본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
Decoder-Only Model
GPT (Genreative Pre-trained Transformers)
- Causal Language Model 방식으로 학습이 됐다.
- 이는 앞 토큰 및 문맥을 통해서, 그 이후의 토큰을 예측하는 "Next Token Prediction" 방식을 통해서 학습되는 것을 의미한다.
- BERT 모델과 달리 모델을 학습한 것과 실제로 사용하는 것이 완전히 동일하기 때문에 생성형 Task에 강점을 가진다.
- GPT 모델은 모든 토큰을 활용하여 실제로 예측하기 때문에 100%의 성능을 끌어와 사용할 수 있다.

Decoder-only 모델의 발전
모델 사이즈를 GPT-2의 1B 스케일을 넘어서 훨씬 더 큰 스케일로 확장한 결과를 아래의 그림에서 확인할 수 있다.
-
Emergent Abilities (Model Size, Training Flops)
-
모델 사이즈를 증가하고, 학습 사이즈를 늘리는 것에 따라서 모델의 성능이 폭발적으로 증가하는 때가 있다는 것을 의미
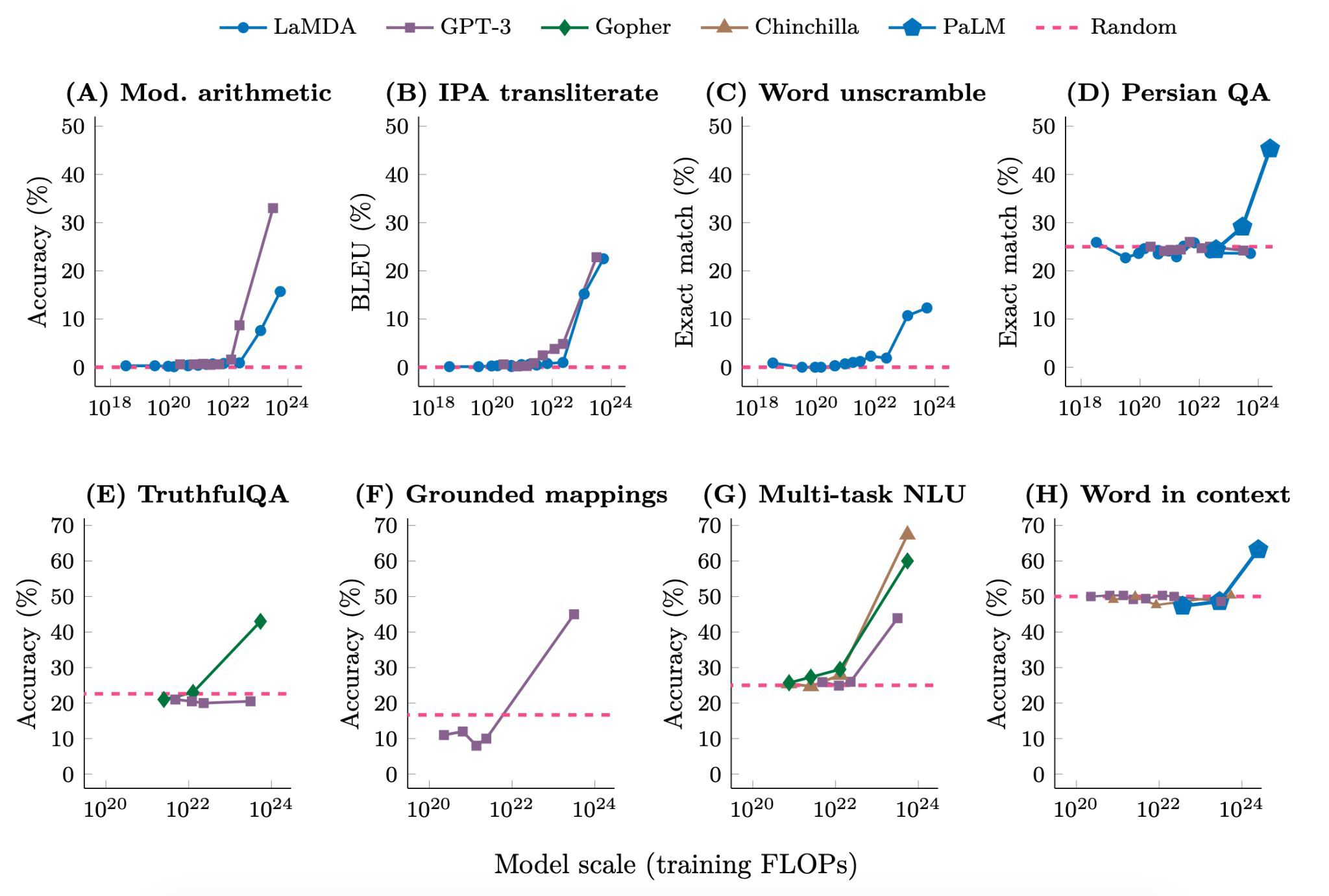
-
모든 모델에서 100B이 넘어설 때부터 성능이 급격하게 좋아진다.
