OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
Abstract
- 본 논문은 CNN을 사용한 분류, 위치 파악, 그리고 detection을 위한 통합 프레임워크를 제안한다.
- multiscale과 슬라이딩 윈도우 접근법이 ConvNet 내에서 효율적으로 구현될 수 있는 방법을 보여준다.
- 객체 경계를 예측하도록 학습하는 새로운 딥러닝 접근법을 소개한다.
Introduction
[ConvNet의 특징]
- 장점 : 많은 작업에 대해 전체 시스템이 raw 픽셀부터 최종 범주까지 end-to-end 방식대로 훈련 ⇒ 적합한 feature extractor를 수동으로 설계할 필요가 없음
- 단점 : 레이블이 지정된 훈련 샘플에 대한 굉장한 수요
[논문의 주요 포인트]
- 이미지에서 객체를 동시에 분류, 위치파악, 탐지 하기 위하여 합성곱 신경망을 훈련시키는 것이 모든 작업의 분류정확도, 탐지 및 위치파악 정확도를 향상시킬 수 있다는 것을 보여주는 것 ⇒ 즉, 통합적인 접근법 제안
- 예측된 바운딩박스를 축적함으로써 위치 파악과 탐지에 대한 새로운 방법을 소개
- 여러 localization prediction을 결합하며 배경 샘플에 대한 훈련 없이 탐지할수 있으며 시간이 많이 소요되고 복잡한 bootstraping 과정을 피할 수 있음
- 배경에 대한 훈련을 하지 않는 것은 네트워크가 오로지 positive class 에만 집중할 수 있도록 함.
[데이터셋]
- ImageNet ILSVRC 2012, 2013 데이터셋에서 실험 수행
- 대부분의 이미지를 거의 가운데에 가득 채우는 대상 객체가 포함되도록 선택됨
- 때로는 크기와 위치에서 다양한 객체가 존재
-
해결방법 1 : 여러위치에서 슬라이딩 윈도우 방식으로 ConvNet을 여러 스케일에서 적용
