본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
Long Context Models
Long Context LLM
-
In-Context Learning 같은 경우, few-shot을 사용하는데 이 자체가 input context로 사용되기 때문에, context의 길이가 길어야 더 좋고 충분한 예시를 넣어줄 수 있다.
-
따라서 long context에 대한 수요는 점점 많아지고 있고, RAG의 경우에도 문서를 input으로 넣기 때문에 long context가 필요하다.
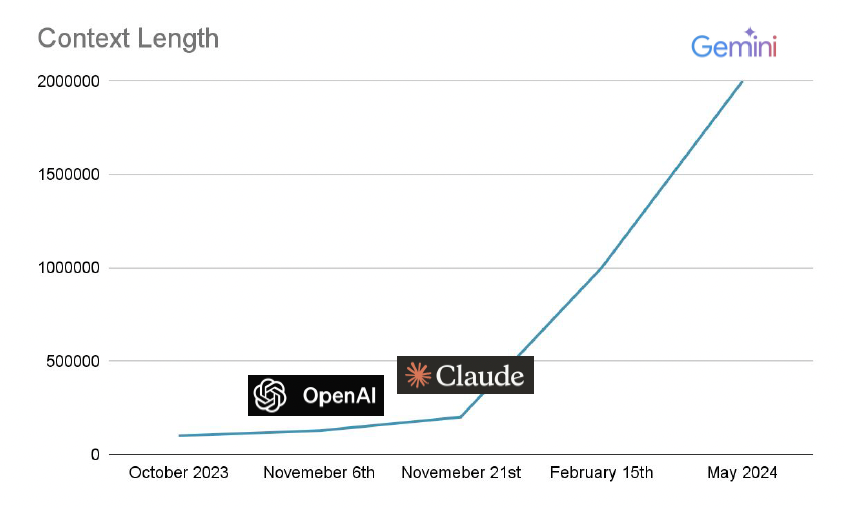
-
기존 모델에 long contetxt input을 사용하게 되면 train 데이터보다 input이 더 길기 때문에 낮은 성능을 보일 것이며, 연산 복잡도가 증가하여 메모리의 사용량이 계속해서 높아질 것이다. (sequence length가 배수로 함께 계산)
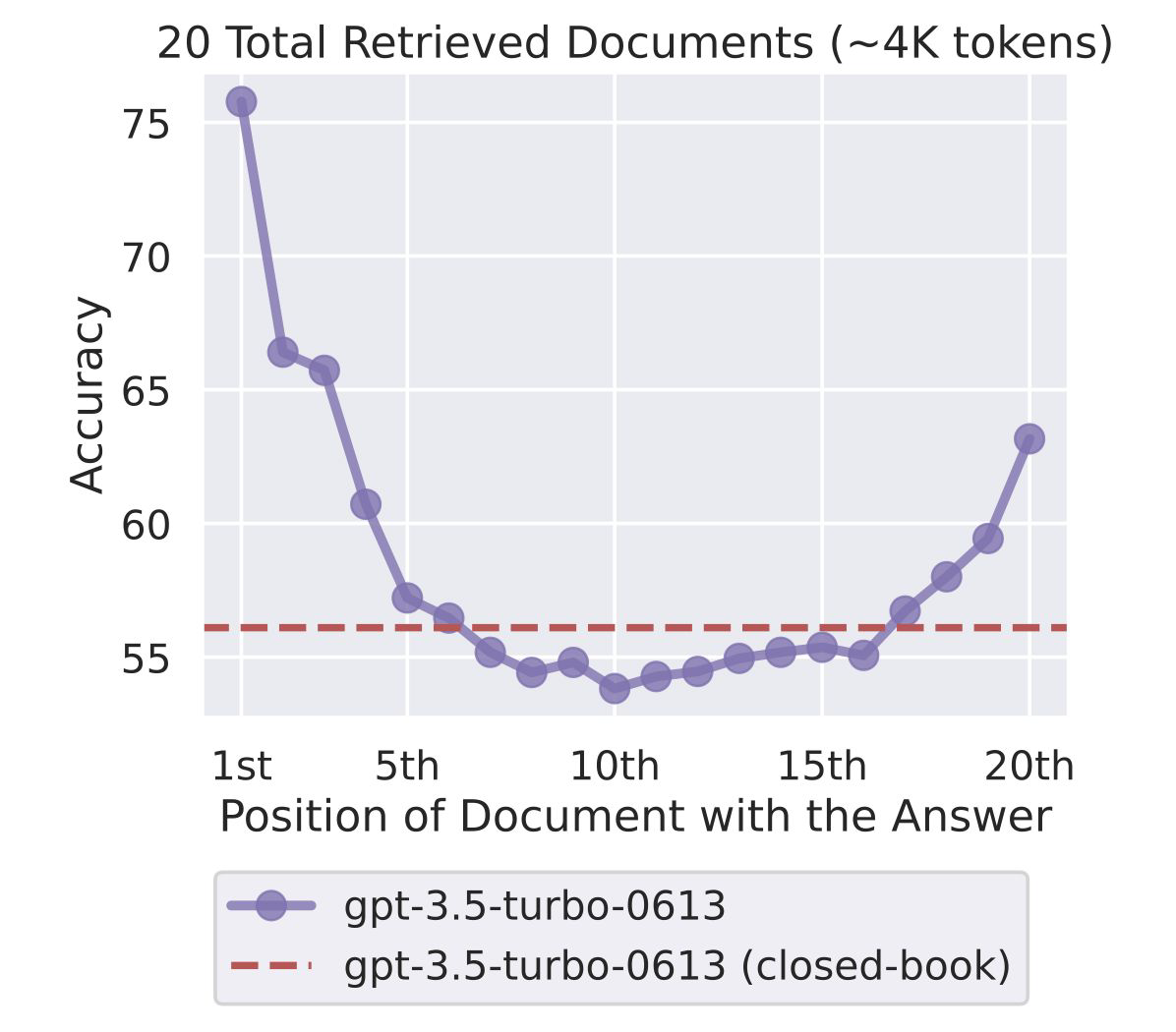
- Lost in the middle : 위의 그림과 같이 관련된 정보가 context 중간에 위치할 때, 처음이나 끝에 위치할 때에 비해 낮은 성능을 보인다.
Positional Embedding
1. Absolute Position Embedding
- 고전적인 Transformer 아키텍처에서 고정적인 Positional encoding을 사용하여 문장 내 토큰 위치 정보를 제공했다.
- 만약 512의 길이로 학습을 했다면 513번째 token을 줄 때, 해당 토큰에 대한 정보는 아예 존재하지 않는 것이다. 그러면 모델의 성능이 완전히 떨어지게 된다.
- 또한, token의 상대적인 위치 정보를 고려하지 못한다는 단점도 가진다.
2. Relative Position Embedding
- absolute position embdding이 가지는 단점을 해결하기 위해 나온 방식
- 가까운 토큰에 대해서는 가깝다는 정보, 먼 토큰에 대해서는 멀리 있다는 정보에 대해서만 제공하고, absolute에 대한 정보는 없다 보니 시작하는 토큰에 대한 정보를 제공하기 애매하다.
- 따라서 속도가 느리고, 메모리를 많이 사용한다는 단점이 있다.
3. RoPE (Rotary Position Embedding)
- Absolute와 Relative position embedding의 장점을 합친 방식
- token embedding을 위치 index(theta)만큼 회전하여 embedding 간 내적(각도)으로 상대적 위치를 보존하는 방식으로 임베딩을 수행한다.