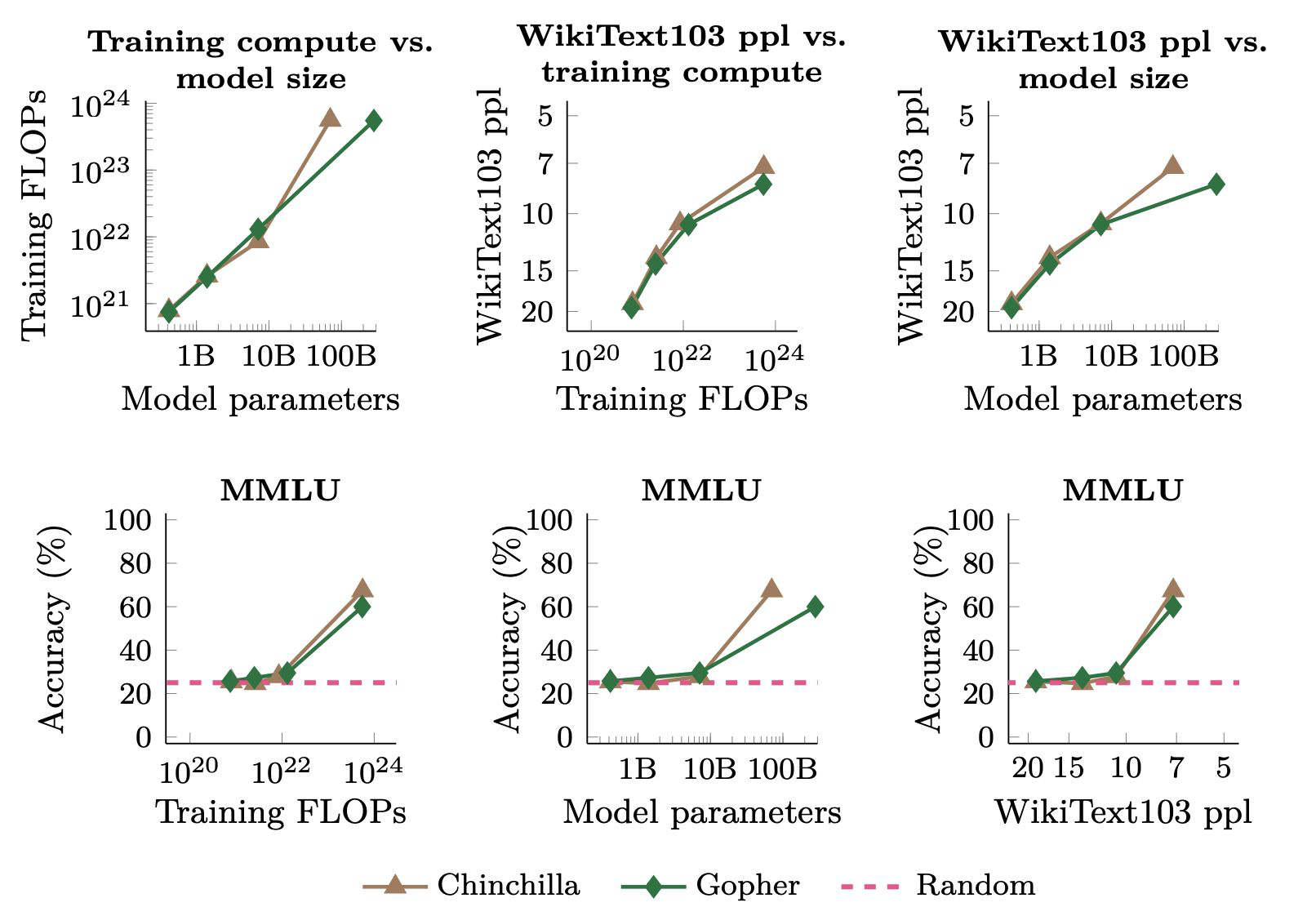
Emergent Abilities of Large Language Models -
MMLU : 언어 지식을 이해하는 평가 데이터셋
-
학습을 얼마나 하고, 모델 파라미터에 따라 성능의 변화를 확인했을 때, 100B 이상에서 성능이 급격하게 뛰는 것을 확인할 수 있다.