- 분류는 괜찮지만 위치파악과 탐지에서는 좋은 성능을 보이지 않음
-
해결방법 2 : 시스템을 훈련시켜 각 창에 대해 범주 분포뿐만 아니라 window와 관련된 객체를 포함하는 b-box의 위치와 크기를 예측하도록 하는 것
-
해결방법 3 : 각 위치와 크기에서 각 범주에 대한 증거를 축적하는 것
⇒ 본 논문은 기존의 sliding window 방식을 ConvNet에 적용하여 연산 효율성을 높힘
-
Classification
Model Design and Training
- 각 이미지는 가장 작은 차원이 256 픽셀이 되도록 다운샘플링 → 221x221 픽셀 크기의 5개의 임의의 크롭을 추출하고 이를 128 크기의 미니 배치로 네트워크에 제공
- 네트워크의 가중치는 (µ, σ) = (0, 1 × 10^−2)로 무작위로 초기화
- 확률적 경사하강법에 의해 가중치가 갱신되며, 0.6의 모멘텀항과 l2 가중치 규제
- 초기 학습률은 5 × 10^−2이며, (30, 50, 60, 70, 80) epoch 후에 0.5의 배율로 계속 감소
- 분류기의 완전 연결 계층은 Dropout을 0.5의 비율로 적용
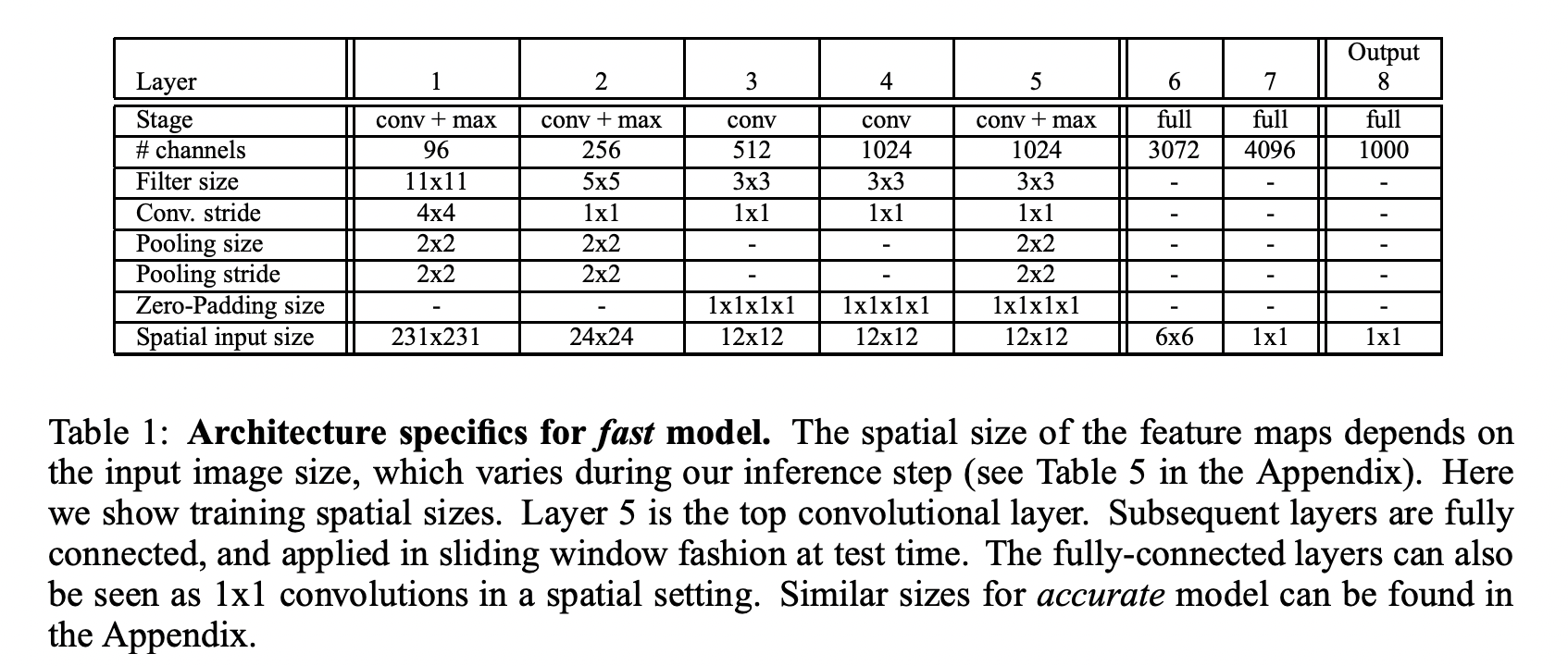
- Layer 1~5를 Feature Extractor 라고 칭하며, AlexNet의 overlapped pooling대신 non-overlapped pooling
Feature Extractor
“OverFeat”
- 빠른 모델과 정확한 모델, 두 모델이 제공
- 정확한 모델은 빠른 모델에 비해 두배의 connection이 필요
Multi-Scale Classification
-
multi scale을 입력받음으로써 이미지 내 존재하는 다양한 크기의 객체를 보다 쉽게 포착할 수 있다.