Position Interpolation
- LLM이 처음부터 학습할 필요 없이 long context windows을 처리
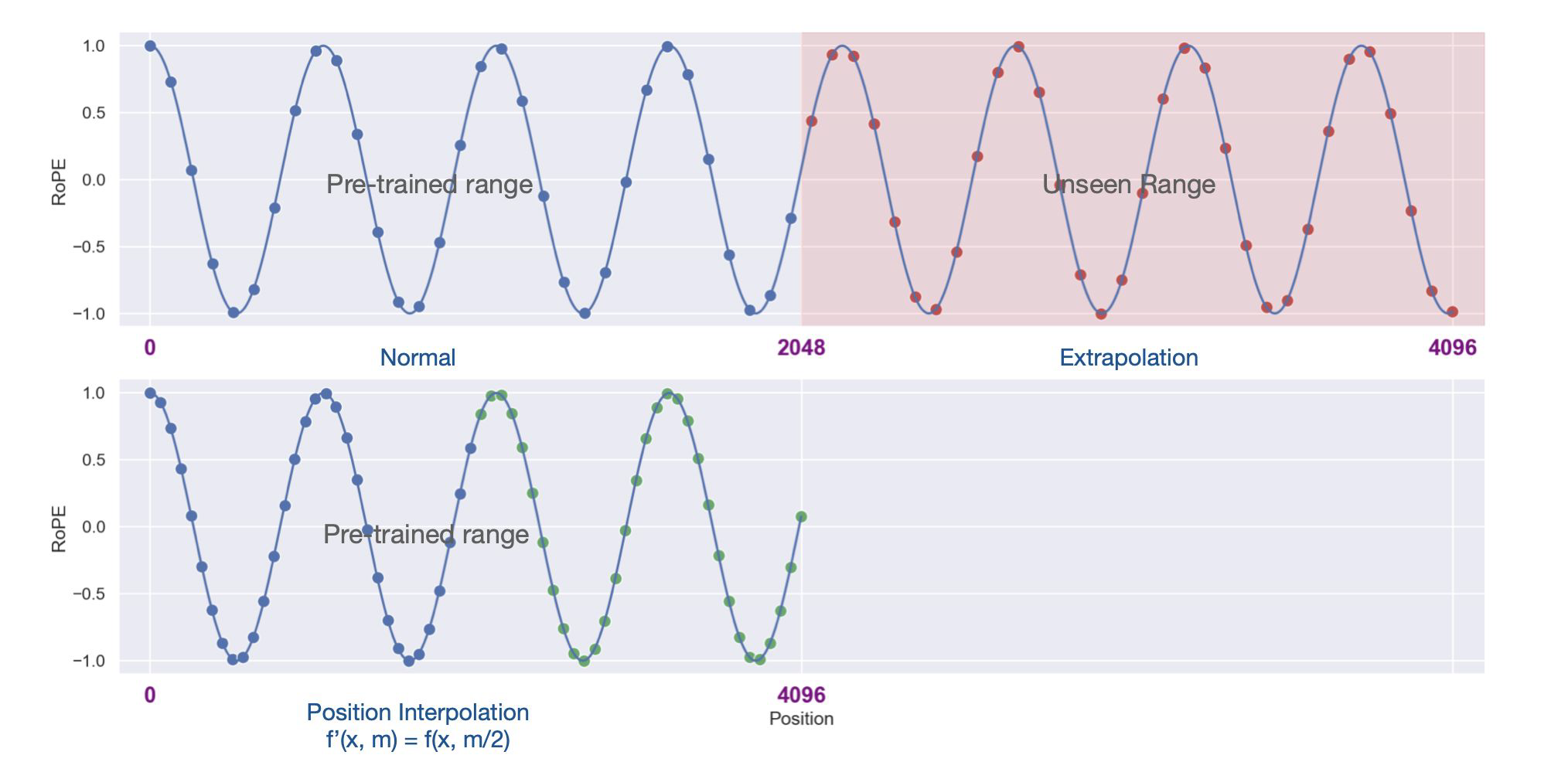
- 위의 그림과 같이 기존 pre-trained 범위(~2048)에서 unseen range 범위(~4096)로 늘려주어 RoPE 위치 정보를 down-scaling 해주는 것이다.
- fine-tuning이 필요한데, LLaMA를 1000 step fine-tuning함으로써, context window size를 기존 2048에서 32768까지 확장해준 사례가 있다.
ALiBi (Attention with Linear Biases)
- 대표적으로 모델의 아키텍처, position embedding 자체를 엄청나게 긴 방식 즉, Linear 방식으로 늘어나게 하는 것을 의미한다.
- 길이가 늘어나도 O(N), N만큼만 늘어나도록 추구한다.