-
Emergent Abilities (Few Shot Learning)
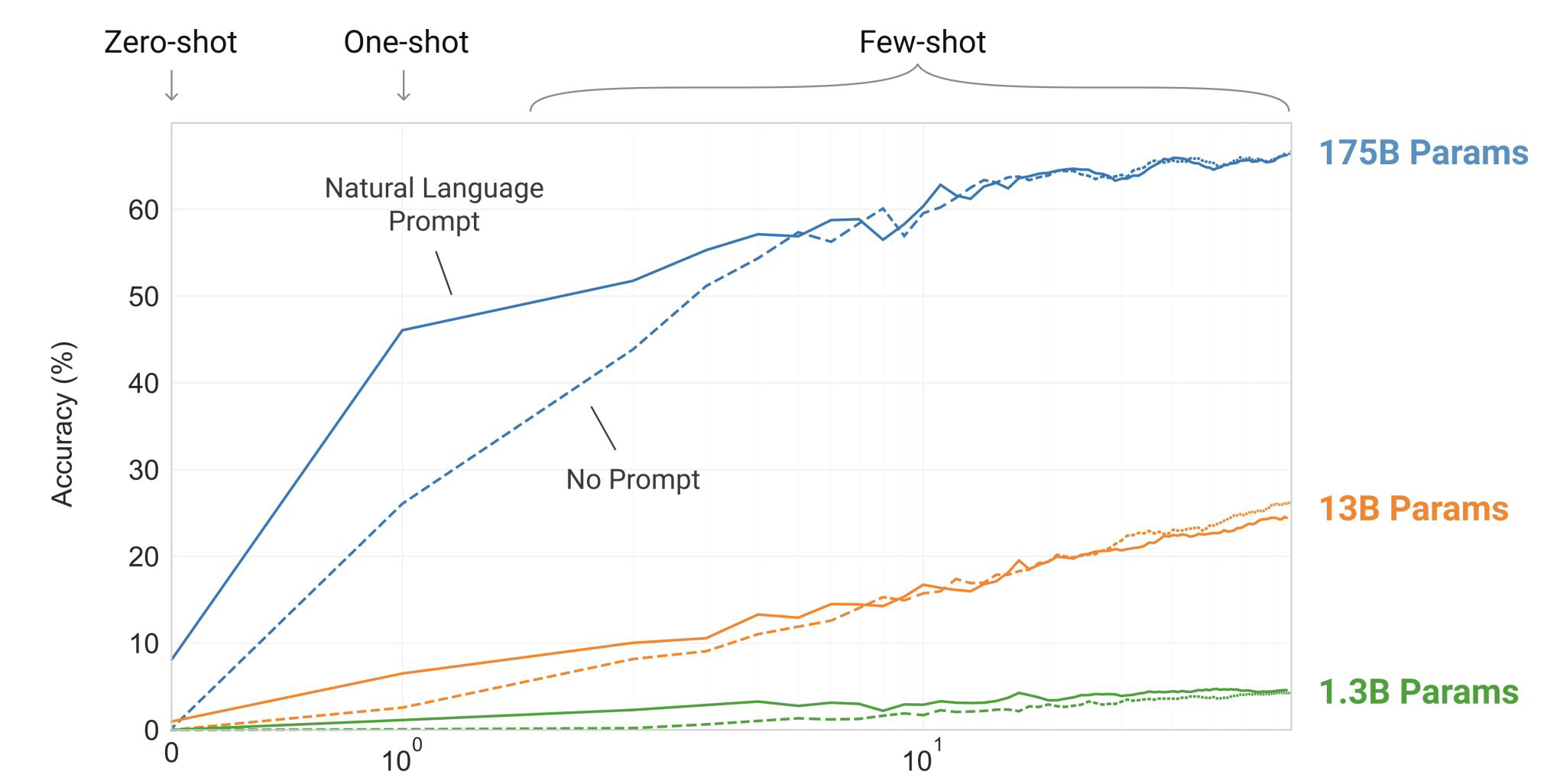
-
Zero-shot 일 때는 모델이 10% 정도밖에 맞추지 못하는 상황
-
One-shot으로 주었을 때, 1.3B와 13B에서는 zero-shot과 거의 차이가 나지 않았지만, 175B에서는 정답률이 약 40% 향상
-
Few-shot(10개)을 주었을 때도, 175B에서만 성능이 꾸준하게 상승되는 것을 확인할 수 있음
