[MultiModal] CLIP (Learning transferable visual models from natural language supervision)
Paper

DSAIL@SKKU
Weekly Seminar
2022. 06. 30.
-
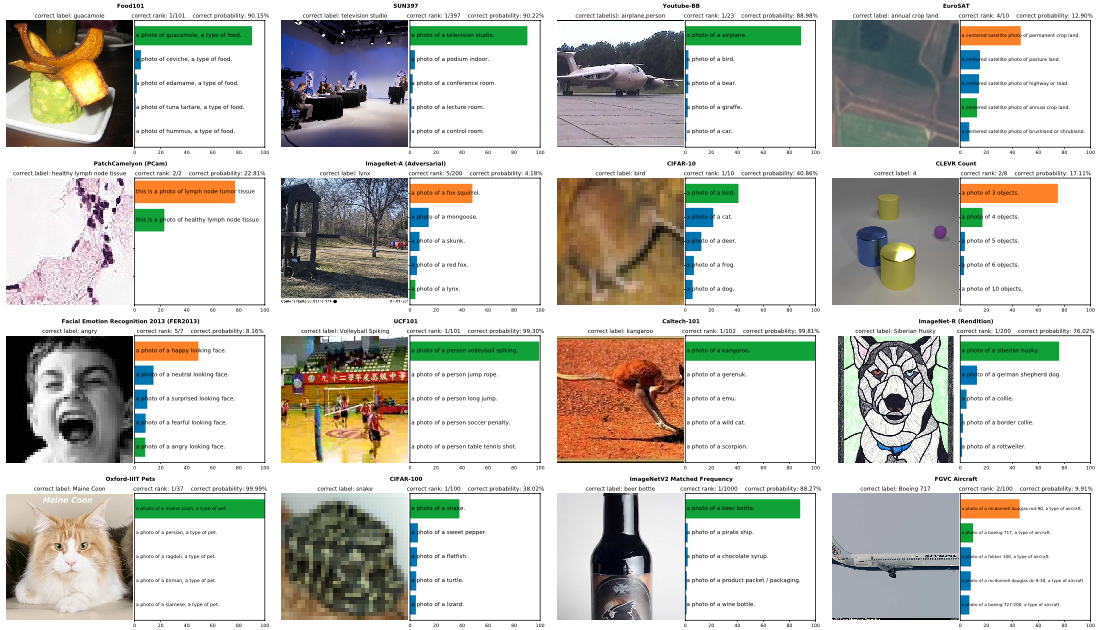
놀랍게도 zero-shot 셋팅에서 훈련한 하나의 classifier를 서로 다른 데이터셋에 적용해본 예시다
-
그리고 이것이 오늘 소개할 OpenAI의 2021년 논문 "Learning transferable visual models from natural language supervision"에서 소개된 방법론으로, 보통 CLIP라고 부른다
-
TD;LR: 대량의 웹데이터를 사전학습해 제로샷 셋팅에서 다양한 물체인식 문제를 정확하고 강건하게 풀수 있는 모델. 이미지와 텍스트 쌍을 모두 입력값으로 받아 두개의 유사도를 잘학습하도록 모델을 디자인했다.
1. Introduction and Motivating Work
- 연구팀은 특정 테스크에 국한되고 만드는데도 시간과 비용이 드는 labeled data 말고, 엄청나게 많은 unlabeled data를 사용하고 싶었다
- Unlabeled data을 이용해 훈련하면 차고넘친다는 점 외에도 미리 정해진 클래스에 국한되지 않고 이미지 분류를 수행할 수 있다는 점, 그래서 벤치마크 데이터와 실제 데이터의 갭을 줄일 수 있다는 장점이 있다
- 그래서 이러한 연구배경으로 시작하는게 NLP에서 유명한 GPT고, GPT 외에도 많은 대규모 언어모델 (language model; LM)들은 이런걸 차용하고 있었는데, 연구팀은 이런 방식을 컴퓨터 비전에도 도입하고 싶었으나...
Could scalable pre-training methods which learn directly from web text result in a similar breakthrough in computer vision?
- 컴퓨터 비전에서는 이런 접근방식이 쉽지않았고, 여전히 ImageNet과 같은 labeled dataset을 사용하는게 보편적이었다. 물론 그전에 비슷한 시도를 한 연구가 있었으나 성능이 낮다는 치명적인 결함이 있었다 😞
This is likely because demonstrated performance on common benchmarks is much lower than alternative approaches.
