
Interpretable Machine Learning:
A Guide for Making Black Box Models Explainable (2nd ed.)을 읽고 정리한 내용입니다.
머신러닝이란 무엇인가요?
기계학습(Machine Learning)이란 '컴퓨터가 데이터를 기반으로 예측이나 행동을 만들고 이를 더 나은 방법으로 개선하는 데 사용하는 일련의 방법론'입니다. 즉 컴퓨터가 원하는 목표대로 짜여진 코드대로 동작하는 것이 아니라 주어진 데이터를 직접 분석하고, 이를 통해 최적의 결과를 도출해내는 모든 과정을 말하는 것입니다.
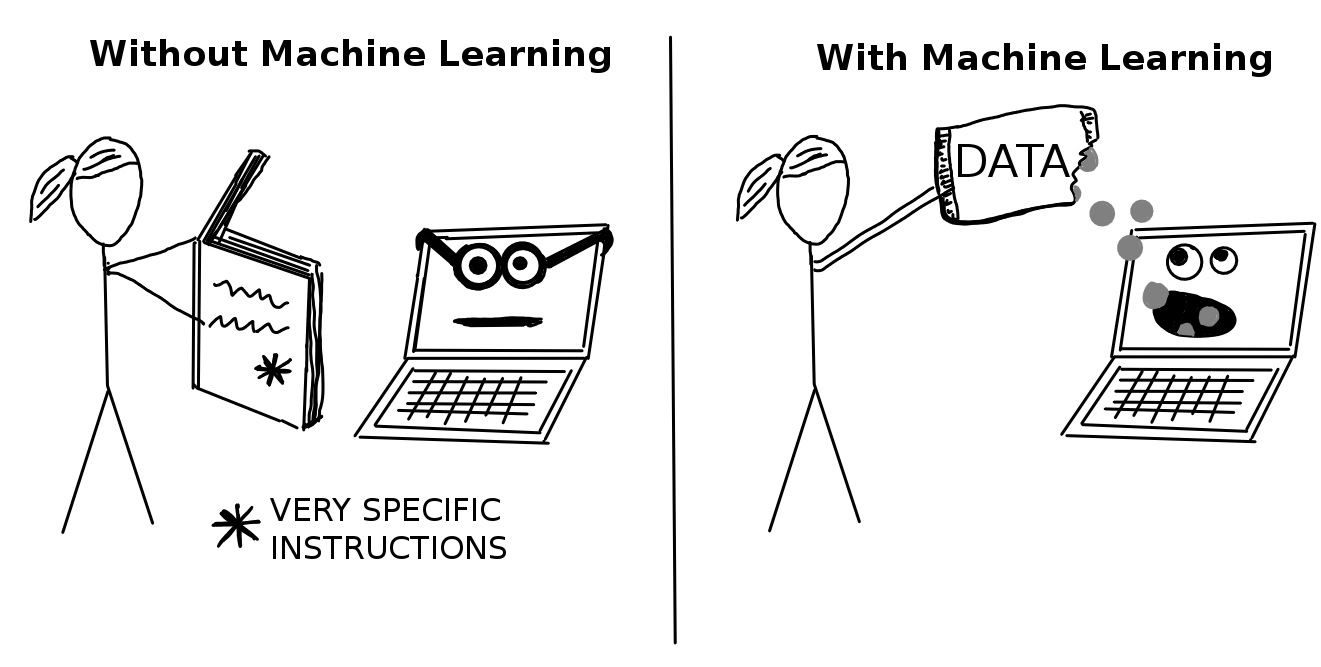
위 그림을 통해 기계학습과 일반학습의 차이를 쉽게 알 수 있습니다.
왼쪽의 경우 기계학습을 사용하지 않는 경우이며, 사용자가 if-else문 등을 사용하여 각각의 경우에 대해 프로그램이 동작할 수 있도록 상세하게 알고리즘을 설계하면 컴퓨터는 구체적인 설명서대로 프로그램을 실행합니다.
반면 오른쪽의 경우 기계학습을 하는 경우이며, 사용자는 컴퓨터에게 대량 데이터를 제공하면 충분하고, 컴퓨터는 주어진 데이터를 수집하여 스스로 학습을 하게 됩니다.
주택 가격을 예상하거나, 상품을 추천하거나, 물체를 탐지하거나, 신용카드 거래 사기를 탐지하는 등의 다양한 활용되고 있으며, 활용 목적에 따라 결과가 달라질 수 있지만 전반적인 과정은 동일합니다.
🔴 1단계 : 데이터 수집
학습시키고자 하는 데이터를 수집합니다. 많을수록 좋습니다. 데이터는 예측하고자 하는 결과에 대한 데이터와 예측 과정에서 사용하고자 하는 추가적인 정보 관련 데이터가 필요합니다.
🔵 2단계 : 데이터 입력
위의 정보를 머신러닝 알고리즘에 입력하여 컴퓨터가 학습을 진행하는 과정에서 원하는 데이터를 처리할 수 있는 모델을 생성합니다.
⚫ 3단계 : 새로운 데이터에 모델 적용
데이터를 통해 만들어진 모델을 실제 환경에 적용합니다. 자율주행 자동차에 객체 탐지 모델을 적용하거나, 신용카드 어플에 사기거래 탐지 모델을 적용하는 등 새로운 데이터에 만든 모델을 적용합니다.
기계학습에서 가장 난해한 점은 학습된 모델이 어떤 근거로 판단했는지 판단하기 어렵다는 점입니다. 인공신경망을 쌓아 만든 딥러닝 모델의 경우, 모델 내부를 들여다 보았을 때 수많은 값들이 모델만이 알 수 있는 규칙으로 생성되어 있기 때문에 이를 사람이 해석하는 것은 상당히 어렵습니다.
그러나 현재도 인공지능 모델을 해석하기 위한 많은 연구가 진행되고 있으며 모델이 데이터를 판단하는 근거를 찾아낸다면 기계학습 분야도 새로운 국면을 맞이하게 될 것이라고 생각합니다.
사람이 어린 아이였을 때부터 지금까지 학습을 거쳐 지능을 갖추게 되었듯이 인공지능 또한 대량의 데이터를 통해 학습을 하여 판단할 수 있는 모델이 되어가는 것은 마치 어린아이를 학습시키며 성장시켜 나가는 것과 같습니다. 먼 미래에는 컴퓨터와 인간이 상호 간에 배우고 가르칠 수 있는 세상이 오기를 바라며 이 XAI 시리즈에서는 <📚 Interpretable Machine Learning, 2019> 책을 바탕으로 해석가능한 인공지능(Explainalbe AI; XAI)에 대한 글을 정리하도록 하겠습니다.
.
.
.
References
- Interpretable machine learning, 2.2 what is machine learning?
- https://christophm.github.io/interpretable-ml-book/what-is-machine-learning.html