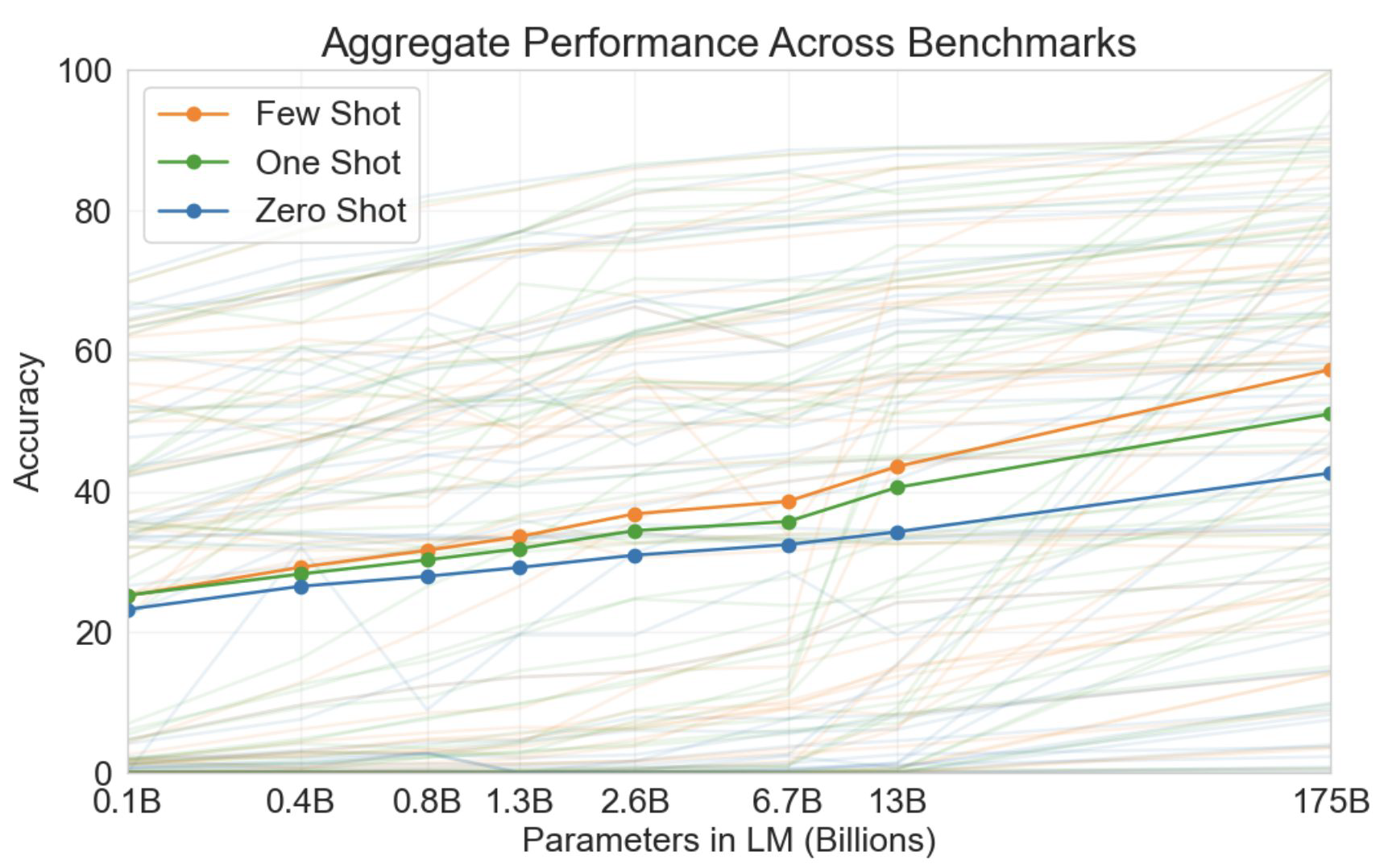
Language Models are Few-Shot Learners
- 다양한 언어 모델을 벤치마킹 했을 때도 공통적으로 나타나는 현상
Decoder-only 모델 성능
- MMLU Benchmark는 NLU Task에서 언어를 얼마나 잘 이해하는지 테스트하기 위해서 만들어진 것
