
기존 검색 쿼리에서는 테이블 풀스캔이 발생해 쿼리 실행시간이 오래 걸리는 문제가 있었다.
select
pd1_0.product_detail_id,
p1_0.name,
c1_0.name,
p1_0.manufacturer,
p1_0.description,
pd1_0.price,
pd1_0.attribute
from
product_detail pd1_0
left join
product p1_0
on p1_0.product_id=pd1_0.product_id
left join
category c1_0
on c1_0.category_id=p1_0.category_id
where
p1_0.name like '%Chair%' escape '!'
and pd1_0.is_deleted=false

이 문제를 해결하기 위해 FULLTEXT INDEX를 적용하고, 이를 JPA에 적용하며 겪은 여러가지 문제에 대한 트러블 슈팅을 정리한 글이다.
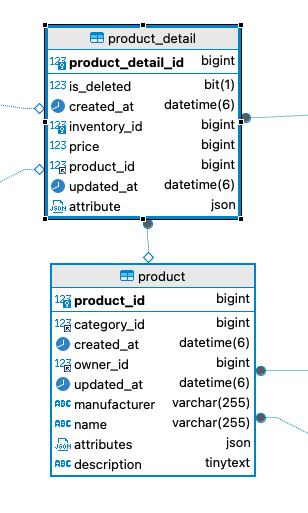
이 글에서 사용한 product, product_detail 의 ERD는 다음과 같다.
FULLTEXT INDEX
검색을 최적화 하는 방법을 찾아보다 풀 텍스트 인덱스에 대해 알게 되었다.
상품 이름을 조회할때 like 앞뒤로 % 가 붙은채로 연산을 하게 되면 시작점을 알 수 없기 떄문에 인덱스를 타지 못하게 된다.
이 문제를 해결하기 위해 풀 텍스트 인덱스를 사용하기로 했다.
FULLTEXT INDEX는 한 컬럼의 데이터를 토큰별로 나눠 인덱싱을 하는 기법이다.
예를들어 I love you 라는 데이터를 FULLTEXT INDEX로 인덱싱을 한다고 해보자.
인덱싱을 위한 파서에는 여러가지가 있다. 이 글에선 그중에서 두가지 파서 Stopword, N-gram 에 대해 설명한다.
Stopword
MYSQL FULLTEXT INDE의 기본동작이다.
공백, 탭, 문장 기호, 커스텀 문자 등을 지정해 해당 단어를 기준으로 토큰을 나눈다.
ex) I, love, you
이 파서의 장점은 검색시 불필요한 단어를 제외해 인덱스를 효율적으로 구성할 수 있다는 점이다.
하지만 이렇게 제외되는 단어로 인해 정보의 손실이 발생할 수 있다.
예를들어 상품 이름이 "아이폰15" 라고 한다면, 토큰은 ["아이폰15"] 로 생성되기 때문에 "아이폰" 으로 검색하게 된다면 결과를 찾지 못하게 되는 것이다.
N-gram
고정된 크기만큼 문자열을 토큰으로 나누게 된다.
ex) 2-gram : Il, lo, ov, ... ou
이 파서는 모든 부분 문자열을 생성하기 때문에 정확한 검색 결과를 얻을 수 있다.
하지만 n 값에 따라 인덱스가 커질 수 있고, 설정이 복잡하다는 단점이 있다.
MySQL FULLTEXT INDEX 구성
실제 쇼핑몰의 상품명을 본다면 보통 의미있는 단어들로 쪼개어져 있어 N-gram 보다는 StopWord 가 더 효율적이라고 생각했다.
또한 설정에 있어 복잡함이 없기 때문에 이번 프로젝트에서는 StopWord 를 사용해 인덱스를 구성하기로 했다.
구성 방법을 알아보자.
MySQL에서 FULLTEXT인덱스는 기본적으로 StopWord 를 사용하기 때문에 인덱스 설정은 생각보다 어렵지 않다.
alter table product add FULLTEXT(name);product 테이블의 name 컬럼으로 FULLTEXT 인덱스를 생성한다.

