DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances
Abstract
- 기존 대화 context를 토큰의 선형 시퀀스로 보고 토큰의 self-attention을 통해 다음 단어를 생성하는 토큰 수준의 인코딩은 발언간
담화수준의 일관성 탐색을 방해한다. - 이에 이전 PLM 기반 대화 모델을 향상시키는 새로운 대화 응답생성 모델인 DialogBERT를 제시한다.
Introduction
- 본 논문에서는 계층적인 트랜스포머 구조를 도입하고, 담화수준의 일관성을 모델링하기 위한 목적함수를 제안한다.
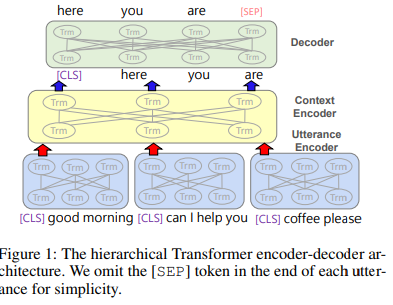
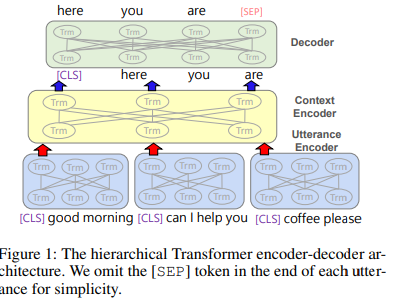
- transformer 인코더를 통해 대화 발화를 인코딩 한 후, 담화수준(discourse-level)의 transformer를 사용하여 앞선 결과 벡터를 인코딩하여 전체 대화 context의 표현을 얻는다.
- BERT와 유사하게 두가지의 훈련 목표를 제안한다.
- masked context regression : 무작위로 선택된 발화를 마스킹한 후 마스킹된 발화에 대한 인코딩 벡터를 직접 예측
- distributed utterance order ranking : 무작위로 셔플된 대화의 일관된 대화 맥락으로 구성
Method
Approach

- 대화 : D
- 대화 맥락(history) : C (는 답변)
- :발화
- : i번째 발화의 j번째 토큰
- 목표 1 : 대화 맥락 C를 represent하는 방법을 학습
- 목표 2 : 대화 맥락 C가 주어질 때, 답변 를 생성하는 조건부 확률 학습
Hierarchical Transformer
- 1) Utterance Encoder f : 발화 인코더, C에 있는 각각의 발화를 벡터로 인코딩
- 2) Context Encoder g : 문맥 인코더, 문맥 속 주변 발화들에 대해 발화 representation을 학습
1) BERT에서와 같이 발화의 앞뒤에는 [cls]와 [sep] 토큰을 추가한다.
2) 임베딩 레이어가 각 발화에 있는 토큰을 연속적인 공간으로 매핑한다.(word embedding + positional embedding)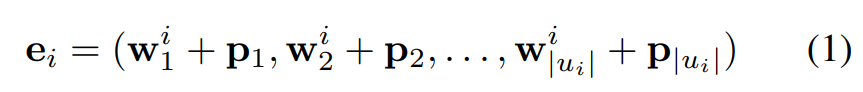
3) 발화 인코더는 임베딩을 input으로 받아 self-attention을 수행하고, 각 발화에 대한 첫번째 토큰([CLS])에 대한 벡터를 발화에 대한 representation으로 사용한다.
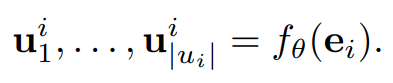
- 순서를 고려하기 위해 output representation에 positional embedding을 더한 final representation 를 구하게 된다.
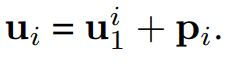
4) 문맥 인코더는 발화에 대한 representation을 input으로 받아 문맥을 고려한 hidden state를 반환한다.
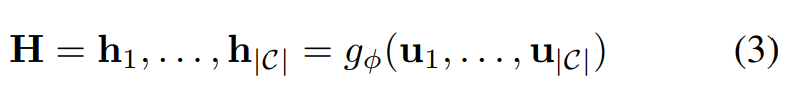
- 본 과정에서 나온 벡터는 계층적 transformer가 생성한 최종 대화 맥락 encoding 결과이다.
Training Objectives
담화 레벨에서의 일관성을 위해서 논문에서는 생성 loss에 더하여 두가지의 새로운 목적함수를 제안한다.