- MMLU는 Encoder 모델을 찾아볼 수 없고 대부분 Decoder-only 모델이다.
- Generation Task에서 아주 좋은 성능을 보인다.
- NLU Task(스팸 분류, 감정분류)에 있어서도 훨씬 쉽게 문제를 잘 풀고 있다. 큰 모델의 경우, fine-tuning 없이 few-shot 예제만 잘 넣어주어도 충분히 수행이 가능하다.
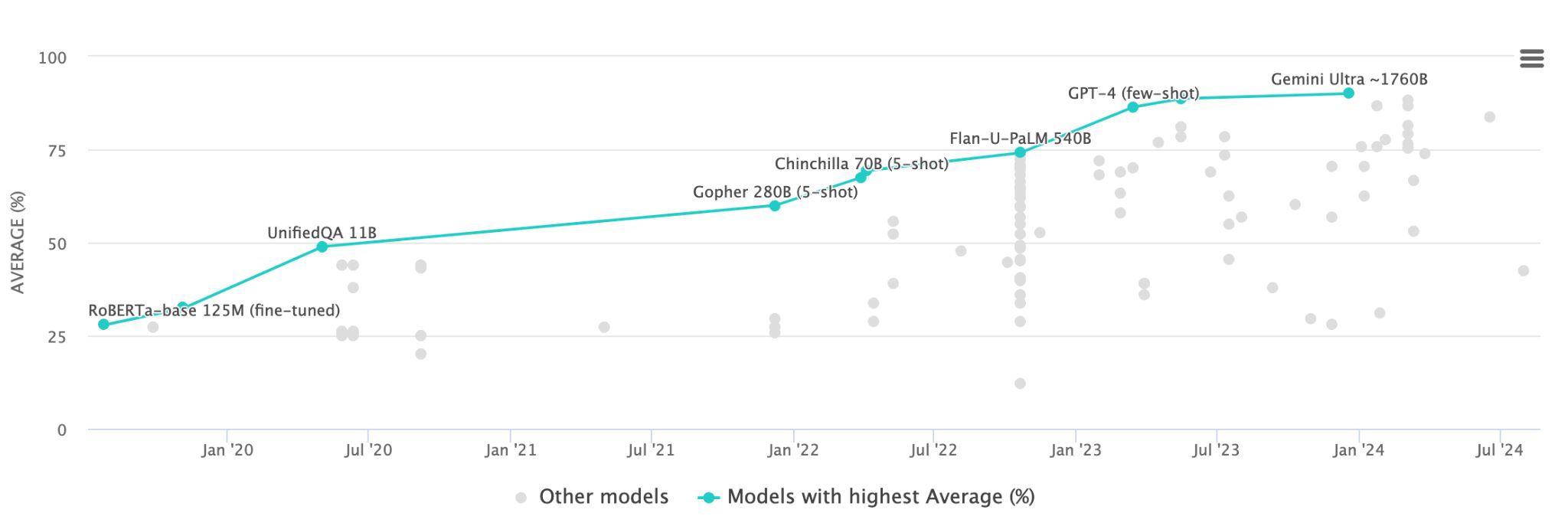
- 최근으로 갈수록 90점이 넘는 성능을 보여주고 있다.
