이전 글
이 전에는 생선의 길이와 무게의 데이터를 k-최근접 이웃 알고리즘(k-Nearest Neighbors)에 학습시켜 해당 생선이 어떤 생선인지 분류하는 작업을 하였다.
이번에는 생선의 피처(feature)를 이용하여 해당 생선의 무게를 예측하는
회귀(Regression)을 알아보겠다.
회귀(Regression)란?
회귀는 여러개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법을 의미합니다.
예를 들면 아파트의 방 개수, 화장실 크기 등의 독립변수에 따라서 아파트 가격인 종속변수가 어떤 관계를 가지는지를 모델링하고 예측하는 것입니다.
회귀(Regression)과 분류(Classfication)
우리가 실습하는 생선에 비유하자면, 해당 생선의 무게와 길이의 데이터를 보고 이 생선이 도미인지, 빙어인지, 농어인지 예측하는 작업이 분류(Classfication)이며,
해당 생선의 길이, 높이, 두께 등의 데이터를 이용하여 무게를 예측하는 작업이
회귀(Regression)이다.
k-최근접 이웃 회귀(KNeighborsRegressor)이란?
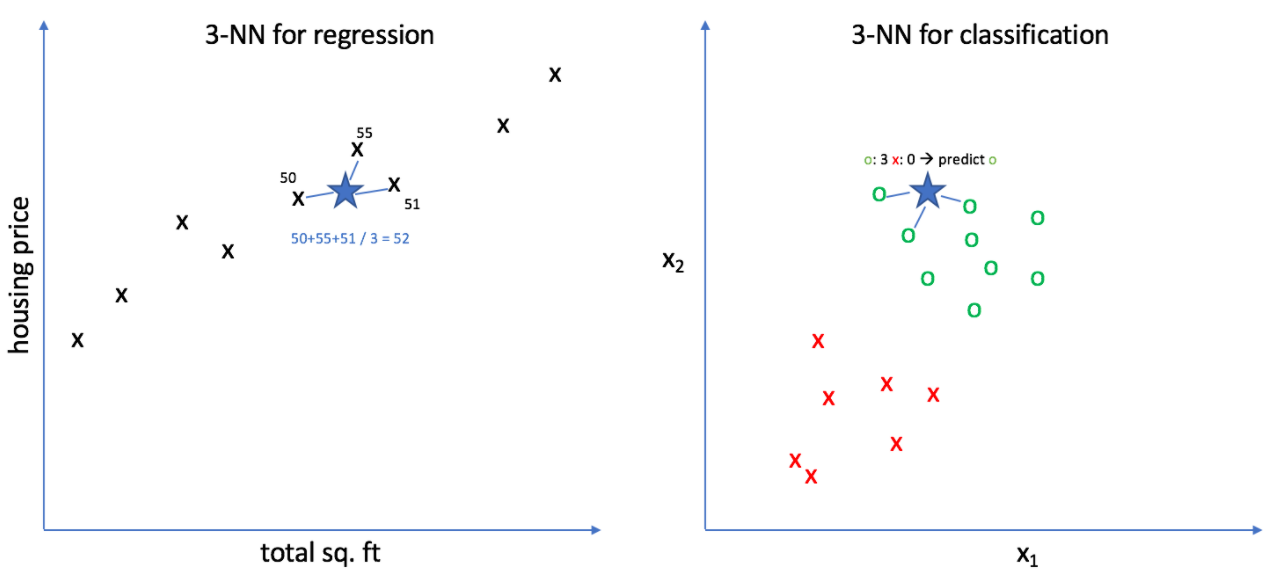
위의 사진처럼 k-최근접 이웃 회귀는 자신이 예측하고 싶은 데이터와 가장 근접한 샘플 k개를 선택하여 평균을 계산한 뒤, 그 평균값을 예측값으로 정한다.
k-최근접 이웃 분류과 알고리즘이 굉장히 비슷하지만 예측값을 결정할 때만 조금 다르다.
이제 농어의 길이와 무게의 데이터를 이용하여 k-최근접 이웃 회귀 모델을 학습시킨 후
농어의 길이를 입력하면 농어의 무게를 예측하는 작업을 해보자.