Next Utterance Generation (NUG)
- 응답 생성의 주요 목표이자 본 논문의 첫번째 훈련 목표는 대화 맥락이 주어진 후 다음 응답을 생성하는 것
- 계층적 transformer를 통해 맥락의 의미를 담은 발화인 H를 얻을 수 있다.
- NUG task에서는 디코더의 cross-entropy loss를 최소화 하는 것을 목적함수로 한다.
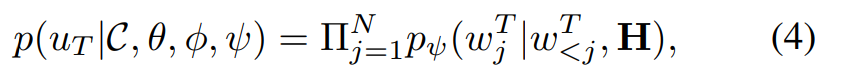
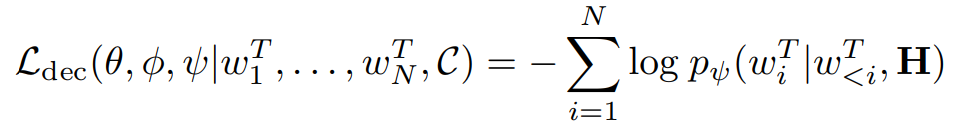
Masked Utterance Regression(MUR)
- BERT에서의 MLM 태스크와 유사하게 DialogBERT에서는 문맥 표현 학습을 향상하기 위한 보조 작업으로
MUR를 설계한다.
대화맥락 C 중에서 랜덤하게 하나의 발화를 선택한 후,
1) 80%의 확률 : Mask utterance로 대체
2) 10%의 확률 : 변화 x
3) 10%의 확률 : 학습 데이터 내의 랜덤한 발화로 대체
-
앞서 마스킹된 발화에 대한 벡터를 reconstruct하고, 마스킹된 문맥()이 주어질 때, 모델은 원래의 발화 벡터를 예측하게 된다.
-> 계층 encoder를 마스킹된 문맥에 적용하여 문맥의 의미를 담은 representation을 얻은 후, 원래 utterance vector에 매핑하는 FC layer를 연결한다.
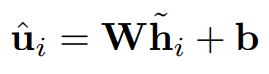
-> 예측한 hidden vector와 원래 C에서 얻어진 hidden layer의 MRS loss를 최소화하도록 학습한다.
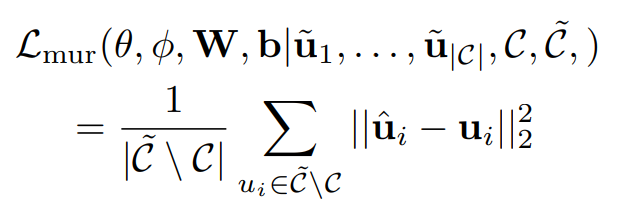
Distributed Utterance Order Ranking (DUOR)
- 일관성 있는 담화에서는 발화들이 관계성이나 logic에 따라 특정 순서를 갖기에, 문맥에서 발화의 순서는 대화의 의미를 결정한다.
- 본 논문은 무질서한 일련의 발화를
순서화하는 것이 대화 맥락의 표현을 하습하는데 중요한 영향을 미칠 것이라고 가정한다.
- 대화문에 n개의 발화가 있을 경우 => n!가지의 발화문의 가지수이기에 그대로 사용하면 결과가 좋지 않을 수 있다.
[DORN]
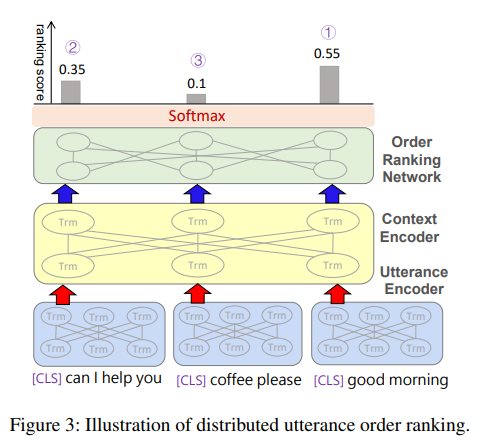
-
문맥 encoder위에
distributed order ranking network(DORN)을 붙이는 방식을 설계 -
DORN은 순서가 섞인 발화문을 입력받아 각 발화문에 대한 점수를 예측하고, 이러한 점수를 정렬하면 re-ordering된다.
