본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
Flash Attention
Version 1
- Attention 계산 시 HBM으로의 access 과정에서 생기는 비효율을 해결하기 위해 등장하였다.
- 구체적으로 IO communication (HBM과 SRAM 사이)에서 bottleneck이 발생하는 문제가 있었다.
- 따라서 기존 Attention 계산과 동일하게 가져가면서 메모리를 덜 사용하고, 속도도 빠르도록 개선된 방식이다.
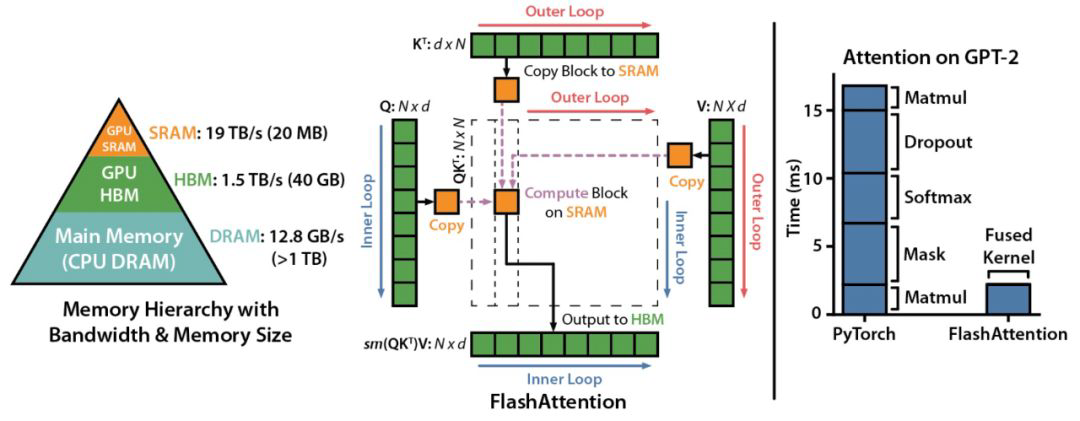
- Query를 고정해둔 상태에서, Key와 Value를 바꿔가면서 연산을 하고, 조각조각으로 연산한 것들을 합하면 기존 값과 동일하게 나온다.
- multi-head를 사용하여, head별로 연산을 수행했기 때문에, single head에 대해서는 병렬처리를 해주지 않았다.
Version 2
- Non-matmul operation 최적화 진행
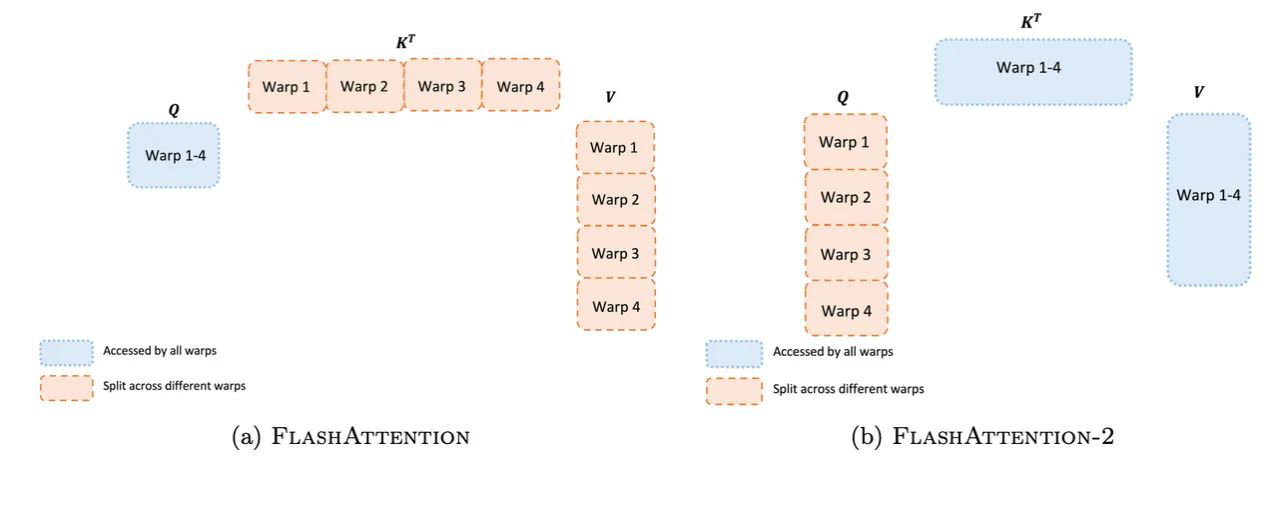
- Single head attention에서도 병렬처리를 수행하도록 변경하여, Query를 여러 개로 쪼갰다.