- 언어모델 입장에서 benchmark들이 쉽게 느껴지기 때문에, 좀 더 어려운 benchmark들을 만들어주는 방향도 고려되고 있는 상황이다.
LLM
Decoder-only 모델에서 파라미터 수를 엄청나게 많아진 큰 모델을 LLM이라고 부른다.
LLM(decoder-only) 장점과 성능
- 효율성 : Encoder-Decoder 모델보다 힉습 및 추론 속도가 빠르고 scaling up에 강점을 가진다.
- In-Context Learning : 생성 기반 pre-training을 수행함으로써 입력 텍스트를 기반으로 출력 텍스트를 보다 잘 생성이 가능하다.
- 예를 들어, MLM 같은 경우 1TB 크기의 데이터셋 중 15%만 [MASK]를 해주고 학습을 해주는 처리를 하기 때문에 중간 처리 과정이 있는 반면, CLM은 동일한 크기의 데이터셋 중 100%를 모두 가져다 학습을 할 수 있다.
- 생성을 기반으로 대부분의 Task를 잘 수행해낸다.
- 현실적으로 보조 역할을 잘 해내고 있다.
In-Context Learning
1. Few-shot learning

Language Models are Few-Shot Learners
- 언어모델 자체가 그 다음 토큰을 맞추고, 이전 토큰들에 대해서 모두가 attention을 걸고 있어 독립적으로 이해할 수 있기 때문에, 그 다음에 토큰에 무엇이 들어올지 확률을 높여주는 것으로서 성능을 높여줄 수 있다.
2. CoT (Chain-of-Thought)
- 단순히 예제를 보여주는 것만으로 문제를 풀게할 수 없기 때문에, CoT 방식을 활용한다.
- 모델이 바로 답변을 하는 것이 아닌, 생각을 하고 답변을 할 수 있도록 하는 방식
- 상대적으로 어려운 Reasoning Task에서도 Decoder Model이 강력한 성능을 발휘하기 시작하고 있는 추세이다.
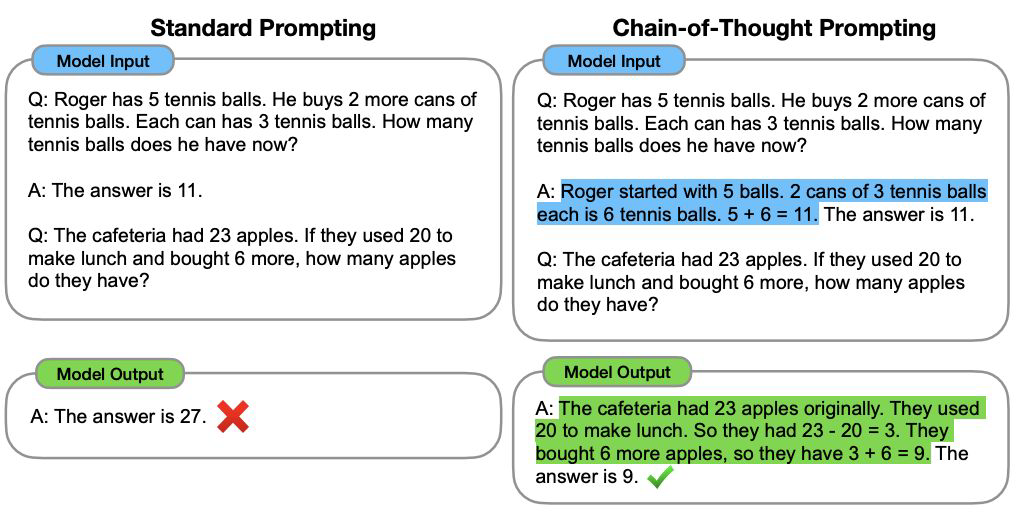
Chain-of-Thought Prompting Elicits Reasoning
in Large Language Models - 정답을 내기 전에, 정답인 이유에 대해 먼저 처리를 해주는 부분을 넣어주는 것
- 생각하는 토큰을 생성하게 함으로써, 정답에 좀 더 가까워질 수 있도록 유도하는 방식
- 이를 통해 정답률을 높일 수 있다.
