본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.
vLLM
- LLM을 위한 고성능 추론 프레임워크
- Python 기반 개발
- PagedAttention을 통한 Attention Key, Value 메모리의 효율적인 관리
- FlashAttention을 통합한 최적화된 CUDA kernel도 함께 사용 가능
- Speculative Decoding
- Continuous Batching
- GPU 뿐만 아니라 TPU를 통해서도 서비스되고 있음
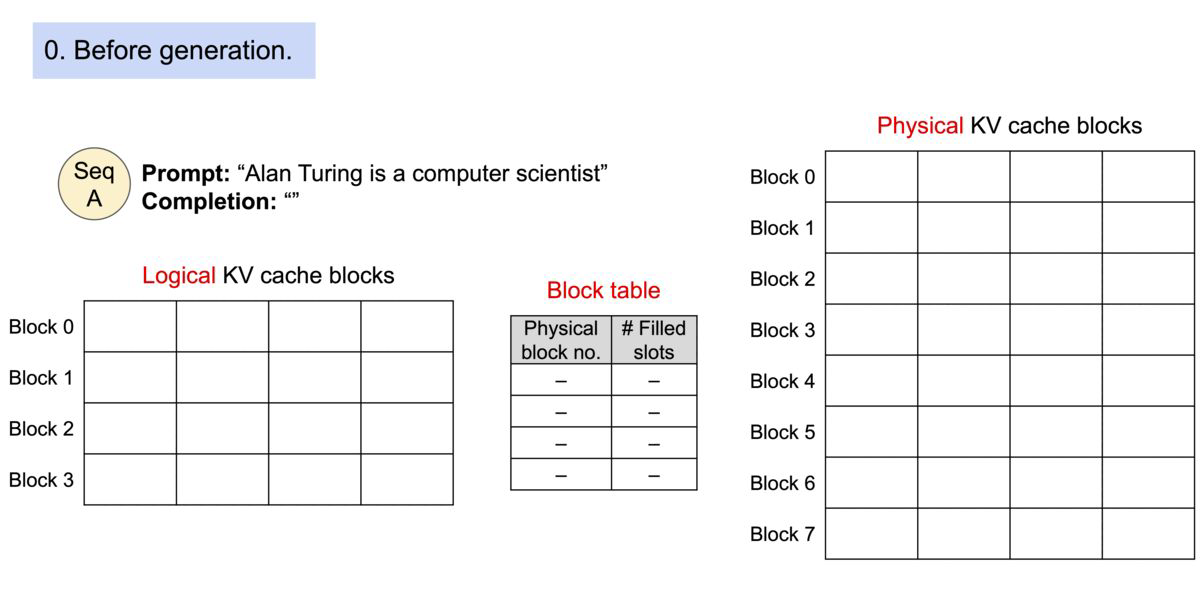
사용 방법
- VLLM 설치
- $ pip install vllm
- 사전 준비
- LLaMA Grant Access (https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct)
- Model serving
- $ sh vllm.sh
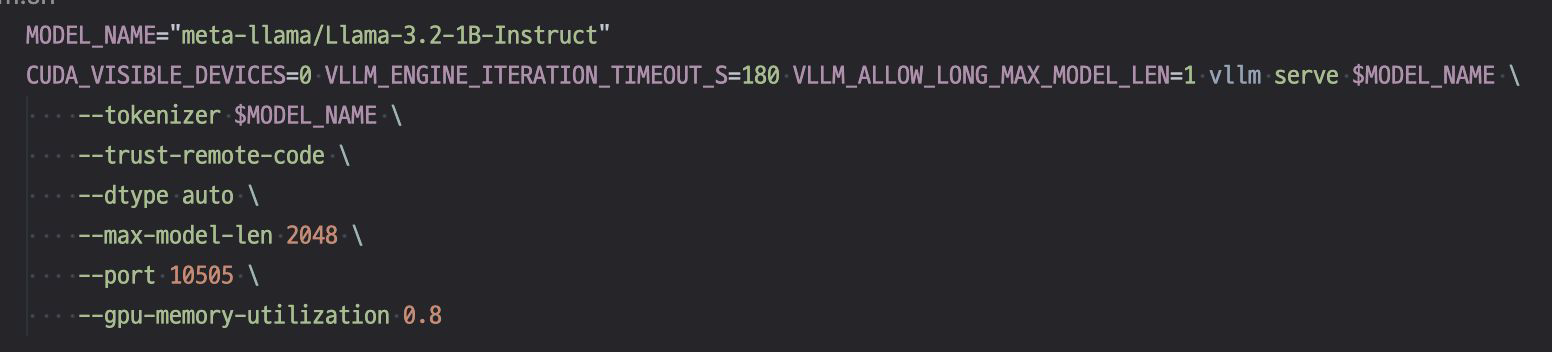
- 서버 실행 모습

- $ sh vllm.sh
- Inference : OpenAI Compatible 형식으로 진행