2. Approach
-
Point 1: Natural language supervision
- 자연어를 적극적으로 이용하므로서 자연어 안에 내재되어 있는 지식들을 활용하자!
At the core of our approach is the idea of learning percep- tion from supervision contained in natural language.
- 이러면 양을 늘리기에도 용이하고 (labeled data은 양을 늘릴려면 라벨링의 늪에 다시 빠져야한다)
- 비지도학습 방법을 적용하기에도 용이해지고 (흔히 아는 word2vec 등 언어모델은 비지도학습 방법으로 사전 훈련을 했다)
- downstream 테스크를 위한 zero-shot transfer를 셋팅하기에도 용이하다
- 자연어를 적극적으로 이용하므로서 자연어 안에 내재되어 있는 지식들을 활용하자!
-
Point 2: Multimodal learning
-
이미지와 텍스트를 잘 연결하는 visual representation을 만들기 위해서 자연어를 잘 써보자고 했는데, 그렇다면 어떻게 자연어를 이용할 수 있을까?
-
우선, 이전 연구(VirTex) 처럼
이미지 -------> 이미지 캡션의 모델(image-to-caption language model)을 시도해봤는데, 스케일링하기가 힘들어서 제외 -
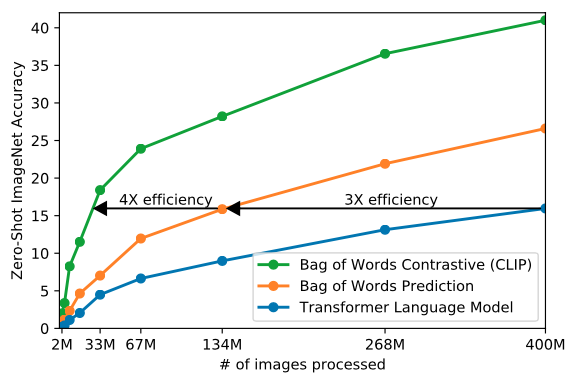
Vision Transformer도 사용해봤는데, 제로샷 셋팅에서 CLIP의 방법론 보다 낮았다. 아래 그림의 파란색 라인을 살펴보자
-
연구팀은 위의 두 방법이 잘 작동하지 않는 이유에 대해 이미지와 등장하는 적확한 단어를 맞추려고 했기때문이라고 설명한다. 사람이 이미지에 대해 굉장히 다양한 텍스트를 만들어 내기 때문에 이 테스크는 굉장히 어려운 테스크라 할 수 있다
-
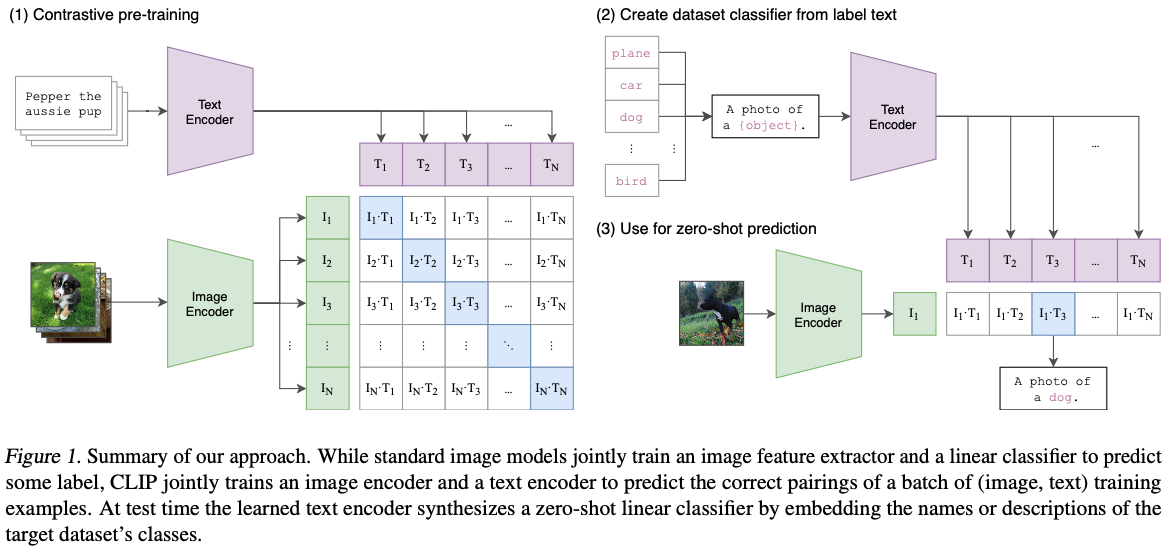
그래서 연구팀은 아래의 모델 아키텍쳐처럼 전체 텍스트를 모두 입력데이터로 사용한다. 그림의 왼쪽 상단을 살펴보자
-
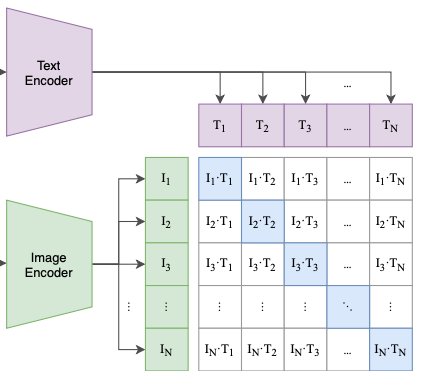
텍스트와 이미지의 관계를 잘 이해할 수 있는 representation을 만들기 위해 contrastive representation learning을 사용한다. 이 기법은 representation이 데이터들 간의 유사도를 잘 학습하도록 하는 방법이고, 선행연구들에서 이러한 방법이 visual representation에 효과적이라는 것이 소개되기도 했다
-
