본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
LLM 평가
LLM은 굉장히 범용적이기 때문에, Translation, QA, Bias, Hallucination, Math 등 여러 분할된 Task를 종합적으로 확인해야 한다. 아래의 표처럼 각 Task 별로 다양한 평가지표가 존재하고 정량적인 평가를 수행한다.
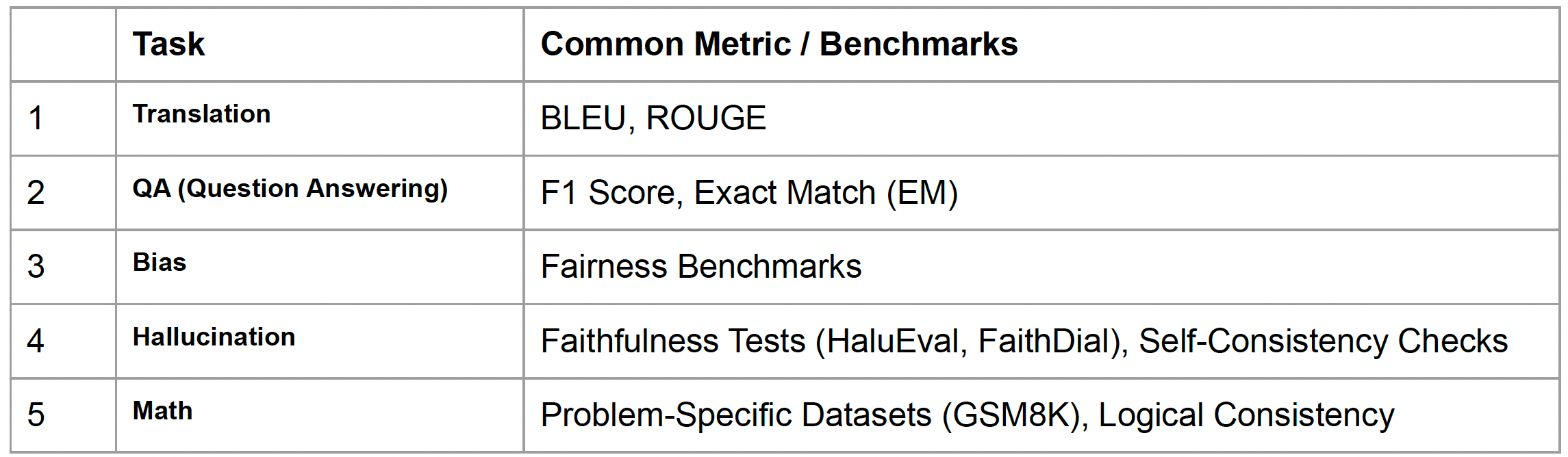
1. Translation
- n-gram 일치 비율로 점수를 산정
- 정답 텍스트가 'The cat is on the mat'이고, 생성된 텍스트가 'The cat is on a mat'이라면, 점수는 The cat is on이 겹치기 때문에 높은 점수를 부여할 수 있다. (만약 1-gram으로 평가할 경우에는 mat도 정답으로 인정 가능)
- QA
- 질문에 대해 답변을 정확하게 했는지 아닌지 여부를 판단하고, F1 Score와 EM을 평가지표로 사용한다.
- 정답 텍스트가 'The capital of France is Paris'이고, 생성된 텍스트가 'The capital of France is Lyon'이라면, F1 Score는 일치하는 단어를 기반으로 약 0.8 정도의 점수를 부여하고, EM은 모든 텍스트가 완벽하게 일치하지 않기 때문에 0점을 부여한다.
- Bias
- 모델이 편향되었는지 아닌지를 확인하는 지표로 Fairness Benchmarks를 사용한다.
- 예를 들어 이름이 포함된 이력서에서 특별 성별의 이름이 포함된 이력서를 더 많이 선택하는 경우, 성별에 대한 bias가 존재한다고 판단할 수 있다.
- Hallucination
- Faithfulness Tests로 평가하거나, Self-Consistency로 체크를 한다.
- Faithfulness의 경우 답변이 진실한지 아닌지를 판단 즉, 생성된 텍스트가 원본 데이터나 맥락에 충실한지를 평가한다.
- Self-consistency는 동일한 질문에 대해 일관된 답변을 하는지를 평가한다.
- Math
- GSM8K는 수학적 문제 해결 능력 테스트를 위한 데이터셋으로, 모델이 reasoning한 답변을 내는지 평가한다.
- Logical consistency는 논리적 일관성을 평가하는 metric이다. 명확히 규명된 방식은 없지만 가이드에 따라 human evaluation 또는 LLM evaluation을 수행할 수 있다.

