[Stanford CS229] Lecture3 - Locally Weighted & Logistic Regression
Stanford CS229 Lecture Note
.png)
1. Locally Weighted Linear Regression
기존의 Original Linear regression algorithm과 Locally weighted linear regression algorithm은 다음과 같은 차이가 있다.
Here the w(i) are non-negative valued weights.
If w(i) is small, then the error term will be pretty much ignored in the fit.
And fairly standard choice for the weights is below.
If |x(i) - x| is small, then w(i) is close to 1;
and if |x(i) - x| is large, then w(i) is small.
tau is called bandwith parameter, and controls how quickly the weight of a training example falls off with distance of its x(i) from the query point.
Locally weighted linear regression is the first example we're seeing of a non-parametric algorithm. The term "non-parametric" refers to the fact that the amount of stuff we need to keep in order to represent the hypothesis h grows linearly with the size of the training set.
Linear regression은 1) non-linear data 분석이 어려움 2) data가 많을 경우 underfit한 경향을 보임 3) 독립 변수가 많을 경우 결과가 좋지 않음 의 문제가 존재한다.
Locally weighted regression은 unbiased estimator인 w를 bias에 넣어줘서 mean-squared error을 줄일 수 있다는 점에서 underfitting/overfitting을 예방할 수 있다.
2. Logistic Regression
This is called the logistic function or the sigmoid function.
Plotted result of g(z) is like below.
g(z) is always bounded between 0 and 1. And Heare's a useful property of the derivative of the sigmoid function. Which is written as g'.
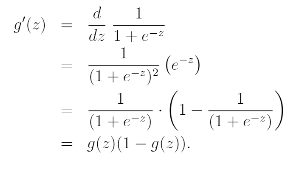
위와 같은 성질을 이용하여 log likelihood를 구해보면 다음과 같이 구할 수 있다.
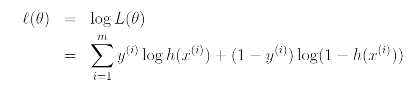
위의 결과에 stochastic gradient ascent rule을 적용해보면 다음과 같다.
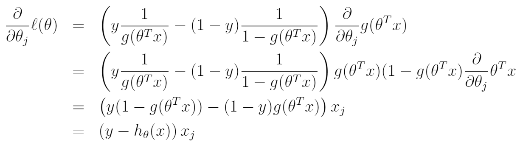
위의 결과에서 g'(z) = g(z)(1-g(z))의 성질을 이용하여 stochastic gradient ascent rule을 나타내면 이와 같다.
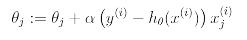
이 형태는 LMS update rule과 동일해보이지만 절대 같은 알고리즘이 아니다. 그 이유는 h(x)가 x(i)의 non-linear 함수의 형태로 정의되었기 때문이다. 그러나 두가지 알고리즘이 같은 update rule을 가지게 되었다는 것은 단순한 우연은 아니며 추후 수업 진행에 따라 GLM models에서 이에 대해 설명할 예정이다.
정리
Logistic Regression에 따른 classification은 decision boundary라는 경계를 바탕으로 구역을 나누게 된다. 이를 통해 나온 weighted sum이 0보다 큰 것을 y=1로, 그 반대의 경우는 y=0으로 정할 수 있다.
3. Another Algorithm for maximizing l(theta)
Newton's Method의 일반식은 다음과 같다.
이를 l 함수에 적용시켜 보면 다음과 같은 update rule을 얻을 수 있다.
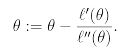
이 mutltidimensional 세팅에 generalization of Newton's method를 적용하면( Newton-Rapson Method라고 알려져 있음) 다음과 같이 H(Hessian)을 사용한 형태로 나타낼 수 있다.
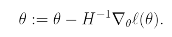
Netwon's method는 batch gradient descent에 비해 빠른 convergence를 얻을 수 있으며, 더 적은 iteration으로 minimum에 도달할 수 있다는 장점이 있으나, n-by-n 행렬에 대한 finding과 inverting이 필요하다는 점에서 iteration이 더 expensive하다는 단점도 존재한다.
강의 링크 : Stanford CS229 Youtube
To be continued...