-
self-attention 메커니즘에서와 같이, order prediction network는 hidden state간의 pairwise inner product를 계산하고, 각 발화문에 대한 점수는 다른 발화문과의 내적에 대한 평균으로 계산한다.
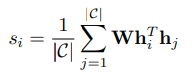
-
학습 과정에서는 learning-to-rank framework를 도입하여 예측된 점수를 어떤 context가 첫번째에 와야하는지에 대한 지표로 사용하여 rank-1 확률을 추정한다.
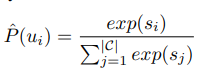
-
Ground Truth Order는 원래의 순서를 고려하여 다음과 같이 계산된다.
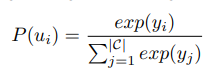
본 문제에서는 위에서 계산한 ground truth 와 예측된 분포간의 KL divergence를 최소화하는 것을 목적함수로 한다.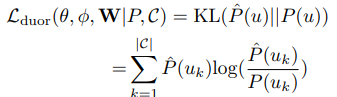
total loss
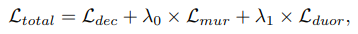
- 각 loss에 대한 가중합을 사용하여 전체 loss를 계산한다.
Experiments
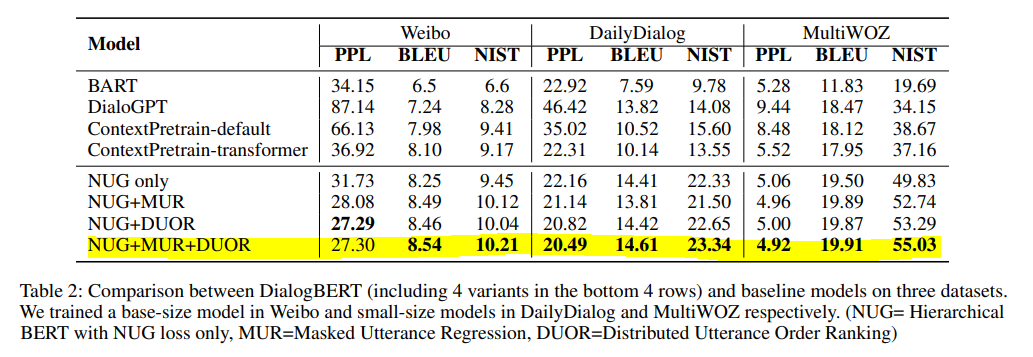
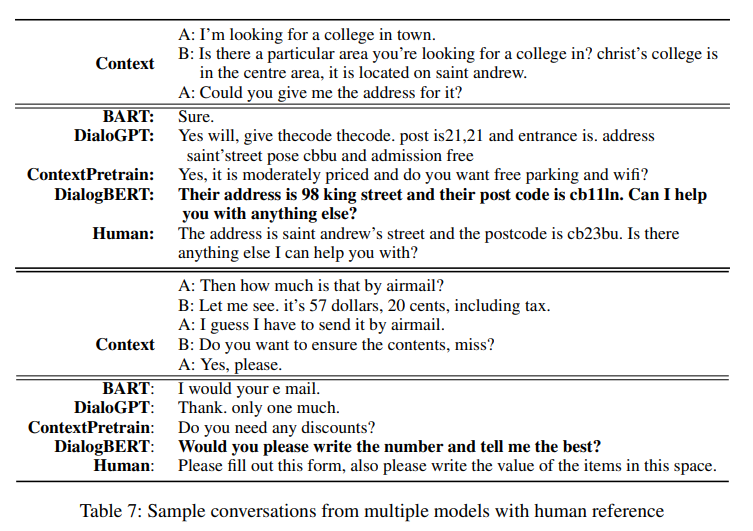
- 사람의 대답과 좀 더 근접한 결과를 볼 수 있다.
Conclusions
- 본 논문은 대화 context를 token의 선형 시퀀스로 인코딩 하는 방법 대신 계층적 transformer encoder architecture를 제안한다.
- 기존 BERT 훈련의 자연스러운 확장으로
MUR과DUOR의 훈련 목표를 통하여 기준모델보다 좋은 성능을 내는 것을 보여준다.
Reference
https://arxiv.org/pdf/2012.01775.pdf
https://littlefoxdiary.tistory.com/75

항상 좋은 글 감사합니다.