- 최근에는 human alignment를 통해 인간의 선호도와 얼마나 부합하는 지에 대해 LLM을 평가한다.
- 사람이 각 모델들의 출력 결과를 보고 A/B Test를 통해 직접 투표하여 점수를 산정한다.
평가 프로세스
평가 목적
- NLU
- NLG
- LLM
- Domain-Specific
평가 데이터셋
- 평가하기 위한 데이터셋인 benchmark dataset을 활용한다. 목적에 맞는 다양한 벤치마크 데이터셋을 선정하여 평가할 수 있다.
- 대표적으로 GLUE, SQuAD, ARC, HellaSwag, OpenSource LLM Leaderboard(huggingface)
평가 방식
- Automatic Evaluation
- Metric 기반 평가
- LLM-as-a-judge
- Human Evaluation
- 사람이 특정한 가이드라인을 기준으로 LLM의 응답을 직접 평가하는 방식
- 전문적인 내용을 다루는 법률, 금융, 의료 등 특정 Task에 있어서 사람이 평가하는 것이 유의미하다. 또한 주관적인 내용이나 어투나 자연스러움 등과 같은 뉘앙스를 잡아내기 용이하며, 윤리적인 문제도 함께 고려가 가능하다는 장점이 있다.
- 그러나 비용이 많이 들고, 가이드라인이 주어지더라도 사람마다 판단하는 기준이 달라서 일관성이 없다는 단점이 있다.
LLM 기반 평가
모델 기반 평가
- 임베딩 기반
- BERTScore : Encoder 모델을 활용하여 임베딩을 만든 후, 유사도를 계산하는 방식으로 정수를 뽑아낸다. (Semantic Similarity)

BERTSCORE: EVALUATING TEXT GENERATION WITH BERT - Reference 데이터가 있고, 데이터셋에 대해 평가를 진행할 때, BERT 모델에 foward로 통과를 시키고 pairwise cosine similarity를 계산한다.
- 각 pair로 구한 유사도로 maximum similarity를 뽑아내고, importance weighting을 함께 수행해주면 reference와 candidate 간의 유사도 점수를 구할 수 있다.
- 확률 기반
- GPTScore, FFLM 등
- 언어 모델이 다음 토큰의 생성 확률을 가지고 있기 때문에 conditional probability를 계산하여 점수를 산출한다.
- 텍스트의 품질이 높고, 정답에 가까울수록 likelihood가 높다는 가설 하에 더 확신을 가지고 next token을 예측할수록 더 좋은 텍스트라고 판단한다.

Prompting LLMs
- 각 Task에 대해서 instruction과 criteria 등을 프롬프트에 삽입하여 LLM이 직접 평가를 수행한다.
- 대표적으로 두 가지 방식이 있는데, 두 개의 response 중 선호하는 형태를 선택하는 방식과 각 response를 지침에 따라 점수를 출력하는 방식이 있다.

LLM-based NLG Evaluation: Current Status and Challenges - 이 방식의 큰 문제점은 API 비용의 문제와 생성을 매번 동일하게 하지 않는다는 재현성의 문제를 가지고 있다는 점이다.
Fine-tuning LLMs
- LLM 자체를 OpenSource 모델을 평가 전용 모델로서 fine-tuning을 수행하여 점수를 맞추도록 한다.
- 고품질의 평가용 데이터를 생성하고 이를 활용하여 모델을 튜닝
Human-LLM Collaborative Evaluation
- LLM 평가와 인간 검수를 유기적으로 연결하여 평가 시스템을 구축하는 방식으로, COEVAL, AdaTest, AdaTest++ 등이 있다.