In-Context Learning에 따른 LLM 성능 비교
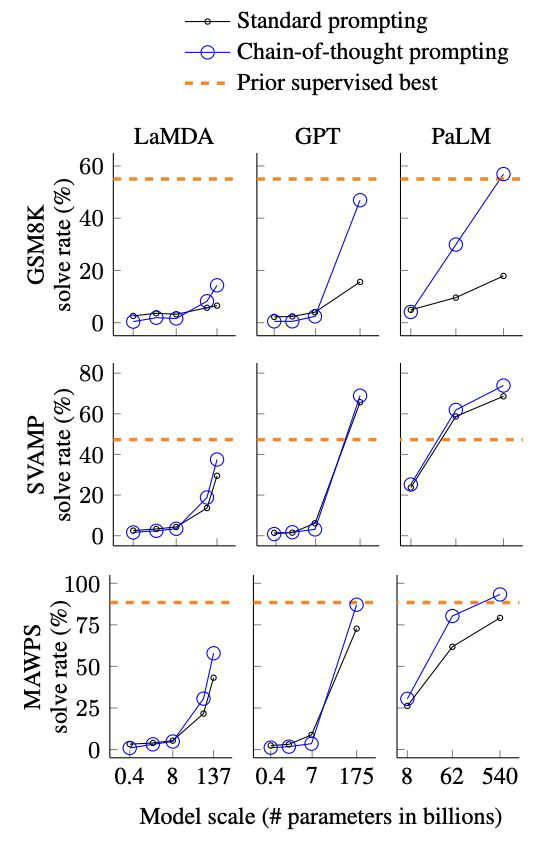
- 위의 그래프에서 확인할 수 있다시피, Standard Prompting에 비해 CoT 기법을 넣어준 것이 높은 성능 개선을 보였다.
- 또한 모델 사이즈가 커짐에 따라 더 큰 성능 개선이 보인다.
Human Alignment
1. Instruction Tuning
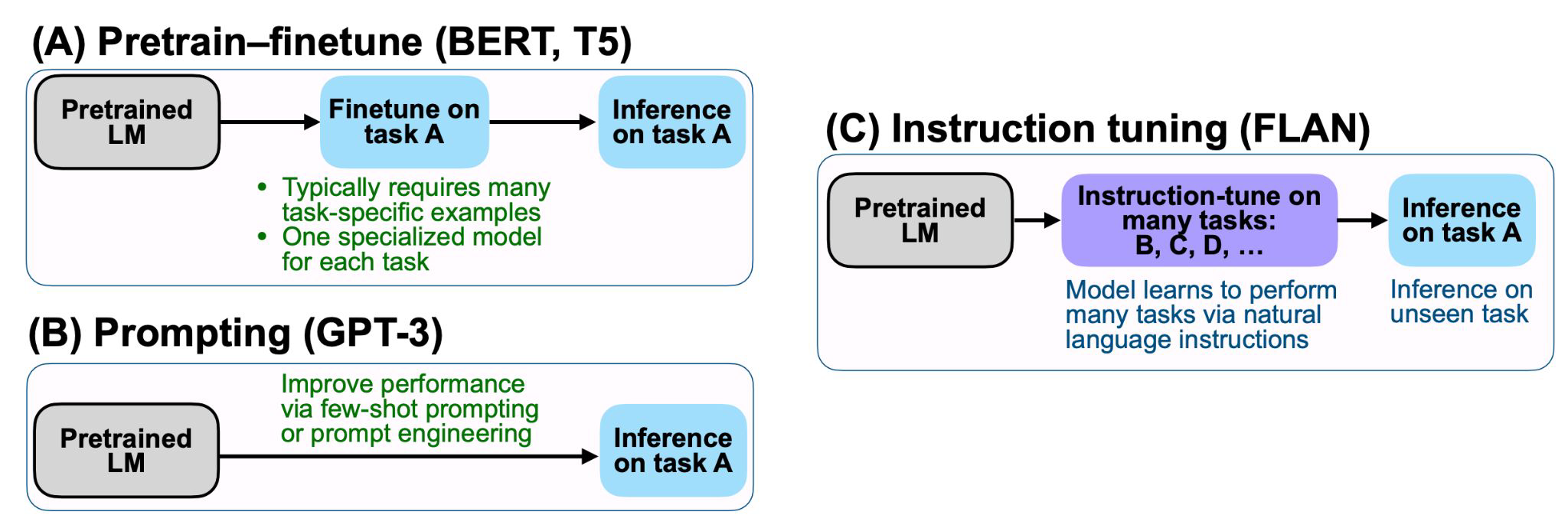
Fintuned Language Models Are Zero-Shot
Learners
- 위의 그림에서 BERT, GPT-3와 달리 Instruction tuning은 zero-shot으로 예제를 하나도 주지 않고, 오로지 명령만 전달하고 정답을 내도록 하는 방식이다.
2. RLHF (Reinforcement Learning from Human Feedback)
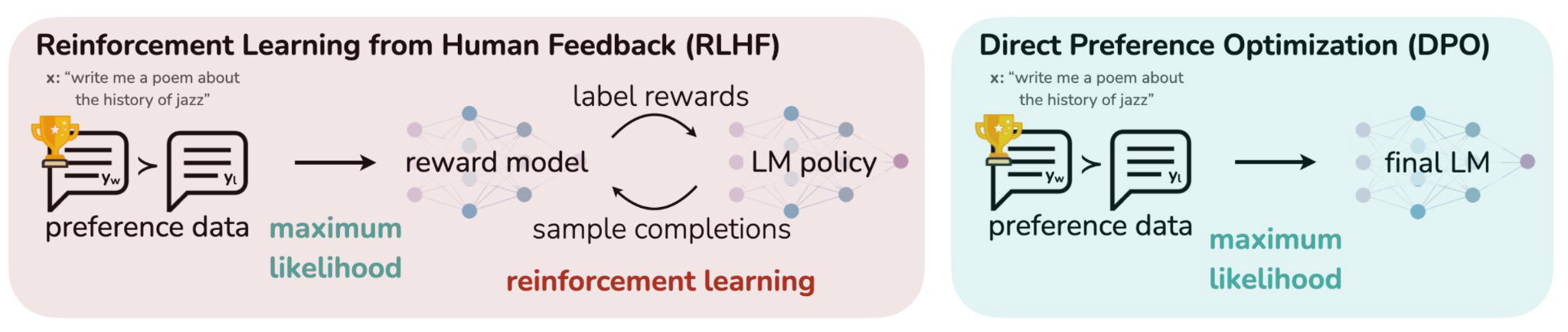
Direct Preference Optimization:
Your Language Model is Secretly a Reward Model
- 사람의 평가(human feedback)를 최대화하기 위해 강화학습을 도입한 개념
- 기존 instruction에서 사람이 좀 더 선호하는 답변을 내기 위해 일종의 점수를 내는 reward model을 추가한 방식이다.
- 기존의 SFT나 IFT 모델을 가지고, reward를 더 잘 받도록 학습을 시켜준다. 이 과정이 reinforcement learning이라고 부른다.
- DPO는 강화학습을 쓰지 않고 비슷한 효과를 내는 방식이다. 데이터는 완전히 동일하지만 final LM을 만들 때, reward model을 사용하지 않고, 데이터만으로 모델을 바로 학습시키는 방법론이다.
LLM의 성능
- 데이터를 생성할 때, 똑같이 Instruction set을 만들어주고, 모델 A와 B가 생성한 결과 중 어떤 것이 좋은지 평가 진행
- 선택한 모델에 따라, 앞으로 어떻게 학습을 더 집중적으로 진행할지 판단하게 된다.
Chatbot Arena