- $ python inference.py
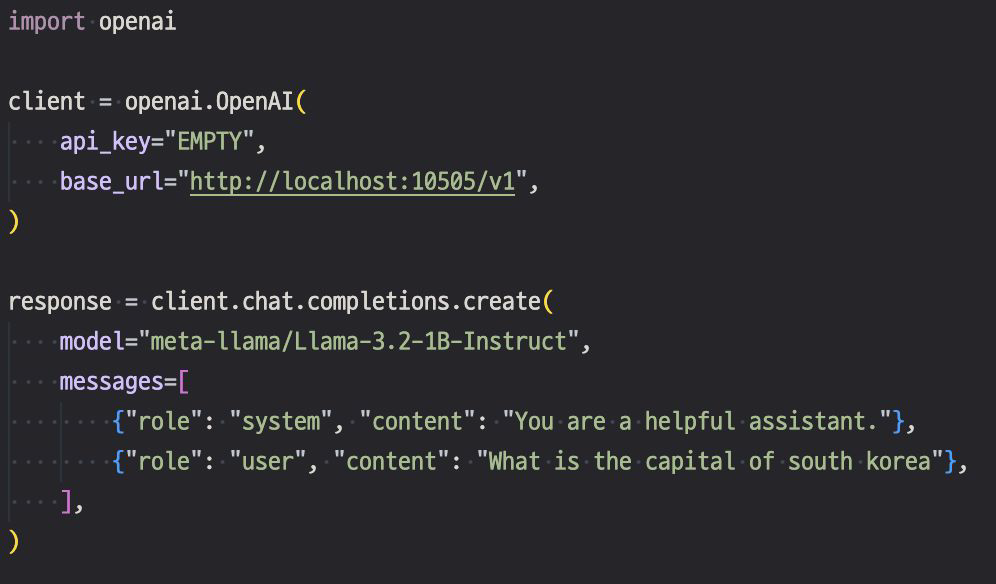
- $ python inference.py
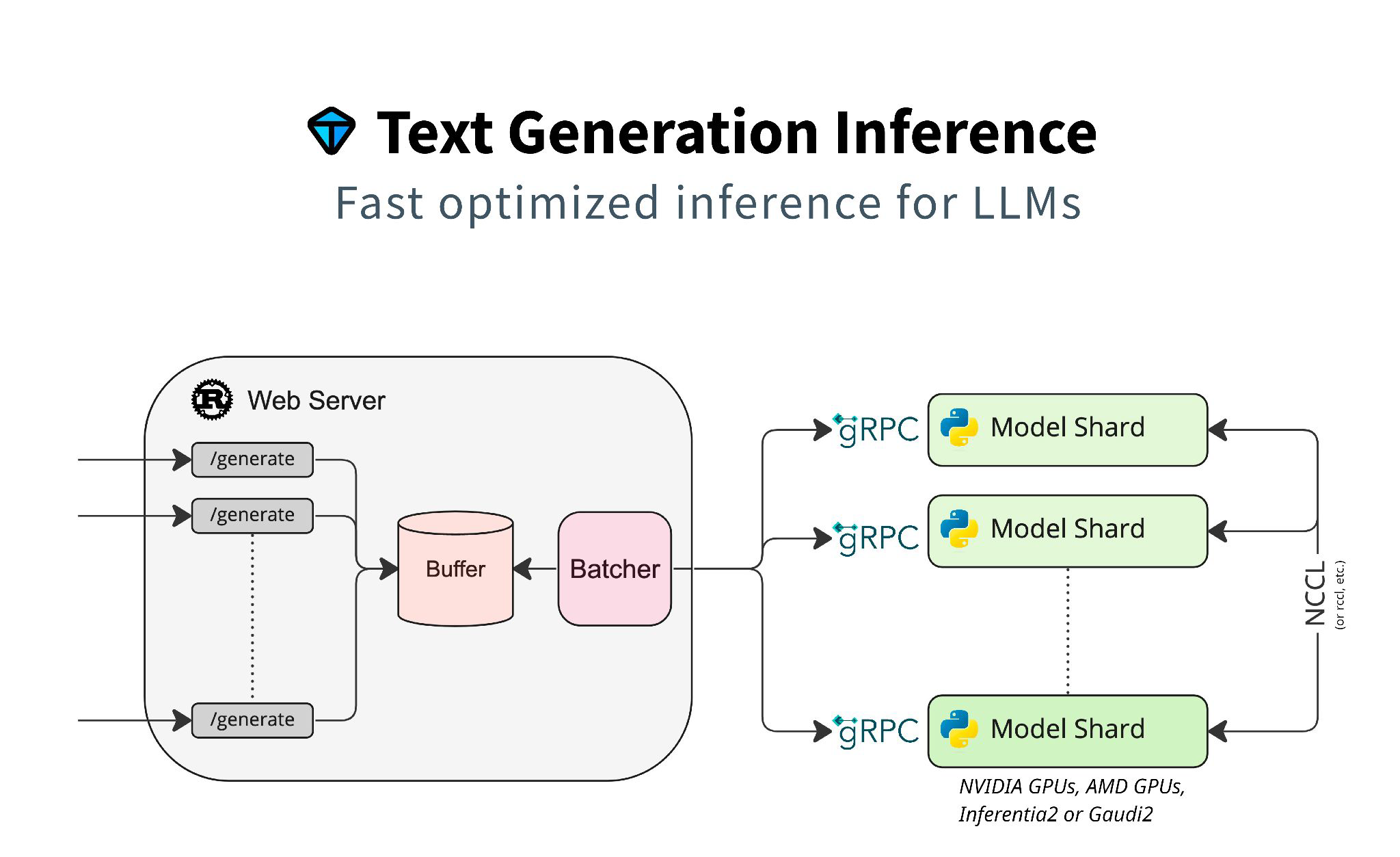
Text Generation Inference (TGI)
- Simple launcher to serve most poplular LLMs
- Rust 기반 개발
- Tensor parallelism을 통한 GPU 분산 처리: head 단위로 여러 개 쪼개는 기법
- Continuous batching
- Flash attention
- Paged attention
사용 방법
- 사전 준비
- Docker install
- LLaMA Grant Access (https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct)
- Model Serving
- $ sh tgi.sh

- 서버 실행

- $ sh tgi.sh
- Inference
- $ python inference.py
- $ python inference.py
SGLang
- LLM과 VLM을 위한 모델 서빙 프레임워크로 속도가 굉장히 빠름
- Backend runtime, Frontend 공동 설계를 통한 더 빠른 interaction
- 병렬처리, mutimodal, structured output, function calling 지원
사용 방법
- 설치
- $ pip install sglang[all]
- $ pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.4/
- CUDA 및 Torch 버전에 맞게 수정
- 사전 준비
- LLaMA Grant Access (https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct)
- Model Serving
- $ sh sglang.sh
- 서버 실행

- $ sh sglang.sh
- Inference
- $ python inference.py
- $ python inference.py
OpenAI Compatible
- 다양한 LLM Provider가 OpenAI API와 유사한 인터페이스를 제공
- OpenAI의 chat completion은 LLM API의 standard로 사용되고 있다.