MySQL 쿼리에서 FULLTEXT INDEX 태우기
인덱스가 있더라도 like %query% 를 그대로 쓴다면 인덱스를 타지 않는다.
인덱스를 태우려면 쿼리또한 변경해야 한다.
아래는 기존 where 문이다.
where
p1_0.name like '%Chair%' escape '!' 아래는 변경된 where 문이다.
WHERE
MATCH(p1_0.name) AGAINST ('Chair')이제 실행 계획을 분석해 보자.
하지만 실행계획을 분석한 결과 product 테이블에서는 풀스캔이 발생하지 않았지만 product_detail 테이블에서 풀스캔이 발생하게 되었다.

이유는 join에 참여하는 드라이브 테이블이 인덱스가 적용된 product 테이블이 아닌, product_detail 테이블 이기 때문.
드라이브 테이블을 product_detail 에서 product로 변경해주자.
이전 쿼리
explain
select
pd1_0.product_detail_id,
p1_0.name,
c1_0.name,
p1_0.manufacturer,
p1_0.description,
pd1_0.price,
pd1_0.attribute
from
/* 드라이브 테이블 변경 */
product_detail pd1_0
left join
product p1_0
on p1_0.product_id=pd1_0.product_id
left join
category c1_0
on c1_0.category_id=p1_0.category_id
where
p1_0.name like '%Chair%' escape '!'
and pd1_0.is_deleted=false 변경 후 쿼리
explain
SELECT
p1_0.name AS product_name,
c1_0.name AS category_name,
p1_0.manufacturer,
p1_0.description,
pd1_0.price,
pd1_0.attribute
FROM
/* 드라이브 테이블 변경 */
product p1_0
LEFT JOIN
product_detail pd1_0
ON p1_0.product_id = pd1_0.product_id
LEFT JOIN
category c1_0
ON c1_0.category_id = p1_0.category_id
WHERE
MATCH(p1_0.name) AGAINST ('Chair')
AND pd1_0.is_deleted = false 실행계획을 분석하면 원하던대로 인덱스를 타고 조회하는것을 확인할 수 있다.

카운트 쿼리도 like 대신 MATCH ... AGAINST 을 사용하고 실행계획을 분석해보면 풀스캔에서 FULLTEXT INDEX 스캔으로 줄어들은것을 확인할 수 있다.

JPA 설정
JPA의 장점중 하나는 추상화를 통해 구체적인 데이터베이스와 상관 없이 개발을 할 수 있다는 점이다.
하지만 이점이 안타깝게도 특정 데이터베이스에서만 제공하는 기술을 사용하는데에는 제약을 주게 된다.
위에서 설명한 FULLTEXT INDEX 또한 MySQL에서 제공하는 기능으로 JPA 표준으로는 제공하지 않는다.
그래서 이 기능을 사용하기 위해선 커스텀 함수를 등록해 사용해야 한다.
커스텀 함수 등록
커스텀 함수에 대한 자세한 등록은 아래 글에서 설명한다.
https://velog.io/@jhkim31/하이버네이트-6-사용자-정의-함수-등록
이번에 등록해야 하는 함수는 FULLTEXT INDEX를 사용하는 where 절의 match ... against 다.
이를 위해 커스텀 함수를 만들어 줬다.
FULLTEXT_MATCH_functionContributor.java
public class FULLTEXT_MATCH_functionContributor implements FunctionContributor {
@Override
public void contributeFunctions(FunctionContributions functionContributions) {
functionContributions
.getFunctionRegistry()
.registerPattern("fulltext_match", "match(?1) against(?2)",
functionContributions.getTypeConfiguration().getBasicTypeRegistry().resolve(BOOLEAN));
}
}match 와 against 를 따로 등록하지 않고, 어차피 한번에 사용할 것이기 때문에 fulltext_match 라는 하나의 함수로 등록하고 파라미터를 두개 받아 사용하기로 했다.
where 절에서 사용하는 함수이기 때문에 BOOLEAN 타입으로 리턴한다.
