 이전에 생성된 토큰을 기반으로 한 순차적 예측
- Self-Attention : 시퀀스 내 단어들 간의 관계에 집중
- Causal Masking : 이후 토큰을 차단하여 순차적 생성 순서를 보장
LLaMA
- Meta에서 출시한 오픈소스 LLM
- AutoRegressive Decoder-Only Model
- LLaMA 1, 2, 3, 3.1, 3.2 까지 출시됨
- LLaMA 3.2 VLM Model은 text와 vision tasks, multimodal 까지 가능하기 때문에 이미지 QA Task도 수행할 수 있다.
LLaMA 3 아키텍처
- Decoder-only 모델 기반
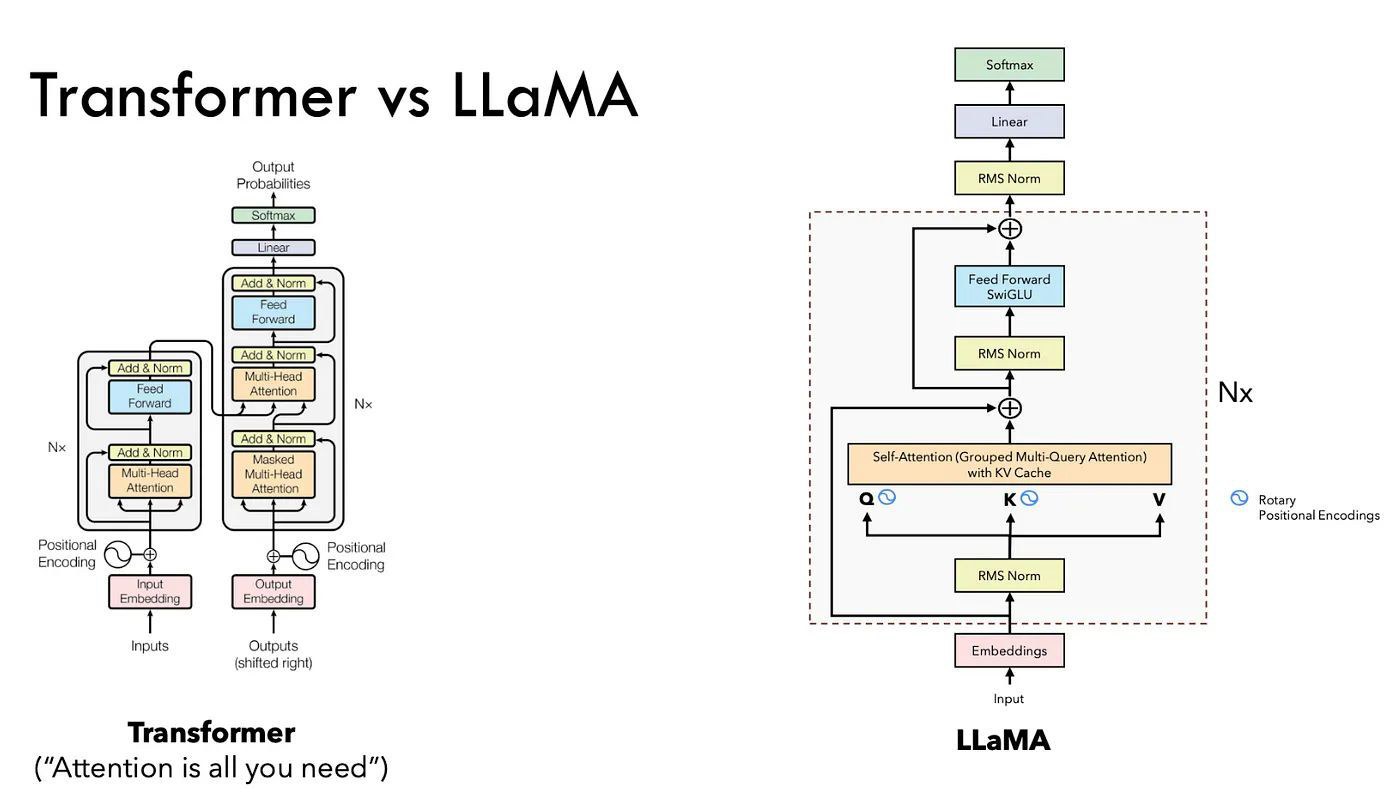
- Transformer와 같이 기존에는 단어(임베딩)를 그대로 넣어서 위치 정보를 추가해주는 방식이었던 반면, LLaMA 3는 RoPE(Rotary Positional Encoding) 방식을 채택하여 동작한다.
- Attention machanism 안에 Q, K 부분에만 한정하여 위치 정보를 추가적으로 넣어준다.
- 즉, attention layer 마다 계산이 될 때마다 rotary positional embedding 정보를 같이 계산해주면서 상대적인 정보와 절대적인 정보를 함께 이해하는 방식으로 작동한다.
- 또한 기존에는 Multi-head attention 이후에 Normalization 값을 처리해주었지만, LLaMA 3는 Attention 계산하기 이전에 Layer Normalization을 간소화하여 RMS Norm 방식을 사용한다.
- Residual 하고 RMS Norm을 취해준 후, SwiGLU(Swish+GLU) 방식을 통해 좀 더 똑똑하게 데이터를 저장할 수 있는 메커니즘으로 동작한다. 그 후, Residual을 해준다.
- 마지막으로 RMS Norm을 한 후, nn.Linear 즉, LM Head로서 hidden vector로부터 나온 output들을 softmax에 넣어주어 나온 확률값으로 next 토큰을 맞추는 방식으로 동작한다.
LLaMA Key components
- RoPE
- Multi-Headed Attention (FFN) + GQA
- Multi Layer Perceptron
- RMS Normalzation
- Flash Attention 2

✨🐰🫧