데이터 준비
import numpy as np
#농어의 데이터 개수는 총 56개
#농어의 길이
perch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
#농어의 무게
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)총 56마리의 농어에 대한 길이와 무게에 대한 데이터가 준비돼있다. 이 데이터를
산점도(Scatter)을 이용하여 직관적으로 확인하자.
import matplotlib.pyplot as plt
plt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()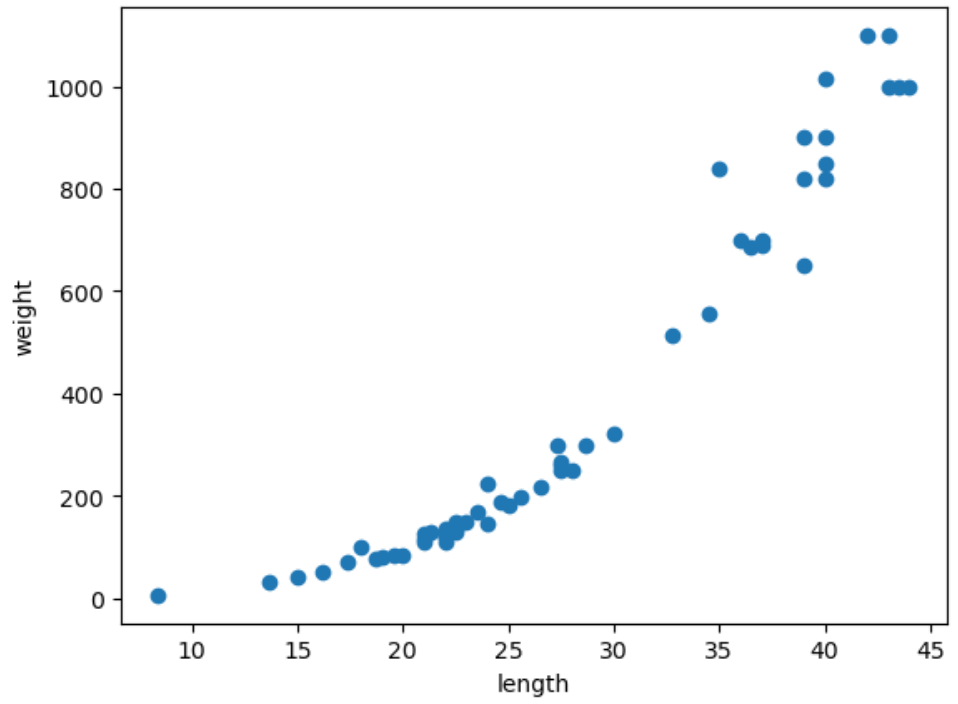
산점도를 확인해보면 농어의 길이가 커짐에 따라 무게도 같이 증가한다.
k-최근접 이웃 회귀 모델 학습시킨 후 평가하기
이제 머신러닝 모델에 사용하기 전, 사이킷런의 train_test_split을 이용하여 학습용 데이터셋과 테스트용 데이터셋으로 나누겠다.
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(perch_length, perch_weight, random_state=42)
#random_state=42는 교재와 같은 데이터셋으로 나누기 위하여 설정.이 전에 사이킷런의 모델을 사용하기 위해서는 train_X와 test_X가 2차원 배열이여야 된다고 하였다. numpy의 reshape를 이용하여 1차원 배열을 2차원 배열로 설정하겠다.
train_X = train_X.reshape(-1, 1)
test_X = test_X.reshape(-1, 1)2차원 배열이라 했는데 왜 (-1, 1)으로 reshape하는지 이해가 안된다면
링크를 참고하자.
이제 사이킷런의 KNeighborsRegressor를 이용하여 회귀 모델을 학습시키자.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_X, train_y) #회귀 모델 학습
print(knr.score(test_X, test_y))
#출력값: 0.992k-최근접 이웃 회귀 모델을 학습용 데이터셋으로 학습 후, 테스트용 데이터셋으로 score을 확인하였다. 여기에서의 score은 뭘까?
분류 모델에서의 점수는 테스트 데이터셋에 있는 샘플을 정확하게 분류한 개수의 비율이다.
하지만 회귀 모델에서의 점수는 농어의 무게 등 정확한 숫자를 예착하여 맞춘다는 것이 거의 불가능하다. 그래서 회귀 모델의 경우 점수를 분류 모델과는 다르게 평가하는데 이 점수를 결정계수(coefficient of determination)이라 한다.