위의 그림의 파란색🟦 박스에 주목해보자. 입력으로 넣은 이미지🟩-텍스트🟪는 각자의 인코더를 지나서 multi-modal embedding 안에서 만나게 된다
-
이렇게 쌍으로 주어진 이미지-텍스트가 가장 유사한 조합이라고 가정하고, 모델은 이미지🟩-텍스트🟪의 각 피쳐의 유사도가 높아지는 방향으로 학습을 진행한다(그리고 쌍이 아닌 애들의 유사도는 낮아지는 식으로). 여기서는 유사도를 cosine similarity로 정의했고, 이렇게 계산된 유사도는 softmax를 거친다. 아래 코드로 보면 더욱 더 직관적으로 확인할 수 있다

-
그렇담 여기서 Loss Function은 어떻게 설정할까? 연구팀은 이미지 관점과 텍스트 관점을 모두 볼 수 있도록 두개의 손실함수를 사용했다. 여기서 이미지 관점과 텍스트 관점이란 간단하게 multi-modal embedding의 행(이미지🟩)-열(텍스트🟪)을 의미한다
-
-
Point 3: Zero-shot transfer
- 위의 방식대로 사전학습을 진행했는데, 이 모델을 우리가 원하는 downstream 테스크에 사용하려면 어떻게 해야할까?
- CLIP은 unlabeled 데이터를 쓰고, 다양한 이미지 분류를 수행하기위해 제로샷 셋팅을 지향하고 있으므로, 별도의 fine-tuning 과정은 없다
- 아래 그림처럼 우리가 할일은 주어진 데이터셋의 class label을 CLIP에서 요구하는
A photo of a {object}"형태로 바꿔주는거고, 모델은 주어진 이미지와 제일 유사한 텍스트를 선택한다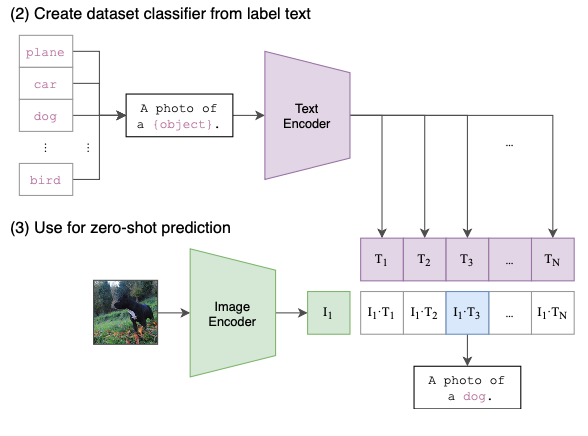
-
위의 과정을 코드로 표현하면 다음과 같다
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
y = np.arange(top_probs.shape[-1])3. Experiments
-
사전학습에 사용한 데이터: 웹검색을 통해 얻은 4억개의 이미지-텍스트 쌍으로 이뤄진 데이터셋(WIT for WebImageText)을 사용
- 기존의 이미지 캡셔닝에서 쓰이던 데이터는 적어서 안쓰고 새로 모았다
-
Image Encoder: ResNet 계열, Vision Transformer (ViT)를 모두 실험했다
-
Text Encoder: GPT-2에서 사용한 변형된 Transformer을 사용했고, 마지막 토큰(
[EOS])을 텍스트 피쳐로 이용했다 -
Experiment Design: 여태까지 모델을 설계한 배경 중 하나가 다양한 테스크에 대응하는 모델을 만들기 위한 것이였으므로, 굉장히 다양한 도메인의 데이터셋을 실험했다. 아래는 실험중에서 재미있는 결과들(summerized by this video)만 골라서 정리해보겠다.
