Paper
1.[MultiModal] CLIP (Learning transferable visual models from natural language supervision)

대량의 웹데이터를 사전학습해 제로샷 셋팅에서 다양한 물체인식 문제를 정확하고 강건하게 풀수 있는 모델. 이미지와 텍스트 쌍을 모두 입력값으로 받아 두개의 유사도를 잘학습하도록 모델을 디자인했다.
2022년 6월 30일
2.[MultiModal] CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment (ICLR 2023)
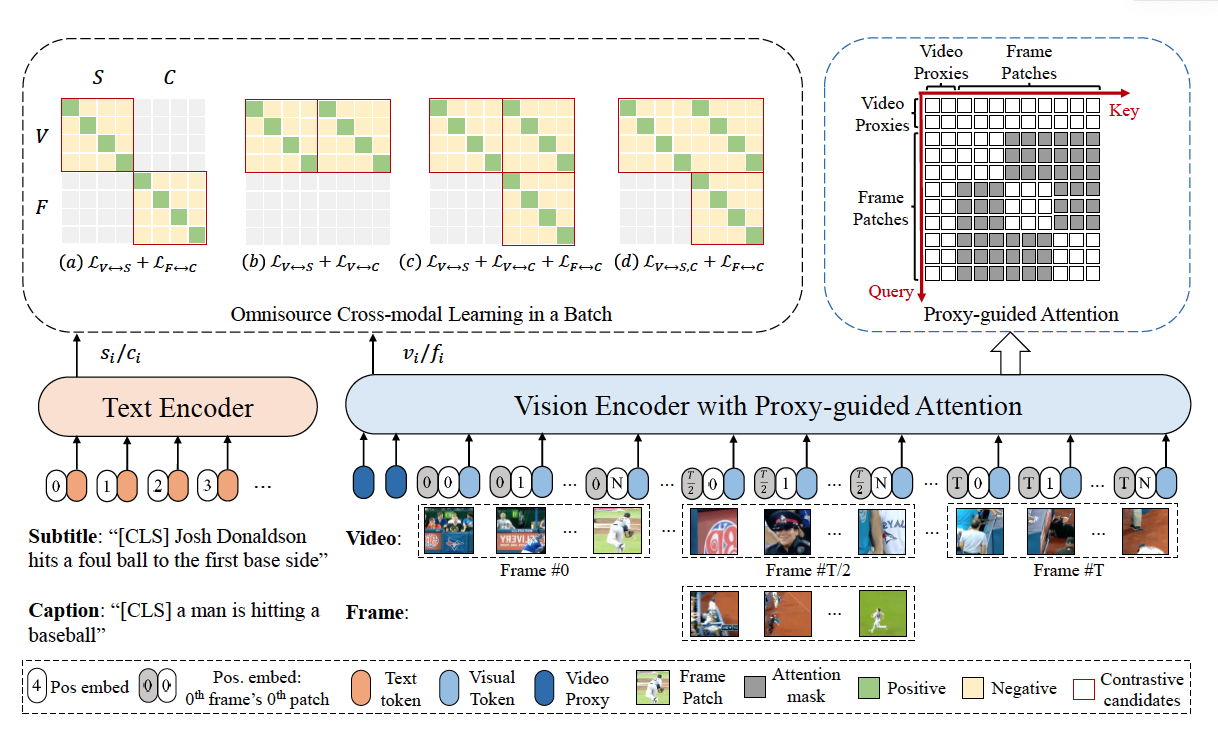
CLIP을 비디오-텍스트 검색 테스크에 활용하기 위한 최적의 방식을 제안하는 논문으로 텍스트는 데이터 품질을 올리고, 비디오는 주요 프레임에 어텐션을 잘 적용하는 문제로 풀어냄
2023년 4월 21일
3.[NLP] Improving Language Understanding by Generative Pre-Training (GPT)
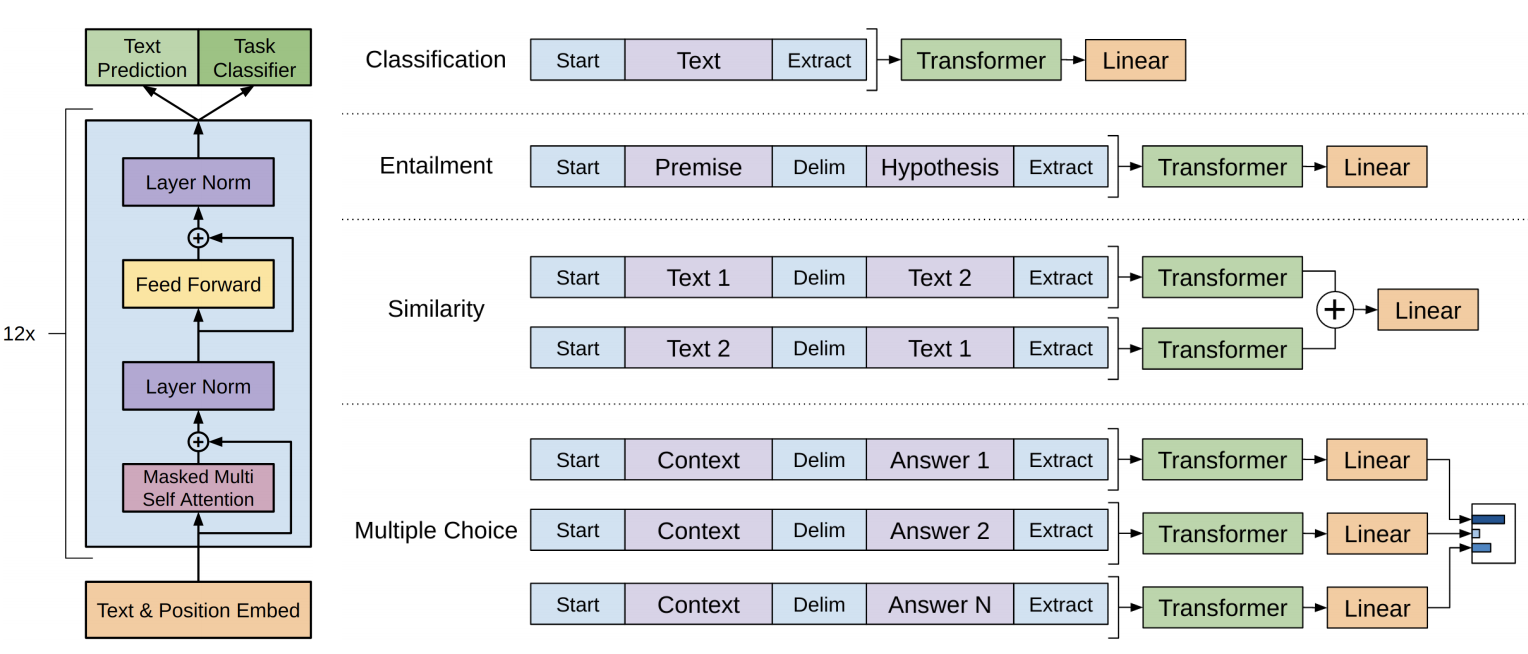
GPT-1 부터 시작해보자. 오리지널 논문 읽기
2023년 3월 20일