- 이를 통해 Flash Attention v1 대비하여 2배 빠른 속도를 달성할 수 있었다.
KV Caching, Paged Attention
-
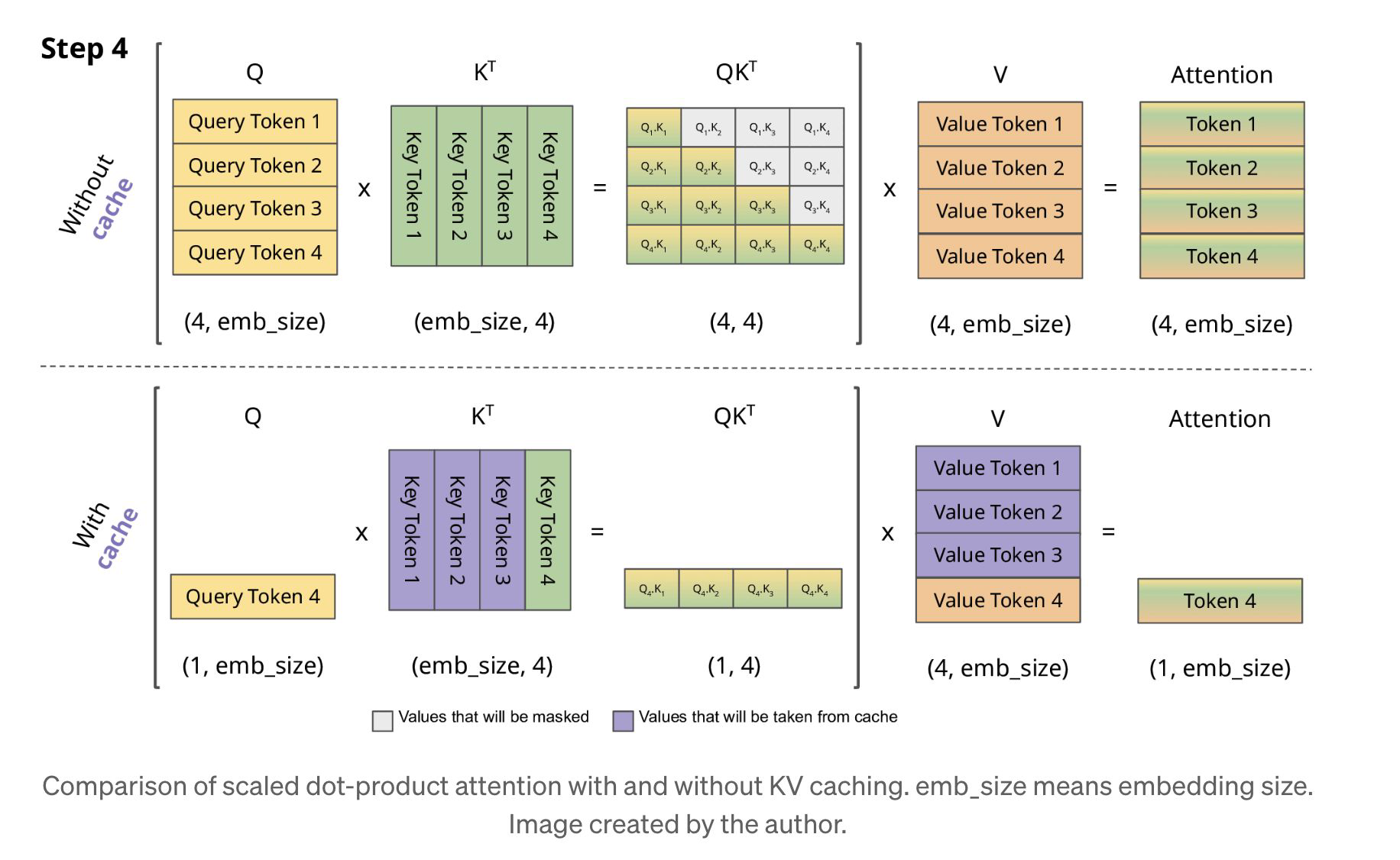
KV Caching : Attention을 계산할 때, Key, Value를 움직이지 않고 캐싱하여 반복 계산을 줄이는 방법이다.
-
즉, Query는 달라져서 매번 계산을 해주어야 하지만, K와 V는 매번 고정된 값으로 있기 때문에, GPU에 계속 올려놔도 괜찮다.
-
그러나 계산량은 줄어들지만, 메모리 양은 많이 사용하게 된다는 단점이 있다.
-
이 때, LLM 추론시 KV Cache 메모리가 너무 커지거나 동적으로 크기가 변하면서 병목현상이 발생하고, OOM이 발생하여 GPU가 터져버리는 현상이 나타날 수 있다.
-
이를 방지하기 위해 나온 개념이 Paged Attention이다.
-
Paged Attention
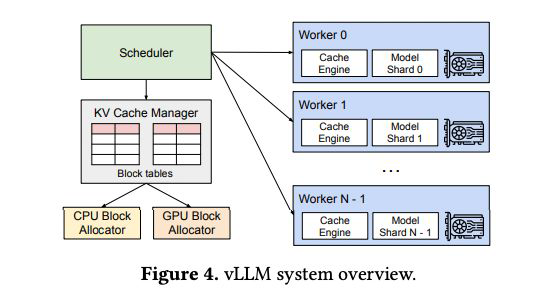
