[MultiModal] CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment (ICLR 2023)
Paper
빠른 요약 🔎
- CLIP을 비디오-텍스트 검색 테스크에 활용하기 위한 최적의 방식을 제안하는 논문으로 텍스트는 데이터 품질을 올리고, 비디오는 주요 프레임에 어텐션을 잘 적용하는 문제로 풀어냄
- Github: [link]
- Paper: [link]
연구배경
- 최근 CLIP과 같은 사전 학습 이미지-텍스트 모델이 이미지-텍스트 테스크에서 좋은 성능을 보임
- 한편 그동안 잘 훈련된 image representation을 video에 사용하여 이득을 본 사례가 있었음
- 하지만 아직 이미지-텍스트 모델이 비디오-텍스트 테스크에도 적용 가능할지는 아직 연구된 바 없음. 그래서 우리가 한다 🤗
Goal: CLIP을 비디오-텍스트 테스크에 효율적으로 사용할 방법 찾기
-
연구문제
- 비디오-텍스트 테스크를 위해 CLIP을 post-pretraining 할 때의 문제점? ->
Preliminary analysis- What are the factors hindering post-pretraining CLIP from improving performance on video-text tasks?
- 이 문제점을 극복하기 위한 방법은? ->
CLIP-ViP- How to mitigate the impact of these factors?
- 비디오-텍스트 테스크를 위해 CLIP을 post-pretraining 할 때의 문제점? ->
-
Memo📝 post-pretraining이란?
- 대규모 데이터로 사전 학습된 모델을 가져와서 특정 task를 수행할 수 있는 작은 데이터셋에서 추가적으로 fine-tuning하는 것
- 해당 모델이 이미 대규모 데이터에서 일반적인 특징을 학습했기 때문에 적은 양의 데이터로도 높은 성능을 얻을 수 있음
- NLP쪽의 관련 논문은 Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks[link]을 참고
Preliminary analysis
- CLIP은 원래 이미지-텍스트를 위한 것. 그렇다면 이걸 비디오-텍스트에 사용하기 위해 사전 분석 수행
데이터 사이즈에 따른 CLIP의 사전학습 성능 파악
- 분석 포인트: 과연 어떤 데이터를 통해 사전학습 모델을 활용하는 게 좋나?
- 분석 방식
- 사전학습 모델: CLIP-ViT-B/32
- 비디오 데이터 처리 방식: CLIP4Clip 방식 사용 = 비디오는 프레임이 여러개니까 프레임 구간 별 평균을 비디오 피쳐를 사용하는 방식
- 사전학습 데이터: WebVid-2.5M (250만개), HD-VILA-10M(1천만개), HD-VILA-100M (1억개)
- 분석 결과

- 사전학습을 계속할 수록 성능 저하 (과적합)
- 위 현상이 데이터가 적을 수록 더하다
- 결론: 사전학습을 위해서는 양도 많고 다양한 데이터를 쓰자 (HD-VILA-100M)
- 🥹 당연한... 얘기지만 어쨌든 비디오-텍스트에도 허용가능한 얘기라는 걸 보여줬음
사전학습 데이터와 다운스트림 데이터의 차이 파악
-
분석 포인트: HD-VILA-100M으로 사전학습 할 경우 비디오-텍스트 검색 테스크를 잘 수행할 수 있나?