-
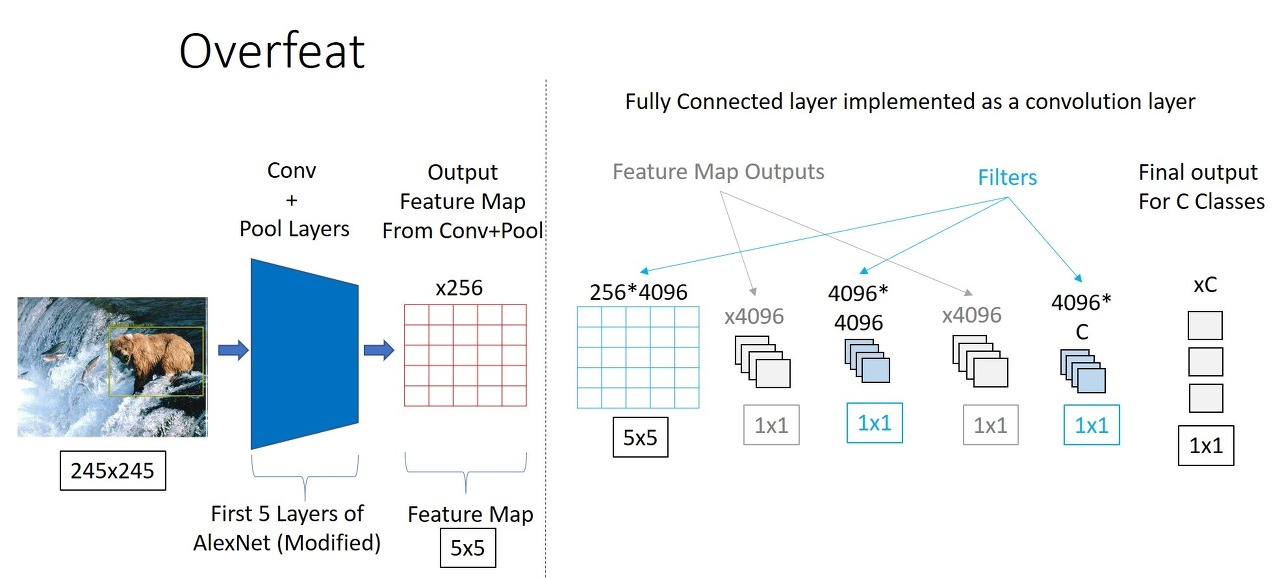
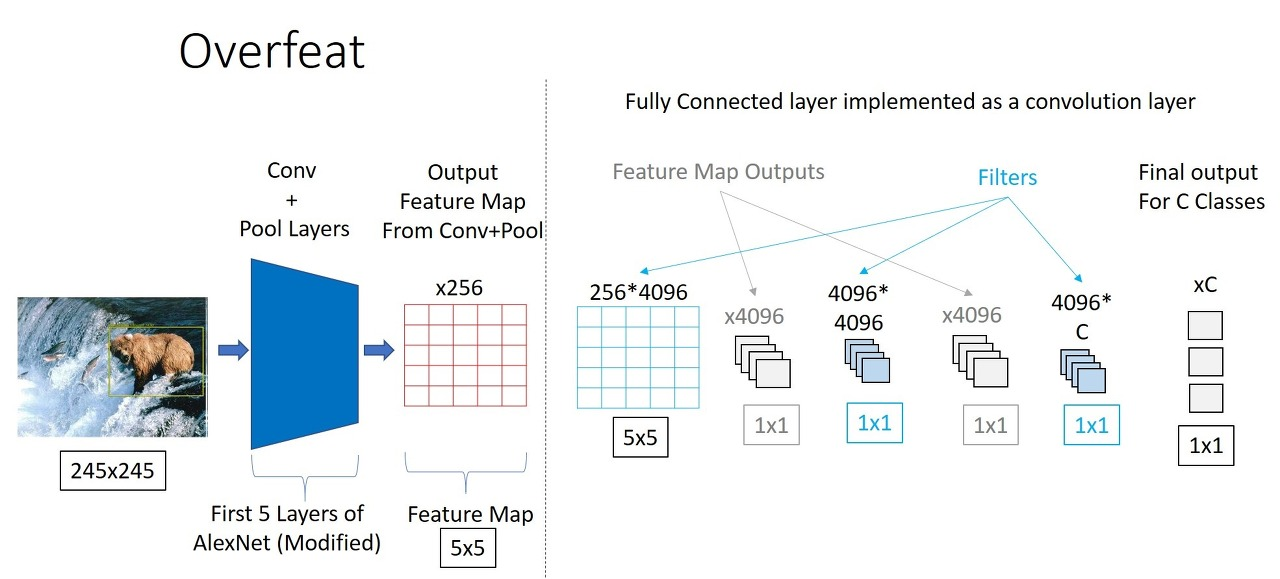
cnn이 고정된 크기의 이미지를 입력받는 이유는 fc layer가 고정된 크기의 feature vector를 입력받기 때문 → overfeat 모델에서는 이 점을 고려하여 fc layer를 conv layer로 대체한다.