- KV Cache를 여러 physical KV Block으로 분산시켜주어, 필요한 cache는 그대로 두고, 필요없는 cache는 밀어두는 paging 방식으로 계산한다.
- 이로써 동적으로 메모리를 할당하고, 블록 단위로 메모리를 공유할 수 있도록 세팅해준 것
- 이를 통해 효율적인 KV Cache 관리와 메모리를 관리할 수 있어, 병목 현상을 개선할 수 있다.
- 이 개념이 적용된 것이 vLLM이다.
Speculative Decoding
- 모델 여러 개를 사용하는 기법으로, 같은 토큰을 가지고 있어야 한다.
- 작은 모델에 대하여 여러 개의 토큰을 병렬로 계산하여 더 빠르게 샘플링한다.
- 최적화 타겟 모델을 Mp, 효율적인 approximation 모델을 Mq라고 한다면 우선 Mq를 통해 다수의 샘플들을 생성한다.
- Mp가 앞서 생성된 샘플들을 병렬로 평가하여 Mp의 분포와 일치하는 샘플들을 선택하고, 일치하지 않는 경우 조정 과정을 수행한다. 즉, 큰 모델 입장에서는 한 번에 N개의 토큰을 보는 것과 같은 효과를 가진다.
- 한 번의 Mp 호출로 N개의 토큰을 생성할 수 있어 속도 측면에서 장점을 가진다.