-
Effect of Prompt engineering
- 흥미롭게도
A photo of a {label}"🟦대신A photo of a {label}, a type of pet"🟩로 입력 텍스트를 살짝 바꾸면 더 빠르고, 정확한 결과를 얻을 수 있다는 점이 공유됐다.
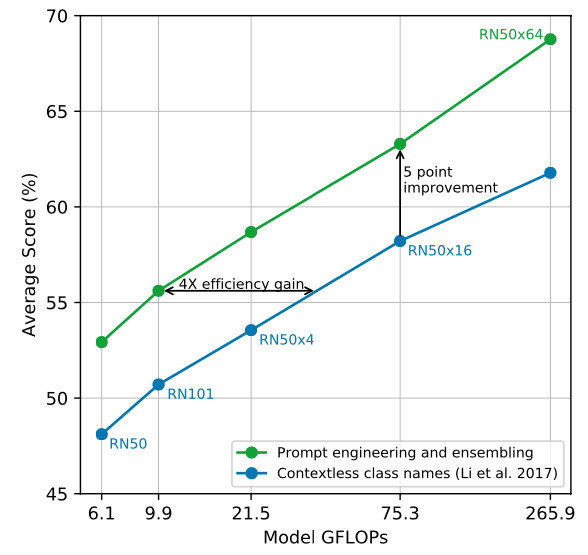
- 흥미롭게도
-
Zero-shot CLIP vs. Fully supervised baseline:
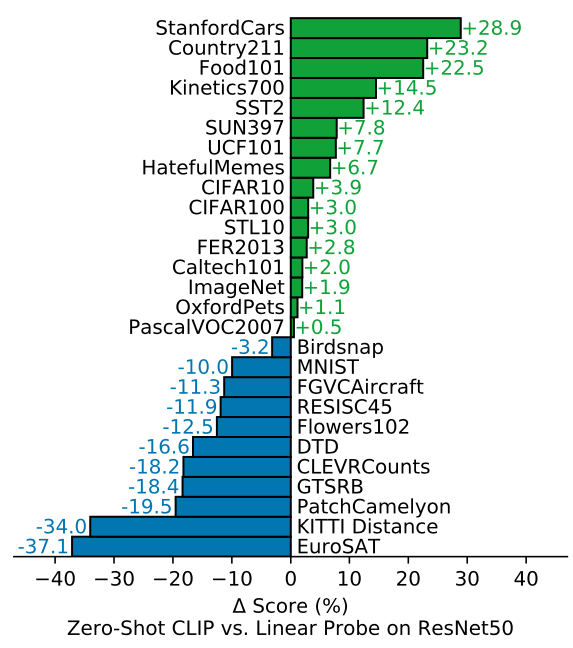
- 여기서 Fully supervised baseline이란? 우리가 이미지 분류에서 가장 많이 쓰이는 사전학습된 ResNet 모델을 가져와서, 마지막 레이어를 우리가 원하는 분류 테스크에 맞게 fully connected layers로 교체한 모델이다
- 많은 데이터셋들에서 제로샷 셋팅의 CLIP이 지도학습한 베이스라인을 능가한다! 심지어 ImageNet 조차도 말이다 🤭
- 하지만 specialized, complex, or abstract tasks에서 잘 작동하지 않았다. 아마 위성(EuroSAT)이나 종양(PatchCamelyon) 데이터셋이 그 예시인데, 아마 웹데이터를 사용했기라는 추측이 있다
- 모두의 튜토리얼인 MNIST에서 잘 작동하지 않았다
- [TMI] 몇몇 데이터는 이미지-텍스트쌍이 제대로 맵핑되어있지 않아서... 1저자가 열심히 맵핑했다는 일화를 아카이브 버전 footnote에 적어두었다
Alec learned much more about flower species and German traffic signs over the course of this project than he originally antic- ipated.