-
저자는 Convolutional Network를 사용하게 되면 전체 이미지를 각 위치 및 다양한 스케일에서 dense하게 탐색할 수 있다고 언급 → 효율력이 좋아지면서 견고
-
만약, CNN에서 subsampling ratio가 높아지면 객체와 feature map 사이의 정렬이 안맞기에 성능이 떨어진다고 언급
→ “Fast image scaning with max-pooling convolutional neural networks”의 논문과 유사한 방법으로 접근하여 해결
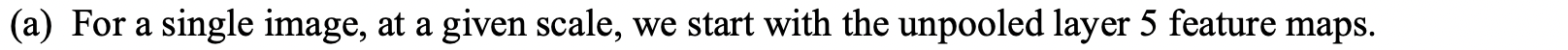
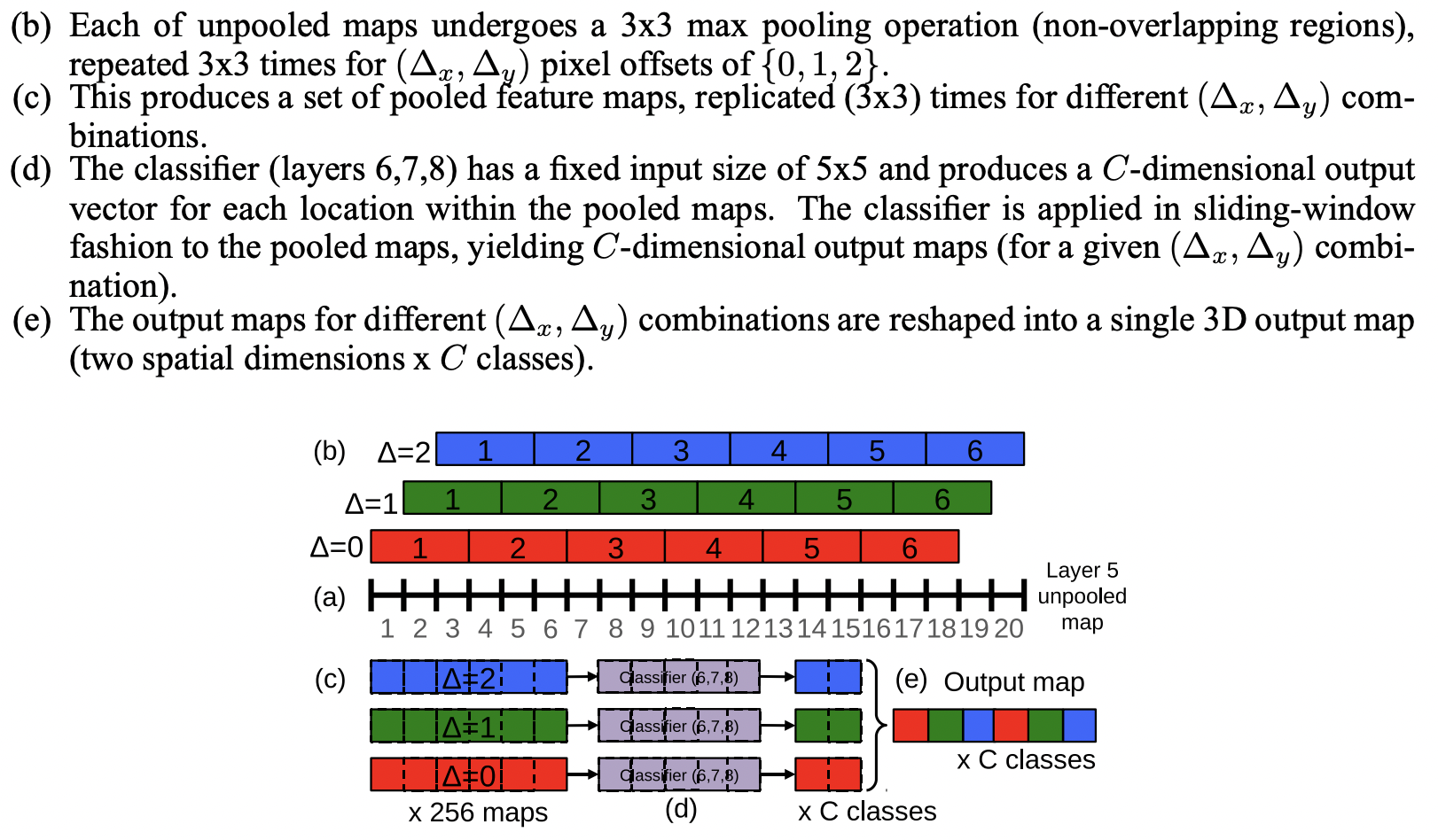
- pooling을 실시할 때 offset {0,1,2}의 조합으로 총 9개의 output map을 만든다.
Results
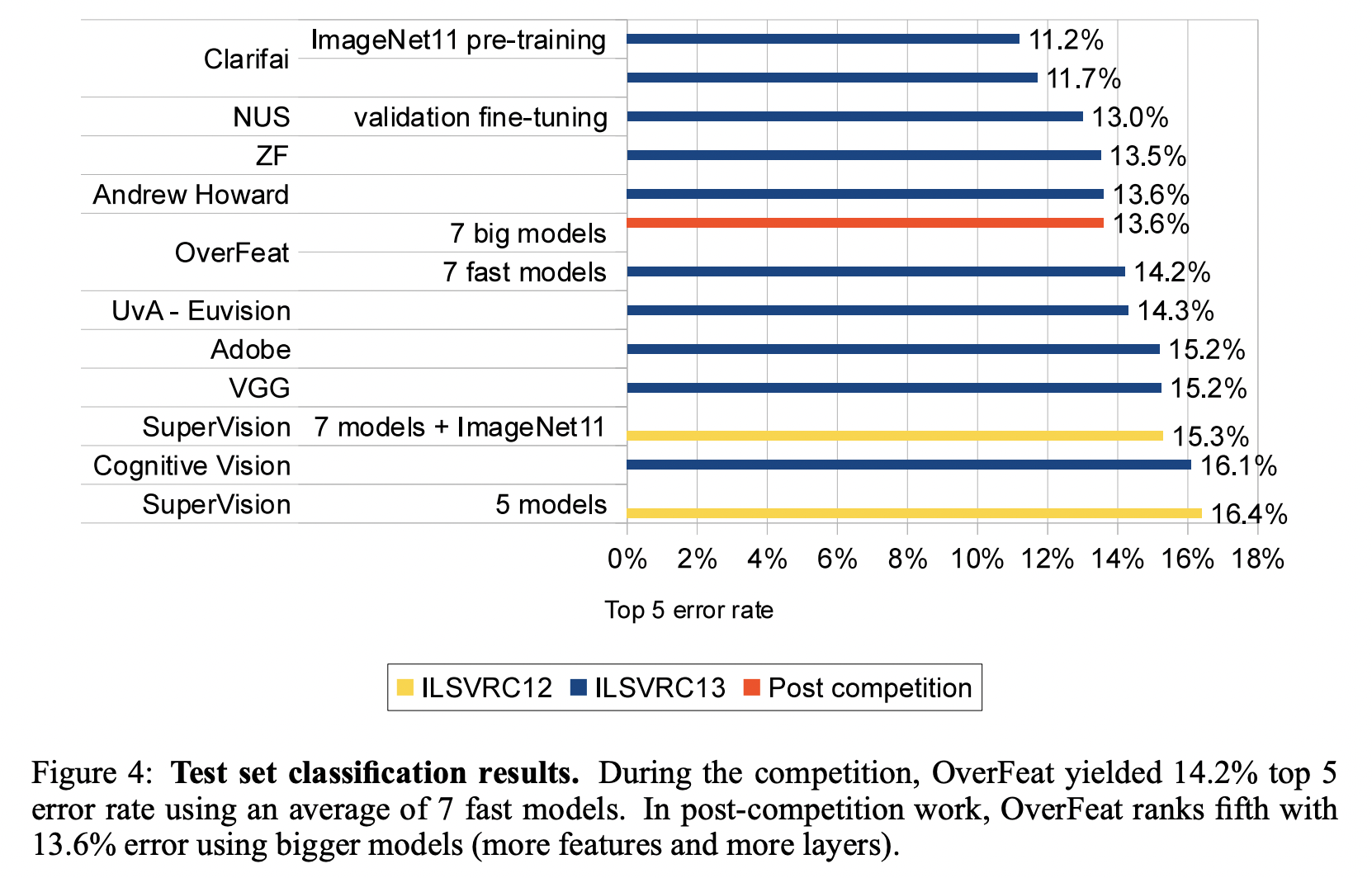