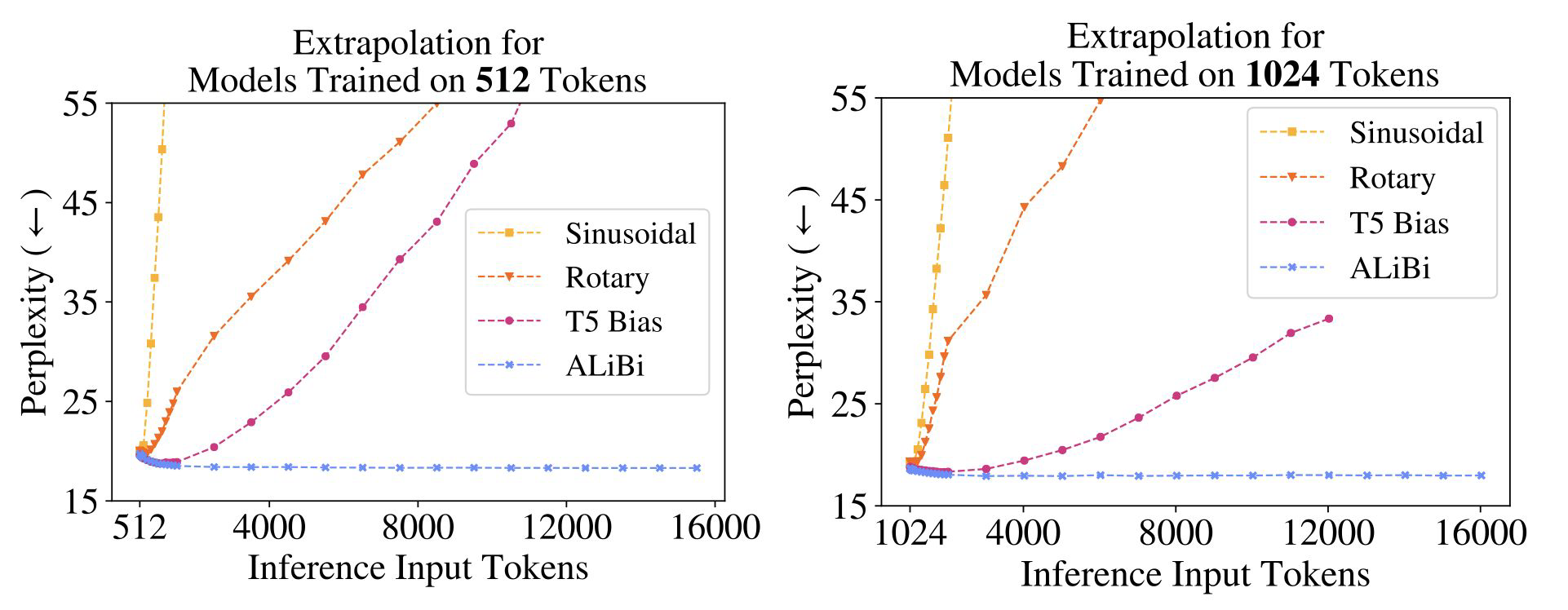
- 위의 그림을 보면 ALiBi를 처리하였을 때, input token 길이가 길어지더라도 perplexity가 유지되는 것을 확인할 수 있다. (성능이 저하되지 않음)
- ALiBi는 extraplolation을 지원하기 때문에, 2048까지만 학습을 해도 바로 4096까지는 적용해도 괜찮다.
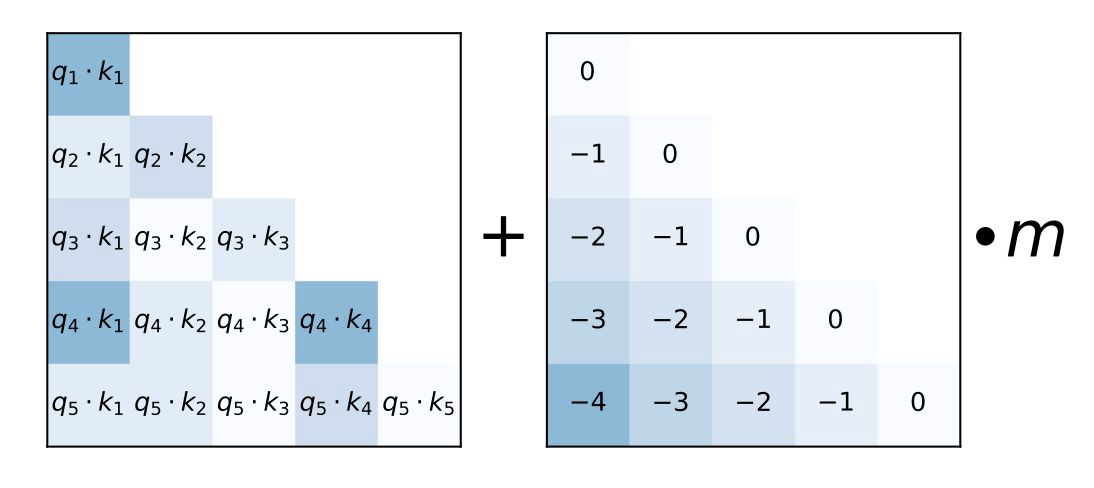
- attention score를 distance에 대해서 따로 penalize를 해주고, positional encoding을 더해주는 방식으로 동작한다.
