본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
Text Generation
LLM Text Generation
- LLM은 다음 토큰을 예측하도록 학습되는데, 기본적으로 CLM 방식으로 학습되기 때문에 Next token prediction 방식과 동일하게 inference를 수행한다.
- Decoding은 압축된 벡터에서 다음 토큰 하나를 선택하여 출력할 수 있는 일련의 과정을 의미한다. 즉, 텍스트를 생성하는 과정이다.
Decoding 방식에 따른 차이 (Sampling)
- 전체 토큰 중 확률이 가장 높은 토큰을 선택 (Greedy Decoding) : 가장 쉬운 토큰을 선택하는 경향이 있고, 문맥이 길어질수록 앞에 나왔던 단어에 대해서 attention으로 인해 단어의 확률이 올라가는 경향이 있어서 계속 반복되는 ability
- 여러 개의 상위 후보 중 선택 (Top-k Sampling)
Autoregressive Generation
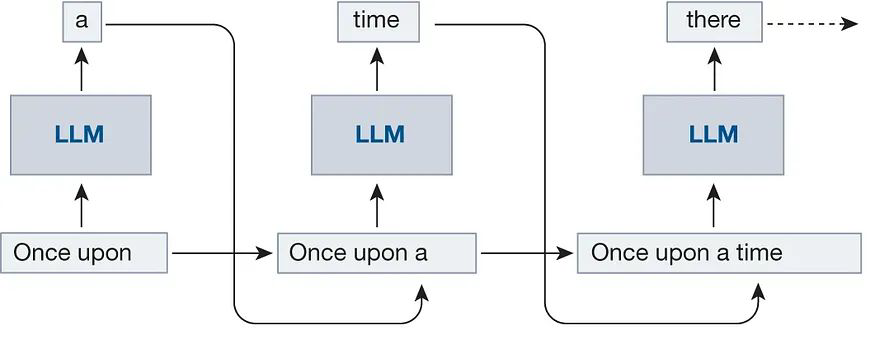
- 한 번에 한 토큰만 생성할 수 있는 방식
- for loop을 N번 생성하면서 주어진 시점 t까지의 입력으로부터 t+1에 등장할 토큰을 계산한다.
- 해당 토큰을 입력에 더한 뒤 생성길이까지 해당 과정을 반복하는 과정이다.
Genreation with HuggingFace
- 가장 Naive한 텍스트 생성 방식은 model foward를 통한 텍스트 생성 방식이다.
- Model forward를 해줄 때, transformers에서 모델 여러 개를 불러오고, 각각의 모델들을 로드해준 다음, 프롬프트를 넣어주고, 그 다음에 나올 토큰을 예측해주는 방식으로 동작한다.
- model foward를 만들어주면 그 다음 토큰들에 대한 logits이 나오게 된다.
- 해당 logits에 softmax를 취해주면 각 토큰들에 대한 확률이 나오고, sampling 방식으로 토큰을 고른다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('gpt2')
model.eval()
tokenizer = AutoTokenizer.from_pretrained('gpt2')
prompt = "Once upon a time"
with torch.no_grad():
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(inputs.input_ids, max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))HuggingFace Pipeline
- 위에서 사용한 snippet을 사용하는 대신 모델을 더욱 쉽게 추론하기 위해 만들어진 추상화 모듈이다.
- Audio, Computer Vision, NLP, Multimodal에서 수행가능한 다양한 task-specific pipeline을 제공해준다.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B-Instruct")
pipeline = pipeline("text-generation", model=model, tokenizer=tokenizer)
response = pipeline("What is the capital of south korea?")
print(response)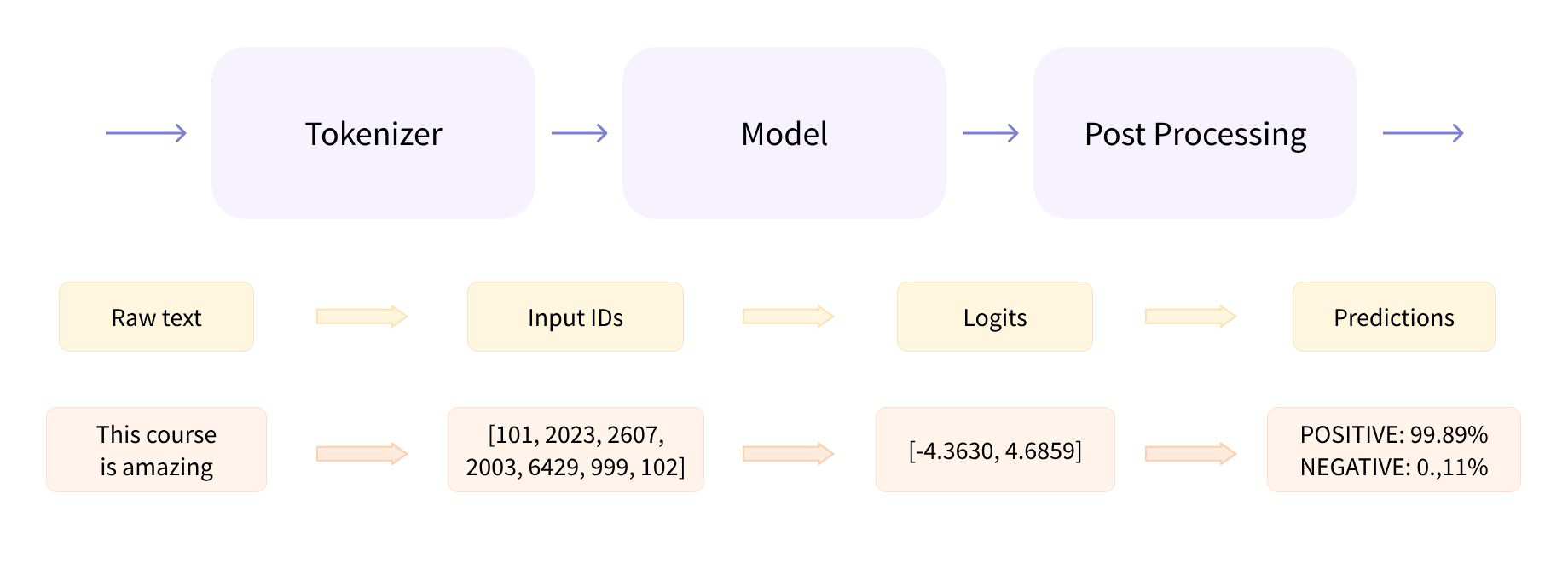
- 전처리, 입력을 모델에 전달하고, 후처리를 함께 수행해준다.
- 즉, text-generation pipeline은 내부적으로 model.generate를 실행하고, 이는 model.tokenizer와 foward를 실행한 후, 여기서 softmax를 취해준 다음 sampling을 취해주고, decoding을 해주는 과정으로 동작하게 된다.
Naive Decoding Limitation
- 이 방식은 한 번에 한 문장을 만들기 때문에, 추론 속도가 매우 느리다.
- 특히 더 긴 텍스트나 많은 데이터에 대해 추론을 진행해야 할 때 매우 느리다.
- Next token 생성을 위해 매번 LLM을 호출해야 하며, 많은 메모리를 차지한다는 단점이 있다.
- 또한 Attention 메커니즘을 사용하고 있기 때문에 시퀀스가 길어질수록 계산량이 급격히 증가하며, Transformer 구현체에서 KV Cache 관리가 잘 되고 있지 않다.
- 이러한 단점으로 인해 추론 최적화를 수행해주고 있다. (다음 포스팅에서 다룰 예정)

✨🐰🫧