- Task description과 LLM에 대해서 평가 기준(criteria)을 세운 후, 사람이 맞는지 아닌지 평가를 진행하고, 이 결과들을 LLM에 계속해서 제공해주면서 유기적으로 연결하는 과정을 거친다.
- 그럼에도 불구하고 아직도 자동으로 평가를 해주는 LLM 기반의 평가를 선호하고 있는 추세이다.
LLM 기반 평가의 한계

- 위치에 따른 선호 편향이 발생한다. 이는 프롬프트에서 정답 문서를 어디에 위치하느냐에 따라 실제 정확도 정도가 달라진다.
- 또한 response의 순서에도 영향을 받아서 일관성이 없는 답변을 낼 가능성이 있다.

- 또한 모델 자체가 길이가 긴 output 자체를 선호하는 경향이 있다.
- 위의 그래프에서도 확인할 수 있다시피 길이가 짧은 것보다 긴 것에서 높은 score가 책정된다.
- 그 외에도 평가 모델과 같은 모델이 생성해내는 응답을 더 선호하는 경향, 수학이나 reasoning은 채점을 잘하지 못한다는 단점들이 존재한다.
최신 LLM Benchmark
Chatbot Arena
- 두 모델의 응답을 모두 사람이 선택한다.
- 선택된 응답에 대해서 승리 점수를 채점한다. 즉, 높은 점수의 모델을 이길 경우 높은 승리 점수를 획득하고, 낮은 점수의 모델에게 패배할 경우 많은 점수를 잃는 형태로 진행한다.
WildBench
- OpenAI API를 연동하여 WildChat Dataset을 기반으로 실제 사람이 작성한 instruction을 제공한다.
- 이 instruction을 기반으로 WildBench를 만드는데, wildchat dataset을 curation 하여 1024개의 데이터로 데이터셋을 생성한다.
- 이에 기반하여 Elo Score에 각각 비교하게 되고, InfoSeek, Creative, Code&Debug, Math&Data, Reasoning 항목을 통해서 점수를 채점한다.
Open Ko-LLM Leaderboard v2 (한국어 벤치마크)
- Open LLM Leaderboard (Global)의 내용을 한국어 형태로 변환하여 제공한다.
- v2는 KorNAT 데이터셋을 추가하여 한국 문화를 고려하는지 확인한다.
- LLM's Practical Abilities and Realibity에 초점을 맞춰 데이터를 추가한다.
LC(Length-Controlled) AlpacaEval
-
Chat Arena와 얼마나 상관관계가 높은지 보여주는 benchmark이다.

-
기존의 AlpacaEval에서 길이에 대한 편향을 보정한 것으로, Human Correlation이 약 0.98로 사람이 평가한 것과 거의 유사하다라는 것을 보여준다.
-
AlpacaEval(LLM 기반 자동 평가)은 모델들의 응답 결과와 GPT-4-turbo(baseline) 응답 사이의 Binary 선호를 선택하여 WinRate를 계산하는 방식이다.
-
LC AlpacaEval은 AlpacaEval에서 나온 점수를 활용하여 GLM(Generalized Linear Model)을 학습하는 방식이다.
-
여기서 GLM 학습은 Win Prob(Model)이나 Length Affect(Length), Difficulty of Instruction (Instruction)을 포함하여 수행한다.
-
추론 시에 Length Affect를 제거하여 점수를 재설정한다.
평가 데이터셋을 만들 때 주의할 점
- LLM은 복잡한 질문에 대하여 정확도가 낮아지는 경향이 있다. LLM이 패턴 인식에는 강점을 가지지만 추론 부분에 한계를 가지기 때문에 복잡한 추론 문제를 포함하는 평가셋을 만드는 것이 좋다.
- 또한 문맥이 길어질수록 초기 정보를 잊어버리거나 중요한 정보를 잊어버릴 가능성이 높기 때문에, long context를 처리하는데 어려움이 있다.
- 대화 주제가 빠르게 바뀌는 경우, 그 흐름을 따라가지 못할 가능성이 있으므로, 문맥 전환과 같은 어려운 시나리오의 데이터를 포함하는 것이 좋다.
- 이렇게 LLM은 다양한 bias가 존재하기 때문에 이 부분을 고려하여 데이터셋을 만드는 것이 좋다.
- Order bias에 대해서는 A/B Test 수행 시 순서를 무작위로 섞고, 랜덤 시드를 다르게 설정하여 완화할 수 있다.
- Length bias에 대해서는 LC Alpaca 방법과 같이 길이를 보정한 형태로 점수를 수정함으로써 완화할 수 있다.

✨🐰🫧