Continuous Batching
- 학습할 때 특정 batch를 넣어 학습이 빨라지는 것처럼, inference 시에도 batch를 넣어보자는 컨셉
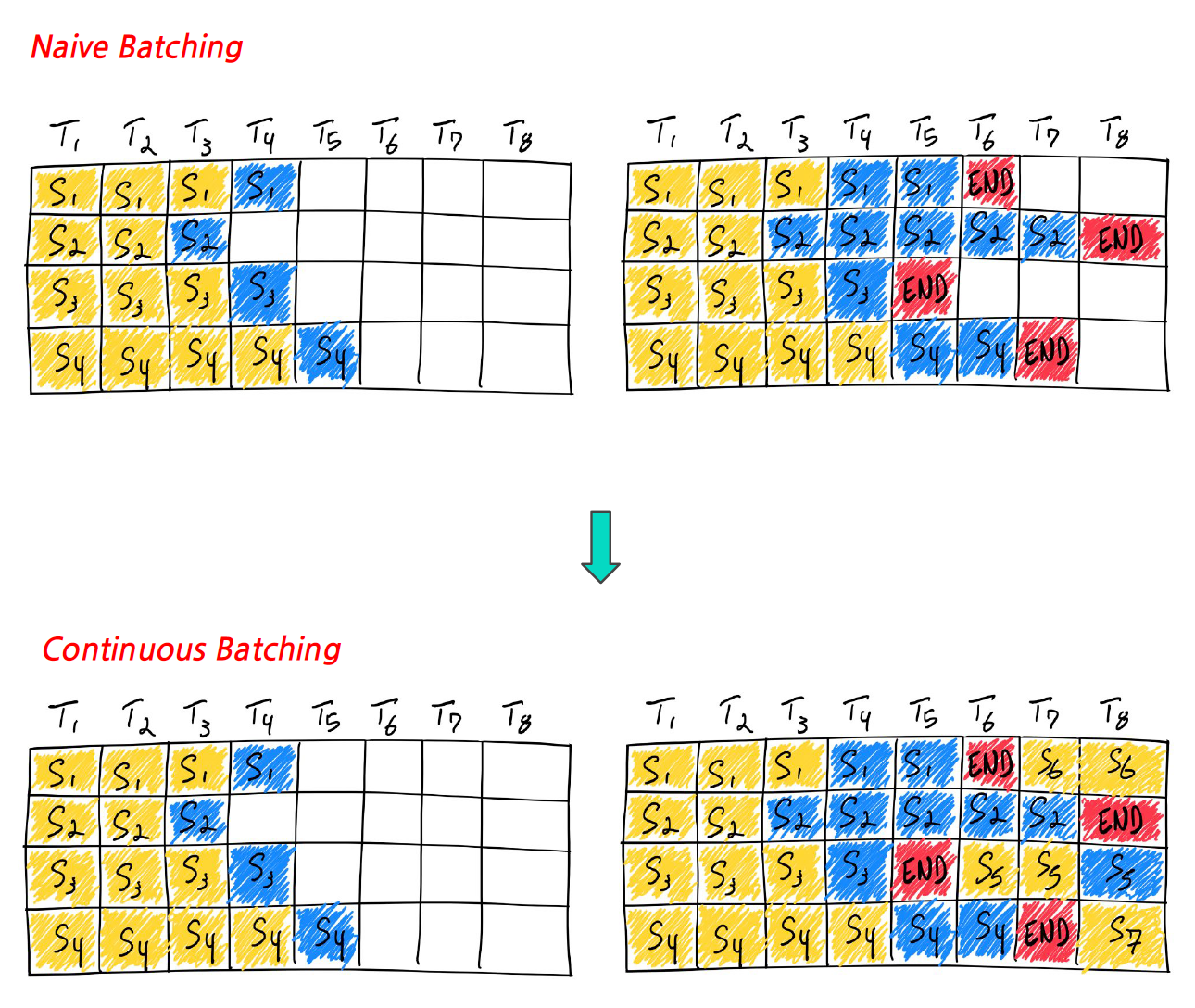
- Naive Batching
- 기존에는 inference가 완료되기 전까지 배치 크기는 고정상태로 대기한다.