- 앞서 소개한 추론 시스템들도 OpenAI 형태의 추론을 지원한다.
더 빠른 추론을 위한 팁
Medusa
- Speculate decoding을 할 때 더 빠르게 하는 기법
- LLM Generation Accelerating Framework
- Multiple decoding heads를 parameter-efficient한 방식으로 학습한다.
- 또한 Multiple future tokens를 동시에 생성하게 된다.
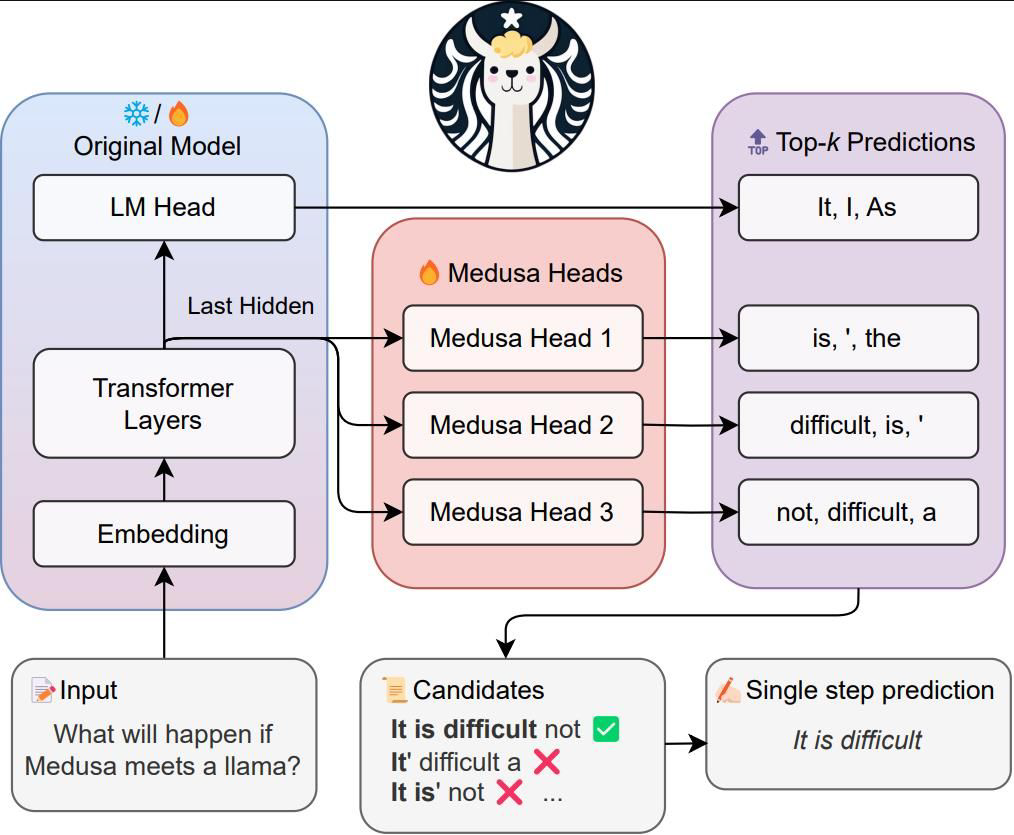
Quantization
- 모델을 좀 더 적은 GPU 상에서 돌릴 수 있도록 하는 기법
- LLM에서의 Quantization은 floatiing point type을 integer 또는 fixed point로 변환하는 과정이다.
- 메모리 확보로 인해 배치 사이즈가 증가하고 추론 속도가 향상되는 패턴이다.
Reference
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
Faster and More Efficient 4-bit quantized LLM Model Inference

✨🐰🫧