커스텀 함수 사용
QueryDSL을 사용해 검색 동적 쿼리를 작성하고 있기에 함수를 적용하는데에는 큰 어려움이 없었다.
BooleanExpression 을 리턴하던 기존 like 를 사용하던 검색 조건을 커스텀 함수를 사용하도록 변경해줬다.
기존 SearchRepositoryImpl.java
private BooleanExpression nameLike(String query) {
if (query == null) {
log.error(ErrorCode.NO_SEARCH_QUERY.getLogMessage());
throw JshopException.of(ErrorCode.NO_SEARCH_QUERY);
}
return product.name.like("%" + query + "%");
}변경 SearchRepositoryImpl.java
private BooleanExpression nameLike(String query) {
if (query == null) {
log.error(ErrorCode.NO_SEARCH_QUERY.getLogMessage());
throw JshopException.of(ErrorCode.NO_SEARCH_QUERY);
}
return Expressions.booleanTemplate("fulltext_match({0}, {1})", product.name, query);
}BooleanExpression 을 사용해 커스텀 함수를 사용하도록 변경한다.
인덱스 설정
match ... against 는 인덱스를 가지고 조회를 하는 쿼리다. 때문에 인덱스가 없다면 SQLException 이 발생하게 된다.

하지만 JPA에서 FULLTEXT INDEX는 지원하지 않기 때문에 우회방법으로 이를 적용해야 한다.
내가 선택한 방법은 @Sql 어노테이션과, application.yml 설정방법이다. 두가지 방법중 취사선택해 적용하면 된다.
@Sql어노테이션
테스트 클래스에 다음과 같이 사용한다.
@Sql(statements = "ALTER TABLE product ADD FULLTEXT(name)", executionPhase = ExecutionPhase.BEFORE_TEST_CLASS)실행은 테스트 클래스 시작 전 한번만 호출되도록 ExecutionPhase.BEFORE_TEST_CLASS 로 설정한다.
클래스 범위의 설정에 자주 사용한다.
-
application.yml설정
스프링 부트의 편리함인 자동 설정을 사용할수도 있다.
resources디렉토리에 쿼리문을 위치하고application.yml을 다음과 같이 설정한다.spring: jpa: defer-datasource-initialization: true hibernate: ddl-auto: create sql: init: mode: always encoding: utf-8 schema-locations: classpath:index.sql
spring.jpa.defer-datasource-initialization: JPA 로 스키마가 자동생성된 이후에 실행한다.
애플리케이션이 실행될때 실행되기 때문에 애플리케이션 전역에 걸친 설정에 사용된다.
변경된 쿼리 확인
이제 QueryDSL로 생성된 쿼리를 로그를 통해 확인해보자.