- Continous Batching
- Batch가 4라고 했을 때, 배치 안의 모든 시퀀스들이 생성 완료되는 것을 기다리는 대신, Batch size를 동적으로 결정하는 기법이다.
- 배치 안의 한 시퀀스 생성이 완료되면 새로운 시퀀스로 채운다.
- 즉, 4개의 배치 중 하나라도 빨리 끝나면, 그 자리에 바로 다음 것을 넣어주는 것이다.
- 이를 통해 GPU 낭비 없이 100% 사용할 수 있어 효율이 올라간다.
Kernel Fusion
-
Kernel은 CUDA 코드 중에서 GPU 디바이스에서 동작하는 영역으로 주로 연산을 담당한다.
-
Kernel Fusion은 여러 개의 kernel을 하나로 합쳐서 실해ㅇ하는 것을 의미한다.
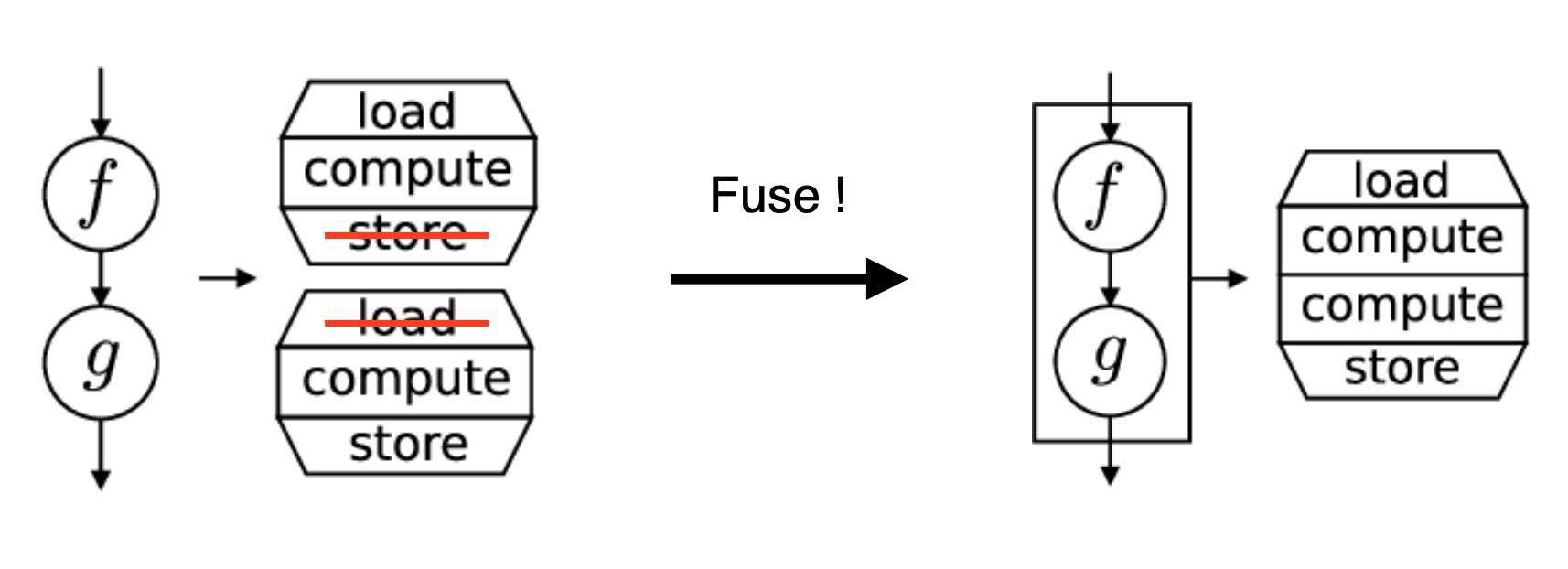
-
예를 들어 matmul 이후, add 연산을 해주는 두 개의 kernel 연산을 수행한다고 할 때, 이 두개의 kernel에 대한 fusion을 통해 MatMulAdd라는 하나의 kernel로 수행 가능하다.