- 많은 scale을 사용한 접근방식이 단일 스케일 모델보다 상위 오류율을 가지는 것을 볼 수 있다.

- overfeat 모델이 7개의 convnet 모델이 보팅에 의해서 13.6%의 error를 달성
ConvNets and Sliding Window Efficiency
- 다른 슬라이딩 접근 방식과는 달리 본 논문의 ConvNet은 전체 파이프라인을 한번에 계산하는 것이 아닌, 겹치는 영역에서 공통적으로 사용되는 연산을 공유하기에 convnet에서 효율적이다.
- 각 레이어의 출력이 새로운 이미지의 크기를 커버하도록 확장되며, 최종적으로 각 윈도우마다 공간위치가 있는 출력 클래스 예측 맵을 생성

Localization
본 논문에서는 분류기 레이어를 회귀 레이어로 대체하고, 각 공간 위치와 스케일에서 b-box를 예측하도록 훈련
Generating Predictions
- 객체 b-box를 예측 생성하기 위해 분류기와 회귀 네트워크를 모든 위치와 스케일에 걸쳐 동시에 실행
- 동일한 특징 추출 레이어를 공유하기 때문에 분류 네트워크 후에는 최종 회귀 레이어만 계산
- 각 위치의 클래스 c에 대한 최종 softmax layer의 출력은 해당 field에 클래스 c의 객체가 존재할 확률에 대한 신뢰도 점수
Regressor Training
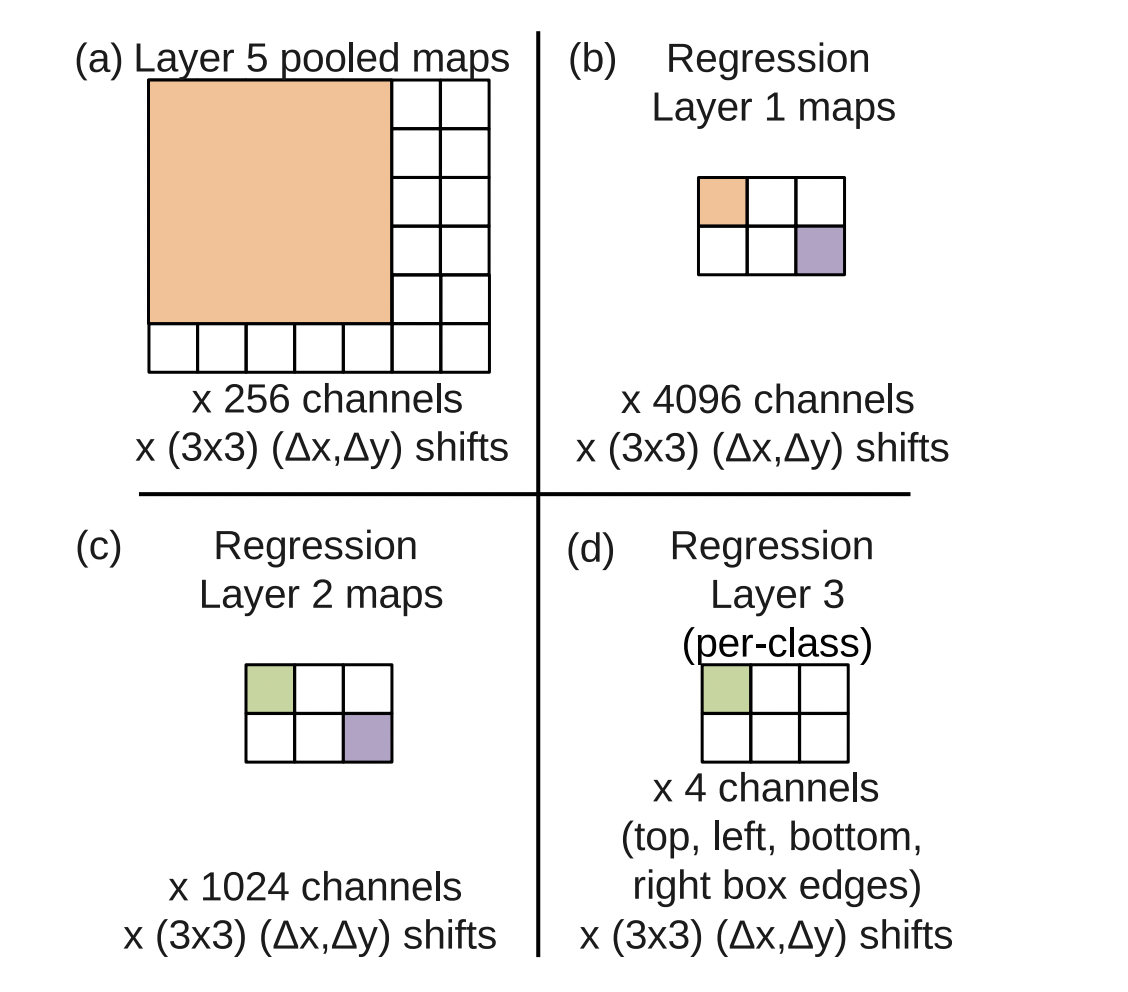
- 회귀 네트워크는 layer 5의 풀링된 feature map을 입력으로 사용
- 크기가 각각 4096과 1024인 fully connected hidden layer를 가짐
- 최종 출력 layer는 b-box의 가장자리 좌표를 지정하는 4개의 유닛을 가짐 ⇒ spatial output의 channel 수는 4*C
Combining Predictions (Greedy Merge Strategy)
- Overfeat는 객체 탐지시 각기 다른 6개의 scale에 대하여 굉장히 많은 예측된 b-box를 가짐.
- 논문의 저자가 정의한 offset조합에 의하여 예측 b-box수가 9배 더 증가
⇒ “ Greedy Merge Strategy”
1) 에 해당 scale의 spatial output에 대하여 각 pixel에서 가장 높은 confidence score를 가지는 class를 해당 location에 할당
2) 에 해당 scale의 spatial output에 bounding box 좌표를 할당
3) 에 모든 를 할당합니다.
4) 결과가 산출되기 전까지 아래의 병합 과정을 반복합니다.
-
에서 를 뽑아서 matchScore 적용 후 가장 작은 를 에 할당
-
만약 matchScore($b$1, $b$2 ) > t 이면 멈춤
-
그렇지 않으면 에 를 대신에 넣음
-
: 두 바운딩박스 중심좌표 사이의 거리의 합과 IoU를 사용하여 측정
-
: bounding box좌표의 평균 계산
-
위의 과정을 거쳐 병합된 바운딩 박스 중에서 confidence score가 높은 Box를 최종 예측으로 출력
