1. 데이터 탐색
R 기본 데이터인 ‘Iris’ 데이터를 활용하여 knn(5-fold cross validation)을 사용하기에 앞서 데이터의 기본적인 구조를 탐색한다.
Target Variable은 Species로 설정하고, setosa와 nonsetosa로 나눈다.
2.KNN(5-Fold cross validation)
Train : Validation : test 데이터를 각각 5 : 3 : 2로 나누어 활용하였다.
library(caret)
set.seed(1)
idx <- sample(1:nrow(iris), nrow(iris)*0.7)
train <- iris[idx, ]
test <- iris[-idx, ]
random_ids = order(runif(150))
iris_train = iris[random_ids[1:75],]
iris_valid = iris[random_ids[76:120], ]
iris_test = iris[random_ids[121:150], ]
tune <- caret::trainControl(method = "CV", number = 5)
iris_knn <- caret::train(Species~. ,data = iris_valid,
method = "knn",
trControl = tune,
tuneLength=25)
iris_knn
plot(iris_knn)
pred1 <- predict(iris_knn, newdata = iris_test)
caret::confusionMatrix(pred1, iris_test$Species)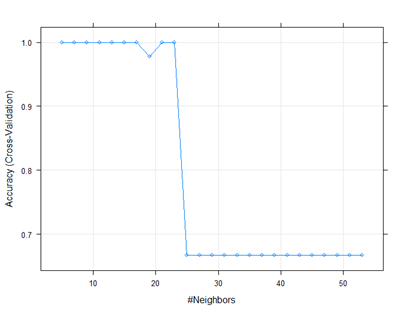
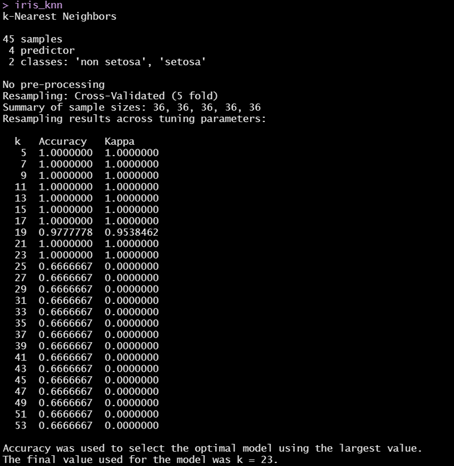
5-fold Cross Validation을 이용하여 validation 45개 데이터를 5번에 걸쳐 분석을 시행,최적의 k를 구하였다. Tune Length를 25로 조절하여 k에 따른 정확도를 확인한 결과 다음과 같은 그래프의 형태를 보이며, 최적의 k는 23으로 도출되었다.
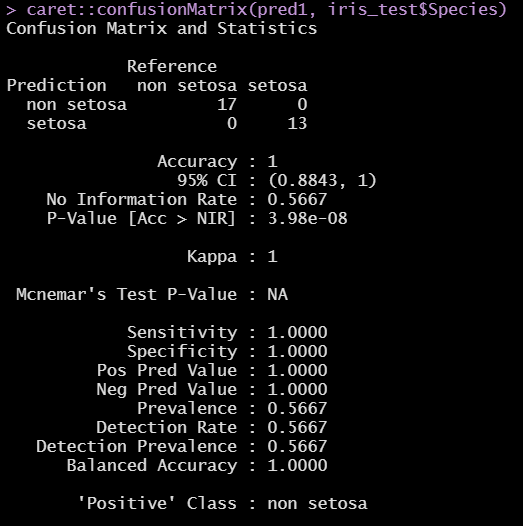
caret::confusionMatrix(pred1, iris_test$Species)를 통해 확인한 error rate는 0으로, Accuracy = 1.0, Kappa = 1로 관측된다.

잡학꾸러기