- 보통 사전학습 모델 데이터와 다운스트림 데이터의 도메인이 비슷할 때 성능향상 기대 가능
- 그럼 우리가 정한 사전학습 데이터와 비디오-텍스트 테스크의 데이터는 비슷한 특징을 보이는지 확인하는 부분
-
분석 목표
- 사전학습 데이터와 다운스트림 데이터의 Normalized Mutual Information (NMI)을 비교
- 사전학습 데이터: HD-VILA-100M_sub (원래 데이터셋에 있는 자동 생성 데이터), HD-VILA-100M_cap (저자들이 HD-VILA-100M의 비디오로 자동 자막 생성한 데이터)의 텍스트, WebVid, COCO, CC12M
- 다운스트림 데이터: MSR-VTT, DiDeMO
- Memo📝 NMI란? 두 개의 클러스터링 결과를 비교하는 측정 방법. 클러스터링 결과가 서로 다르다면 NMI 값은 작아지고, 비슷할수록 크게 나옴
- 사전학습 데이터와 다운스트림 데이터의 Normalized Mutual Information (NMI)을 비교
-
분석 방식
- 각 데이터셋의 텍스트의 천개씩 뽑은 뒤 인코딩
- K-means 클러스터링으로 각 텍스트가 사전학습 데이터 출신인지? 다운스트림 데이터셋 출신인지? 분류 수행
- NMI 계산: 높으면 해당 텍스트가 어느 데이터셋에서 나왔는지 맞추는 문제가 쉽다는 얘기 = 두 데이터셋의 특징이 다르다는 얘기
-
분석 결과
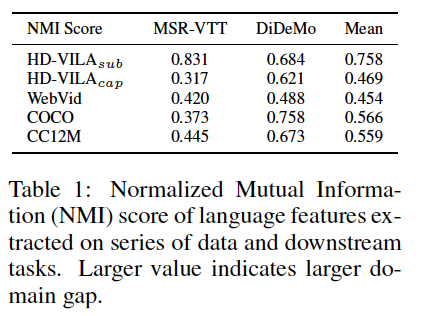
- HD-VILA-100M_sub (원래 데이터셋에 있는 자동 생성 데이터)이 전반적으로 다운스트림 데이터셋과의 갭이 있음
