시리즈 여는 글
GPT-123421 버전이 나오기 전에 Deep Dive 해야하지 않나싶은 생각이 들어서 일단 모든 사이드 프로젝트 & 공부의 초점을 이렇게 맞춰보기로 🥹
오늘의 포스트 목적
- GPT-1 부터 시작해보자
GPT (2018)
-
오리지널 논문(Improving Language Understanding by Generative Pre-Training)을 읽어보자. 짧다.
-
트레이닝 전략은 총 두가지
-
첫번째는 비지도 학습으로 사전학습. 기존의 언어 모델처럼 다음에 나올 단어의 조건부 확률 (ABCD가 주어졌을 때 E를 잘 예측하도록)를 최대화하도록 손실함수를 구성한다.
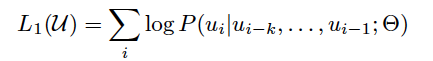
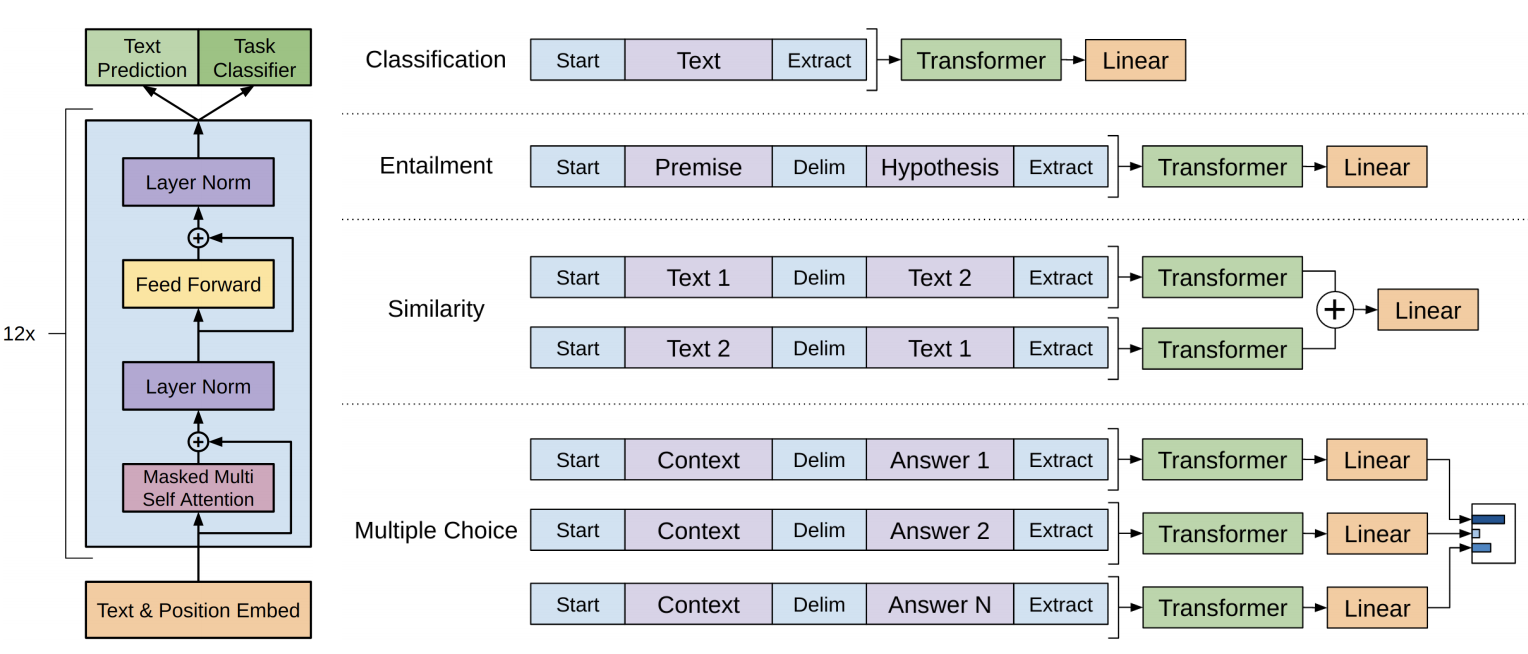
- 이러한 과정을 위한 모델은 트랜스포머의 디코더를 여러겹 쌓는 것으로 구성한다. 아래는 전체 모델의 구조도.

- 두번째는 지도 학습으로 파인튜닝. 딱히 특별한 것은 없다.
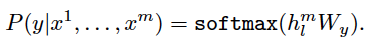
- 논문의 분석 부분에서는 레이어의 수를 쌓으면 쌓을 수록 성능이 증가한다는 점.
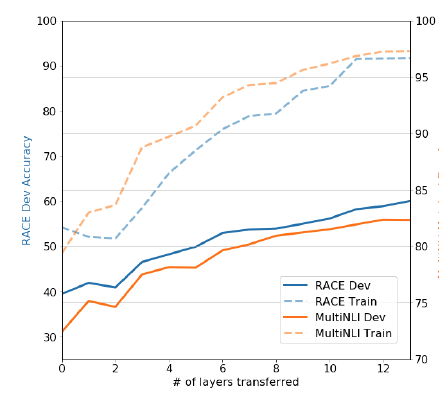
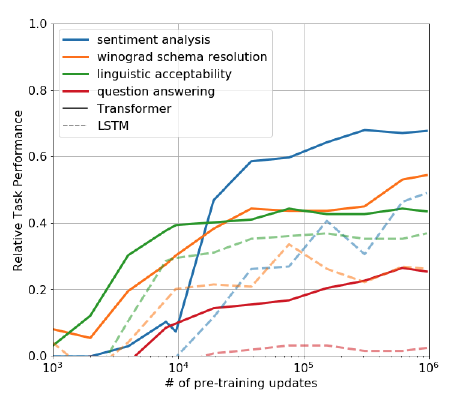
- 왜 사전학습 트랜스포머가 더 효율적인가? 연구진들은 트랜스포머가 LSTM에 비해 언어 구조를 이해하는데 효과적이라는 걸 보여주기 위해 아무것도 학습하지 않은 제로샷 상태로 서브 테스크에 실험했더니 트랜스포머가 LSTM에 비해 더 안정적이고 좋은 성능을 보여준다는 점을 확인.

도파민 중독