결정계수란?
결정계수는 흔히 R^2(R-Squared)라 하며 회귀모델에서 독립변수(X)가 종속변수(y)를 얼마나 설졍하냐를 가르키는 지표이다.결정계수를 구하는 공식은 다음과 같다.
- 결정계수는 높을 수록 좋은 것이다

위에서 의 값이 0.992가 나왔다. 하지만 분류 모델에서의 정확도처럼 가 직감적으로 얼마나 좋은지 이해하기 어려움이 있다.
사이킷런의 mean_absolute_error 모듈을 사용하여 타깃과 예측한 값 사이의 차이를 구해보면 어느정도 예측이 벗어났는지 가늠하기 좋다.
from sklearn.metrics import mean_absolute_error
test_prediction = knr.predict(test_X)
mae = mean_absolute_error(test_prediction, test_y)
print(mae)
#출력결과: 19.1예측이 타깃과 평균적으로 19g 정도 차이가 난다는 것을 알 수 있다.
모델 평가와 과적합
지금까지 학습용 데이터셋을 사용하여 모델을 학습시킨 후 테스트 데이터셋으로 모델을 평가하였다. 하지만 모델을 평가할 때 테스트 데이터셋이 아닌 학습용 데이터셋을 이용하면 어떨까?
print(knr.score(test_X, test_y)) #테스트용 데이터로 평가하기
#출력값: 0.992
print(knr.score(train_X, train_y)) #학습용 데이터로 평가하기
#출력값: 0.969회귀모델을 학습용 데이터셋에 학습시키면 학습용 데이터셋과 잘 맞는 모델이 만들어진다. 이러한 이유 때문에 보통 해당 모델을 학습용 데이터셋과 테스트용 데이터셋으로 평가를 한다면 당연하게 두 값 중 학습용 데이터셋으로 평가한 점수가 더 높아야 한다.
만약 학습용 데이터셋에서 점수가 좋았지만, 테스트 데이터셋에서 점수가 나쁘게 나온다면 해당 모델은 학습용 데이터셋에 과대적합(Overfitting)되었다고 말한다. 즉, 모델이 학습용 데이터셋을 너무나도 잘 학습시킨 나머지, 테스트용 데이터셋이나, 새로운 데이터셋에 대한 예측이 잘 작동하지 않는 것을 말한다.
반대로 학습용 데이터셋보다 테스트용 데이터셋의 점수가 더 높거나, 두 점수가 너무 낮은 경우는 해당 모델이 학습용 데이터셋에 과소적합(underfitting)되었다고 말한다.
즉, 모델이 너무 단순하여 학습용 데이터셋에 학습이 적절히 되지 않은 경우를 말한다.
앞에서의 학습용 데이터셋과 테스트용 데이터셋의 점수를 비교해보자. 학습용 데이터셋보다 테스트용 데이터셋의 점수가 더 높다. 즉 과소적합(Underfitting)이다.
이런 과소적합 문제를 어떻게 해결할까? 답은 모델을 조금 더 복잡하게 만들면 된다.
즉 해당 모델을 학습용 데이터셋에 더욱 더 알맞게 만든다면 테스트 데이터셋의 점수는 조금 낮아질 것이다.
k-최근접 이웃 알고리즘의 모델을 더 복잡하게 만드는 방법은 이웃의 개수인 k의 개수를 줄이는 것이다.
k의 개수를 5개에서 3개로 줄인 후, 모델을 다시 학습시키자.
knr.n_neighbors = 3
knr.fit(train_X, train_y)
print(knr.score(test_X, test_y))
#출력값: 0.9746459963987609
print(knr.score(train_X, train_y))
#출력값: 0.9804899950518966k의 값을 5에서 3으로 줄이니 학습용 데이터셋의 결정계수는 높아지고, 테스트용 데이터셋의 결정계수는 낮아졌다.
테스트 데이터셋의 점수가 학습용 데이터셋의 점수보다 낮아졌으므로 과소적합(Underfitting)의 문제는 해결하였다. 또한 두 점수 차이가 크지 않으므로 해당 모델은 과대적합의 경우도 아니다. 즉 모델 학습을 성공적으로 마무리하였다.