- 결론: HD-VILA-100M의 원래 텍스트를 바로 쓰면 다운스트림 테스크에서 성능을 기대하기 어려우니 방법을 찾아보자
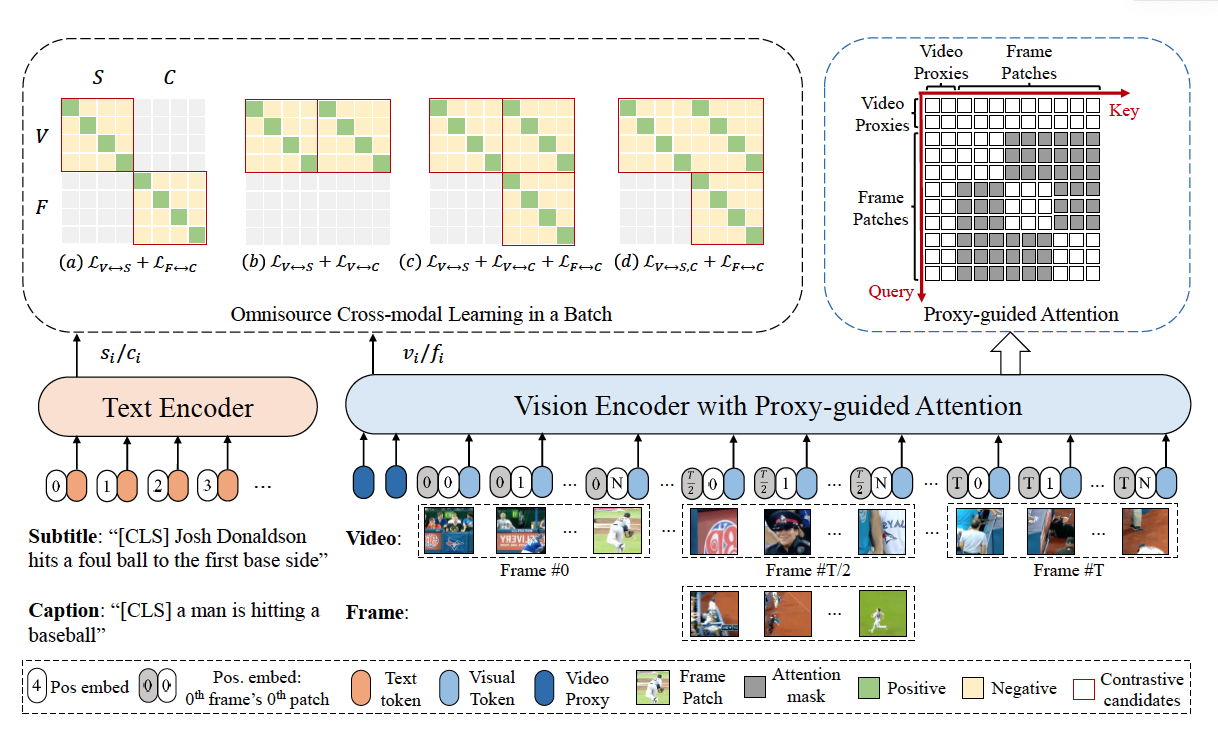
CLIP-ViP = Video Proxy mechanism + Omnisource Cross-modal Learning (OCL)
핵심 아이디어
- 앞선 결과 분석 결과를 토대로 사전 학습 데이터와 다운스트림 테스크의 차이를 줄이기 위한 데이터 생성 방식을 제안
- Vision Transformer (ViT) 모델을 이미지와 비디오 인코딩에 사용가능한 방법 제안 = Video Proxy mechanism
- 비디오-텍스트, 이미지-텍스트의 크로스 모달을 이해하기 위한 방법 제안 = Omnisource Cross-modal Learning
Step 1. 다운스트림 테스크 성능 향상을 위한 사전학습 데이터셋의 텍스트 데이터 개선 (feat. Video Captioning Model)
- 사용 모델: OFA-Caption model
- 방식: 각 비디오의 중간 프레임에 기준으로 이미지 캡셔닝 수행해 자막 생성 (최대 16단어)
Stpe 2. 비디오를 위한 ViT 개조
-
결론부터 말하면 마스킹된 어텐션과 거의 비슷함
-
먼저 ViT를 사용하기 위해 비디오를 이미지로 변환하는 과정부터 시작함
- 각 프레임을 N개 패치로 쪼갬
- 패치에 위치-시간 정보를 임베딩 (spatio-temporal positional embedding)
-
이렇게 만들어진 애를 바로 ViT 넣어서 어텐션을 바로 적용할 수도 있지만... 우리가 하려는 건 비디오만 보려는 게 아니라 추후에 비디오-텍스트 크로스 모달을 하면서 CLIP을 학습해야하기 때문에 저자들은 어텐션에서 비디오 프레임 간의 인터렉션을 잘 포착하는 게 어렵다고 생각함. 실제로도 이 방식은 저자들의 제안보다 성능이 낮았음