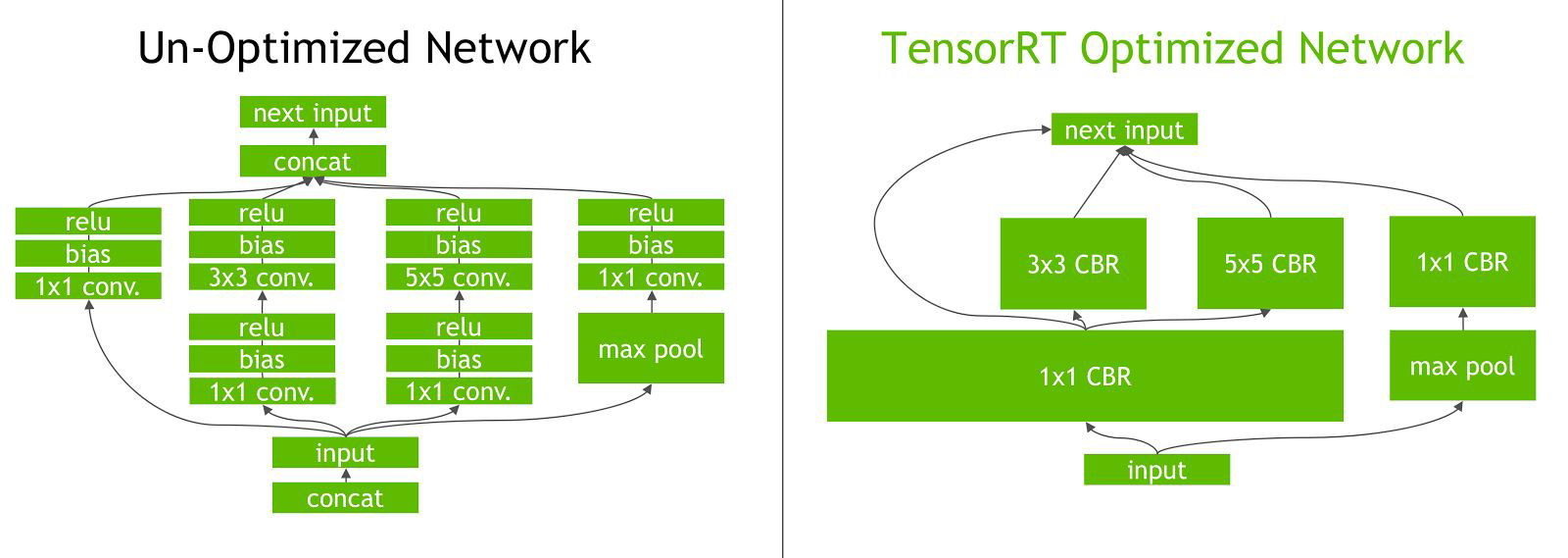
-
기존처럼 실행해줄 경우, GPU가 연산마다 하나하나 실행을 하고 있는데, optimize가 될 여지에 있는지 여부에 대해서 알지 못한다.
-
Kernel fusion을 실행해줄 경우, TensorRT라고 하여 Optimize해주는 framework으로 연산을 고정시켜 최적의 그래프를 만들어준다.
Reference
All You Need To Know About LLM Text Generation
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Efficient Memory Management for Large Language Model Serving with PagedAttention
Transformers KV Caching Explained
Fast Inference from Transformers via Speculative Decoding
How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
https://songys.github.io/2021Langcon/data/Parallelformers_Langcon.pdf