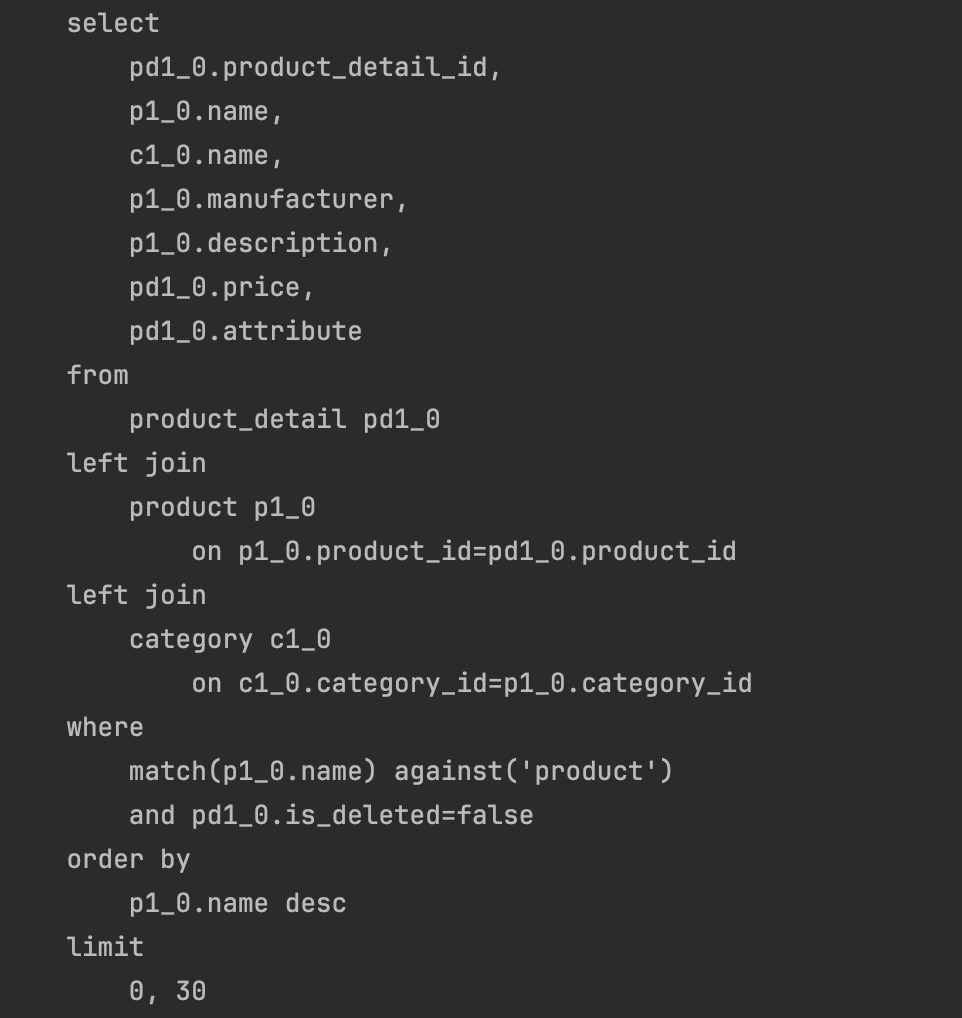
match ... against 가 정상적으로 적용되는것을 확인할 수 있다.
트러블 슈팅
이 과정중 만난트러블 슈팅들과 그 해결방법에 대한 정리다.
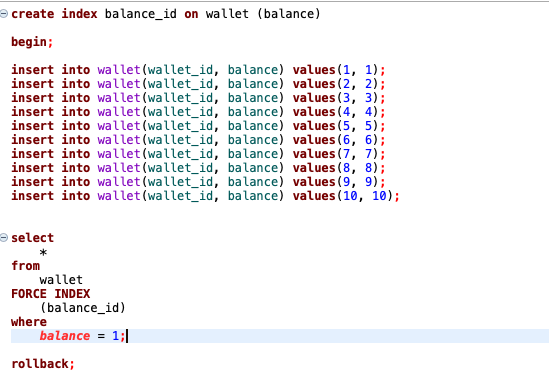
1. 트랜잭션 내에서 생성한 데이터를 FULLTEXT INDEX로 조회시 데이터가 보이지 않음
FULLTEXT INDEX 를 트랜잭션과 사용할때 발생한 문제다.
트랜잭션 내에서 데이터를 생성하고, 이를 FULLTEXT 인덱스를 사용해 조회할경우 데이터가 보이지 않는 문제다.
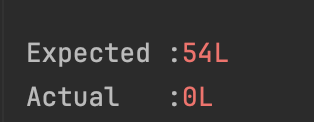
문제의 원인을 찾아보니 MySQL의 FULLTEXT 인덱스와 트랜잭션 처리방식 때문에 발생하는 현상인것 같다.
FULLTEXT 인덱스는 다른 인덱스와 다르게 트랜잭션 내부의 데이터를 바로 인덱싱 처리하지 않고 캐싱을 하게 된다.