-
그래서 제안한게 Proxy-guided Attention. 수식은 어렵지만 아래 그림의 우상단의 그림을 보면 바로 이해감. 마스킹을 통해 (1) 비디오의 전체적인 정보 (BERT의 CLS 토큰처럼)이나 (2) 같은 프레임 안에 있는 애들만 확인해서 어텐션을 수행하는 방식임
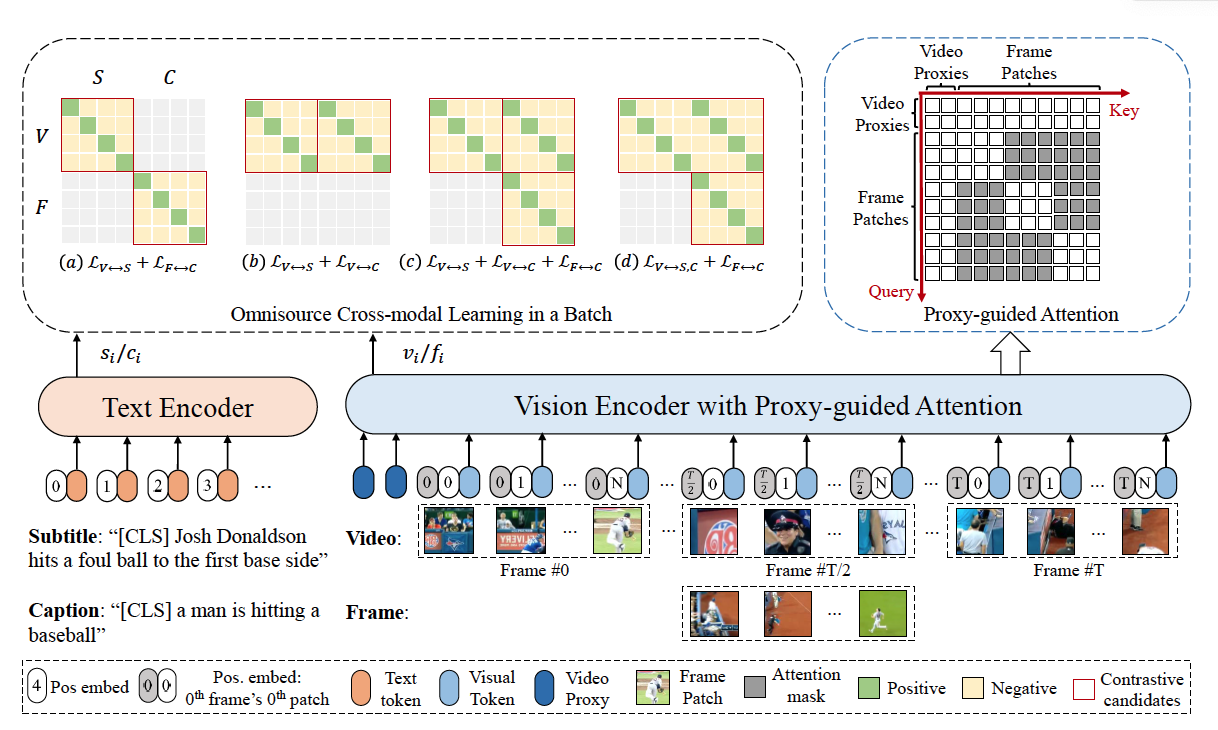
- 아래 표는 제안한 프록시 방식의 성능우위를 보여줌. Full Attention이 앞서 얘기했던 바로 어텐션을 적용한 방식을 의미

Stpe 3. 비디오-텍스트 학습을 위한 크로스모달 방식 제안
-
이것도 그림으로 이해하면 쉬움. 모델 그림의 왼쪽 좌상단에 있는 것처럼 여러가지 모달리티 조합에 대해 Contrative Learning을 테스트 해봤단 얘기
-
고려한 모달리티는 다음과 같으며, 이것들을 잘 조합해 Loss을 구성해 성능상승을 노림
- Video: 전체 비디오 시퀀스 (V), 싱글 프레임(F)
- Text: 오리지널 데이터셋 텍스트(S), 이미지 캡셔닝으로 만든 텍스트 (C)
-
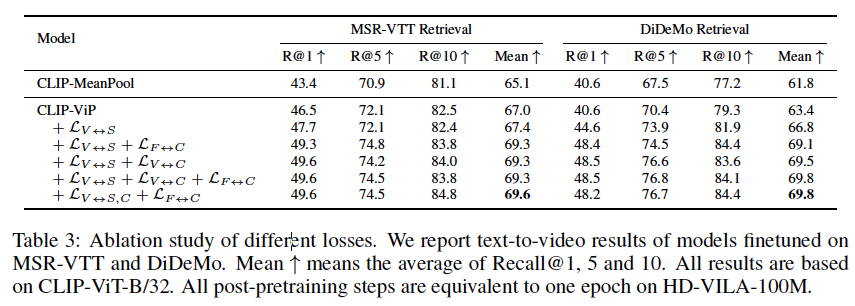
두가지 벤치마크 데이터셋 가장 좋은 성능을 보이는 조합은 아래 표에서 확인
- 🥹 사실 전반적으로 성능이 비슷한데 오리지널 데이터셋 텍스트만 있는건 성능이 꽤 낮음. 따라서 CLIP으로 해당 테스크 수행을 위해서는 텍스트 데이터를 잘 정제하거나 논문처럼 아예 생성하는 작업을 꼭 고려해봐야 할듯.