- 실제로 MPT, BLOOM, Replit 등 다양한 모델에서 ALiBi를 사용하여 context window를 늘렸다.
- 그러나 LLaMA3, Gemma 등 대부분의 모델이 RoPE를 선택하고 있는 추세이다.
Ring Attention
-
context의 길이가 늘어나면 Q, K, V에 생기는 메모리 연산량이 많이 늘어나는데, 이러한 부분에서의 한계를 줄이기 위해서 도입된 개념
-
long context input의 엄청난 메모리 사용량을 쪼개는 것이 컨셉
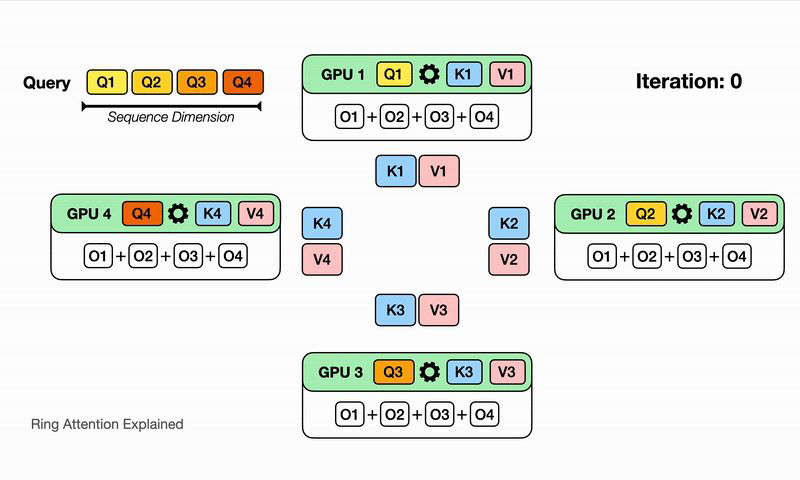
-
Transformer를 block으로 쪼개고, key-value를 block에서 block으로 넘기는 방식
-
쪼개서 계산하기 때문에, GPU 입장에서는 N개의 연산량만 계산하면 됨
-
각 device(GPU)가 query block을 보유하고, key-value block이 device를 돌아다니면서 attention을 계산하여 넘기는 방식으로 동작하기 때문에, sequence의 길이가 아무리 길어져도 GPU 개수만 충분하다면 충분히 해소가능하다.
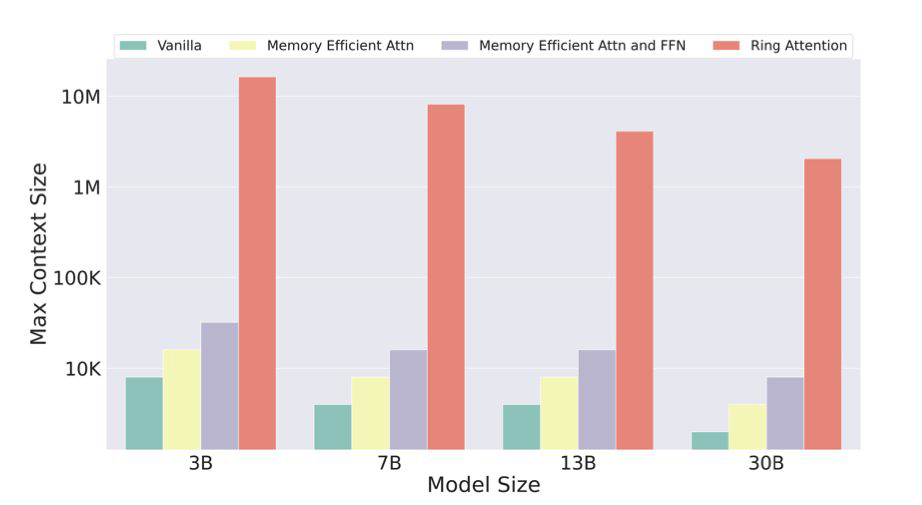
- Ring Attention을 사용하면, device의 개수만큼 더 긴 context를 학습하고 추론하는 것이 가능하다.
- 위의 그래프에서도 확인할 수 있듯이, Ring attention 기법을 적용하면 context size를 엄청나게 늘릴 수 있다.
- N바퀴 연산은 좀 오래 걸릴 수 있다.