-
Few-shot learning
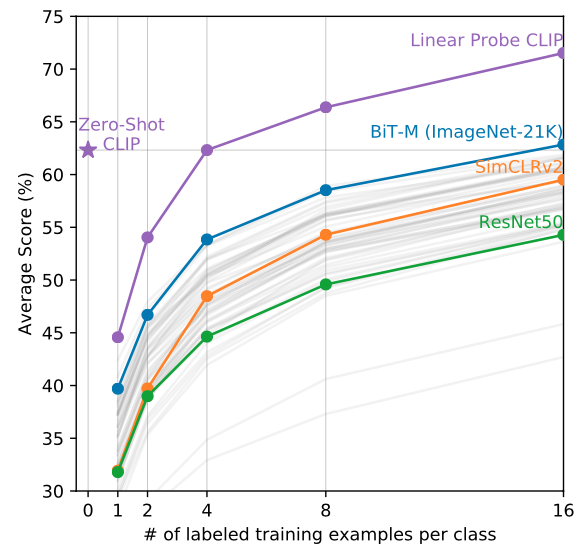
- 또 흥미로운 점은 제로샷 셋팅✡️이 퓨샷 셋팅🟦🟧🟩보다 성능이 잘온다는 점
- 같은 CLIP끼리만 비교해보면 트레이닝 이미지가 늘수록 잠깐 감소하다가 4장 이상에 이르러서야 제로샷의 성능을 능가한다는 점이다
-
Scale up!
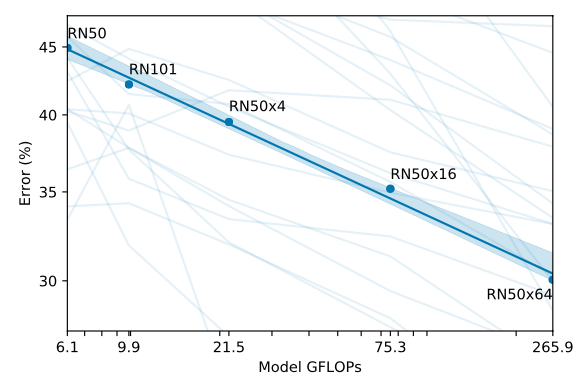
- 요즘 모델들의 트랜드는 연산량을 잔뜩 늘려서 에러를 줄이는 건데요. 이러한 트랜드에 맞게 연산량이 증가할 수록 36개 데이터에 대한 평균 에러도 줄어드는 트랜드를 보이지만
- 옆에 있는 흐릿한 선로 표현된 개별 데이터선들을 살펴보면 데이터셋마다 다른 걸 볼 수 있고 이 또한 후속적으로 분석해볼 사항이라고 볼 수 있다
-
vs. Other Baseline
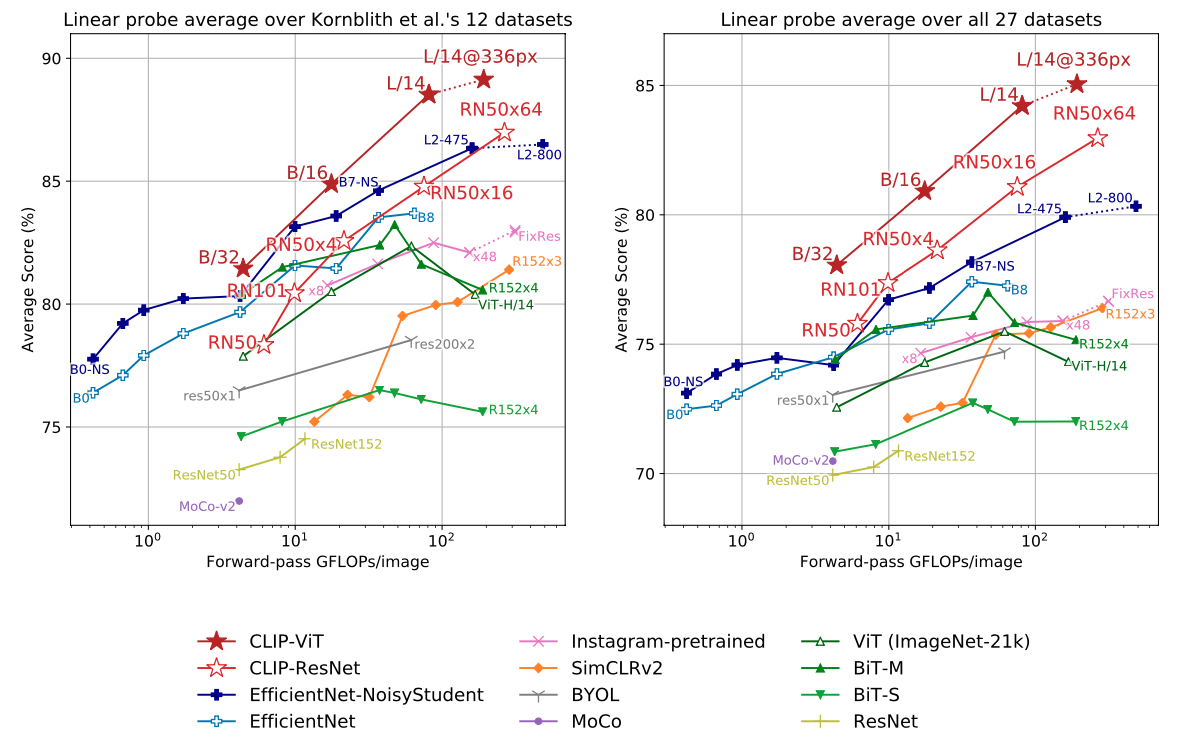
- 다른 베이스라인하고 비교해봐도 성능이 좋다
-
Robustness
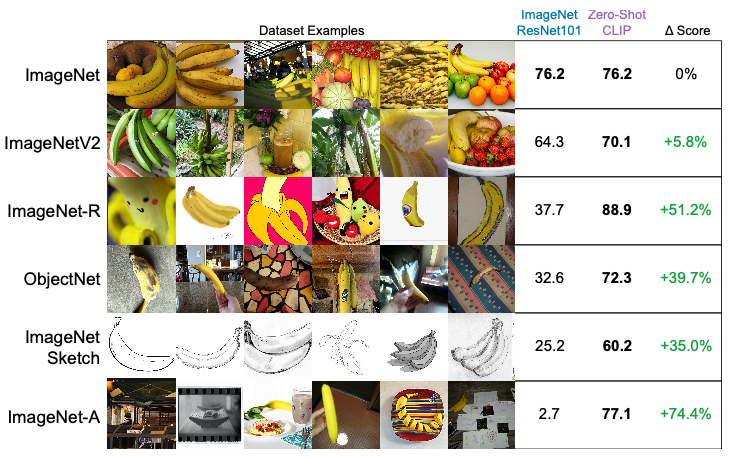
- 연구팀은 이미지넷으로 학습한 사전 모델과도 비교를 했는데, 여기서의 초점은 어떻게 이미지넷과 차이가 많이 나는 이미지에 대해서도 잘 작동하는지를 확인하는 것이다