그리고 트랜잭션이 끝나면 해당 인덱싱된 결과를 반영하게 된다.
삽입된 문서는 반영 시점에 토큰화 하고 "인덱스 캐시"에 삽입됩니다. 이 캐시는 32Mb의 기본 구성 크기( "innodb_ft_cache_size")를 가지고 있습니다. innodb_ft_cache_size의 용량이 가득차면, 메모리에 있는 데이터를 "인덱스 테이블"에 동기화 될 것입니다. 서버가 정상 종료하는 동안에도, "인덱스 캐시"의 내용이 디스크에 있는 "인덱스 테이블"에 동기화 될 것 입니다. 그러나 서버에 장애가 발생하였고, "인덱스 캐시"의 내용이 "인덱스 테이블"로 반영되지 않았다면, 서버를 재부팅 한 뒤에 처음에 테이블에 FTS 인덱스(검색하거나 삽입)를 사용할 때, 누락된 문서의 원본 테이블과 다시 토큰화된 데이터부터 "인덱스 캐시"를 추가합니다.
https://m.blog.naver.com/jjjhyeok/220204177184
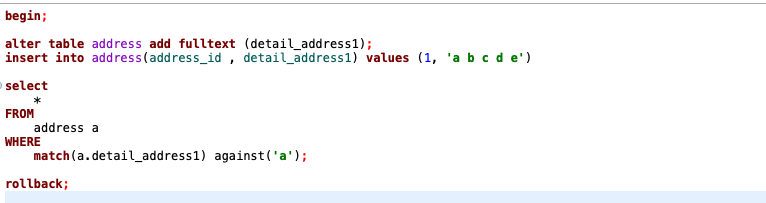
실험
궁금해서 직접 쿼리를 날려 실험을 해봤다.
FULLTEXT INDEX
트랜잭션 내부에서 데이터를 삽입하고 인덱스로 조회를 했더니, 삽입한 데이터를 확인할 수 없었다.

일반 인덱스
하지만 일반 인덱스의 경우는 트랜잭션 내부에서 데이터를 넣더라도 인덱스를 통해 조회가 가능한것을 확인할 수 있었다.

정리
FULLTEXT는 트랜잭션 내부에선 인덱싱 되지 않는다. 트랜잭션이 끝나야 데이터가 인덱싱되고 조회를 할 수 있다.
2. StopWord FULLTEXT INDEX 검색 결과
StopWord 는 공백, 탭, 구분문자 등으로 토크나이징해 인덱싱을 하게 된다.
그러다 보니 검색시 정보의 손실이 발생할 수 있다.
예를들어 상품명이 "아이폰15" 일때, StopWord 로 FULLTEXT 인덱싱 하게 되면 결과는 ["아이폰15"] 로 인덱싱 되게 된다.
이때 검색어를 "아이폰" 으로 검색하게 되면 검색 결과가 나오지 않게 된다.
이럴때 정규식을 사용할 수 있다.
예를들어 FULLTEXT로 인덱싱된 "아이폰15" 상품명을 검색할때 다음 쿼리로 검색하면 검색 결과가 나오지 않는다.
select
*
from
product p
WHERE
match(p.name) against('아이폰')
against에 정규식을 사용하면 검색을 할 수 있다.
select
*
from
product p
WHERE
match(p.name) against('아이폰*')
정리
FULLTEXT 인덱싱 결과에도 정규식을 사용할 수 있다.
하지만 이는 like 절을 사용한 정규식보다는 훨씬 빠른 속도로 검색을 할 수 있다.
like 절에서 정규식을 사용하기 위해선 검색 쿼리 앞뒤에 애스터리스크를 박아 넣어야 한다.
하지만 FULLTEXT 인덱싱이 되어있다면, 토큰별로 분리가 되어있어 뒤에만 애스터리스크를 넣어 인덱스를 이용할 수 있다는 큰 차이가 있다.