성능
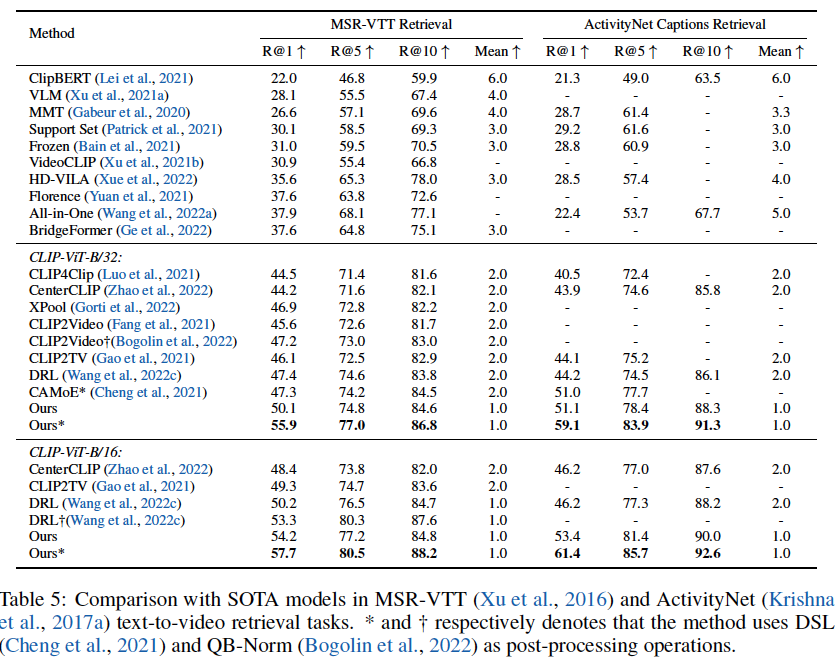
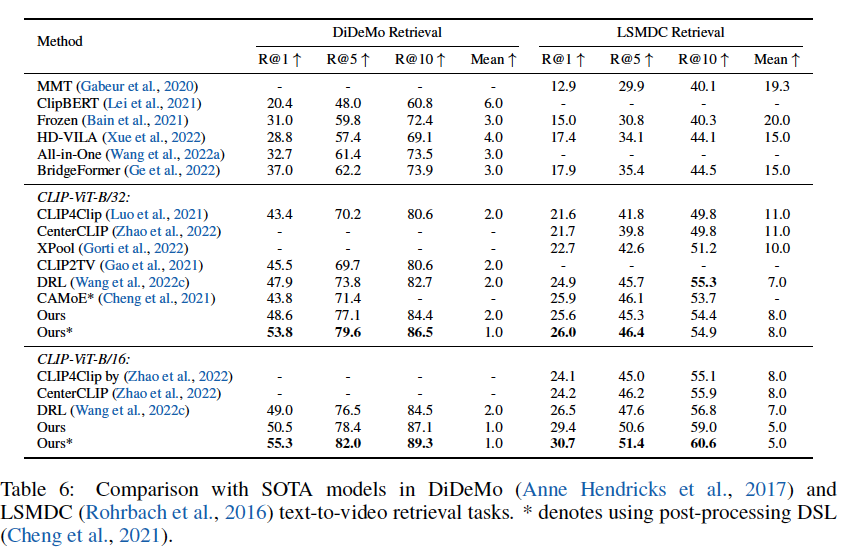
- 4개의 벤치마크 셋에서 SOTA 성능을 보인다
- 주목할 점은 novel Dual Softmax Loss (DSL)를 더해주면 성능이 상승한다는 것. DSL은 비디오, 텍스트 데이터의 일치도를 증대하기 위한 손실함수라고 하는 데 여기서 다루진 않겠다