- 위의 그림에서도 보이듯이 바닐라 ImageNet+ResNet101 모델보다 다양한 데이터 형태에서 강건하게 작동하는 걸 알 수 있다
4. Limitation
- OpenAI 블로그에서 정리된 한계점은 크게 두가지다
- 일반적인 물체인식은 잘하지만... 전문적이고(종양사진 등), 복잡하고(차3 거리를 재고), 추상적인(물체를 세고) 문제에서는 랜덤하게 맞추는 것보다 조금 더 잘할뿐이다
- 일반적인 테스크를 수행하기 위해 대량의 웹데이터로 사전학습을 했지만 웹에서 적은 이미지(MNIST의 손글씨 같은)에서는 잘 작동하지 않기때문에 프롬프트 엔지니어링을 해볼 필요가 있다는 점이다
5. Borader Impacts
-
요즘 많은 컨퍼런스들에서 이 모델의 단편적인 컨트리뷰션뿐만 아니라 연구실 밖, 커뮤니티 밖에서 좀 더 사회적이고 넓은 문제들을 논의하는 걸 요구하고 있는데, OpenAI는 그러한 논의들을 어떻게 전개하는지 볼 수 있는 좋은 참고자료다.
-
연구팀은 젠더/인종의 얼굴을 분류하는 문제로 Bias 이슈를 다뤘고, 제로샷이 용이하다는 점을 들어서 유명인의 얼굴을 분류하는 문제로 surveillance 이슈를 다루고 있다.
