
1. 신경망(Neural Network)
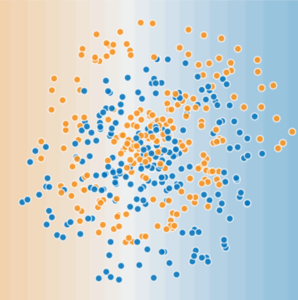
다음의 데이터셋은 선형 모델로는 해결할 수 없다. Neural Network가 비선형 문제를 해결하는데 어떻게 도움이 되는지 알아보기 위해 선형 모델을 그래프로 나타내 보겠다.

신경망은 선형 모델에서 중간값의 히든 레이어를 추가함으로써 출력을 여전히 선형으로 유지하면서도 복잡한 관계를 선형화한다. 위의 그림에서 살펴보면, 히든 레이어에서 각 노란색 노드는 파란색 입력 노드 값의 가중 합이며, 출력은 노란색 노드의 가중합이 된다.

히든 레이어가 추가되더라도 출력을 입력의 함수로 표현하고 단순화하면 입력의 또 다른 가중 합을 얻을 수 있게 된다는 점에서 모델을 선형으로 유지한다.
2. 활성화 함수

비선형 문제를 모델링하기 위해 비선형성을 직접 도입할 수 있다. 우리는 각 히든 레이어의 노드가 비선형 함수를 통과하도록 할 수 있다.
위 그림의 그래프로 나타낸 모델에서 히든 레이어 1의 각 노드 값이 비선형 함수로 변환된 후에 다음 레이어의 가중 합으로 전달되었다. 이 비선형 함수를 활성화 함수라고 한다.
(1) 시그모이드 활성화 함수
시그모이드 활성화 함수는 가중 합을 0과 1 사이의 값으로 변환한다.

(2) 정류 선형 유닛 활성화 함수(ReLU)
정류 선형 유닛 활성화 함수는 시그모이드와 같은 매끄러운 함수보다 조금 더 효과적이지만 훨씬 쉽게 계산할 수 있다.
ReLU의 우월성은 경험적 결과를 바탕으로 하며, 이는 ReLU의 반응성 범위가 더 유용하기 때문일 것입니다. 시그모이드의 반응성은 양측에서 상대적으로 빨리 떨어진다.

사실 어떠한 수학 함수라도 활성화 함수의 역할을 할 수 있습니다. 가 활성화 함수를 나타낸다고 가정한 후 네트워크 노드 값은 위와 같은 수식으로 나타낼 수 있다. 텐서플로우에서는 다양한 활성화 함수를 바로 사용할 수 있지만 보통 ReLU로 시작하는 것이 좋다.
3. 신경망 학습
(1) 실패 사례
몇 가지 일반적인 이유로 인해 역전파에서 문제가 나타날 수 있다.
(2) 경사 소실
입력 쪽에 가까운 하위 레이어의 경사가 매우 작아질 수 있다. 심층 네트워크에서 이러한 경사를 계산할 때는 많은 작은 항의 곱을 구하는 과정이 포함될 수 있다.
하위 레이어의 경사가 0에 가깝게 소실되면 이러한 레이어에서 학습 속도가 크게 저하되거나 학습이 중지된다.
ReLU 활성화 함수를 통해 경사 소실을 방지할 수 있다.
(3) 경사 발산
네트워크에서 가중치가 매우 크면 하위 레이어의 경사에 많은 큰 항의 곱이 포함된다. 이러한 경우 경사가 너무 커져서 수렴하지 못하고 발산하는 현상이 나타날 수 있다.
batch 정규화를 사용하거나 학습률을 낮추면 경사 발산을 방지할 수 있다.
(4) ReLU 유닛 소멸
ReLU 유닛의 가중 합이 0 미만으로 떨어지면 ReLU 유닛이 고착될 수 있다. 이러한 경우 활동이 출력되지 않으므로 네트워크의 출력에 어떠한 영향도 없으며 역전파 과정에서 경사가 더 이상 통과할 수 없다. 이와 같이 경사의 근원이 단절되므로, 가중 합이 다시 0 이상으로 상승할 만큼 ReLU가 변화하지 못할 수도 있다.
학습률을 낮추면 ReLU 유닛 소멸을 방지할 수 있다.
(5) 드롭아웃 정규화
신경망에는 드롭아웃이라는 또 하나의 정규화 형태가 유용하다. 이는 단일 경사 스텝에서 유닛 활동을 무작위로 배제하는 방식이다. 드롭아웃을 반복할수록 정규화가 강력해진다.
- 0.0 = 드롭아웃 정규화 없음
- 1.0 = 전체 드롭아웃. 모델에서 학습을 수행하지 않음
- 0.0~1.0 범위 값 = 보다 유용함
.
.
.
강의링크 : 구글 머신러닝 단기집중과정
