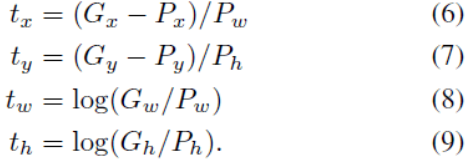R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)
1. Introduction
- 본 논문은 PASCAL VOC에서 CNN을 활용한 Object Detection 성능을 극적으로 향상시킨 최초의 논문
- 본 논문의 초점 2가지
- Deep Network을 활용한 객체 Localizing → 영역 제안에 cnn을 적용
- 매우 적은 양의 주석이 달린 detected data로 높은 수용량을 가지는 model training → pretraining + fine-tuning
[본 논문의 주요 목표]
네트워크 구조가 이미지에서 시계열 데이터를 인식하도록 특별히 설계된 새로운 신경망 모델 ⇒ Region proposals + CNN ⇒ R-CNN
[Deep Network를 활용한 Localizing Object]
Object detection은 이미지 내의 객체를 localizing 하는 것이 필요하다.
CNN localization 문제를 “recognition using regions”로 해결
- Region Proposal : 이미지 안에서 객체가 있을 만한 후보 영역을 먼저 찾아주는 방법 ⇒ 후보 영역을 바탕으로 객체 찾기 (ex. 선택적 탐색 … )
2. Object Detection with R-CNN
2.1 Module Design
[R-CNN 프로세스를 위한 세가지 모듈]
-
Region proposal
- Object 영역의 후보를 찾는 모듈 (기존 Sliding window 방식의 비효율성 극복)
- selective search 사용
-
Feature Extraction (CNN)
-
cnn의 입력 크기가 고정되어있지 않기 때문에 warp작업을 통해서 동일 input size를 만든다 ⇒ output 크기 고정

-
각각의 영역으로부터 고정된 크기의 Feature Vector 추출
-
2.2 Test-time Detection
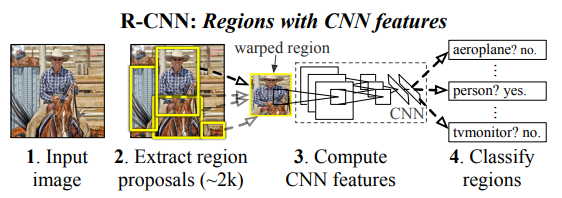
[R-CNN의 프로세스]
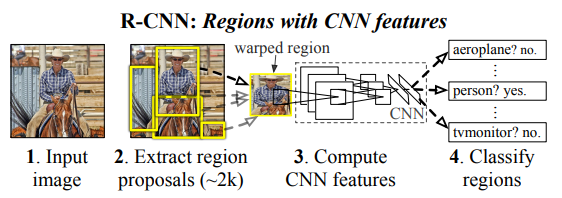
(1) 이미지를 입력받는다.
(2) input image에 대해 region proposals를 약 2000개 추출
(3) 추출한 regional proposals를 모두 동일한 사이즈로 만들어주기 위하여 warp
(4)warped image에 cnn을 적용하여 일정한 길이를 가진 feature vector를 추출
(3) 선형 SVM을 이용하여서 각 region을 카테고리별로 분류
2.3 Training
-
Supervised pre-training.
- large auxiliary dataset ILSVRC에 pre-trained CNN 이용
-
Domain-specific Fine-Tuning
- Domain-specific한 모델을 위하여 warped region proposals만을 이용하여 SGD를 사용해서 CNN 파라미터를 훈련(AlexNet)
- classification layer 개수 = N(Object Class 개수) + 1(Background)
- Mini-Batch = 128을 구성하기 위해 SGD iteration 마다, 모든 class의 positive sample 32개, 그리고 96개의 background(negative sample)를 사용한다.
-
Object category classifiers
- positive / negative를 나누는 threshold를 정해는 것은 매우 중요하다. threshold에 따라 mAP가 증가하기도 감소하기도 한다.
[Threshold 선정 방식]
- Positive Sample : 각 class별 object의 ground-truth bounding boxes
- Negative Sample : 각 class별 object의 ground-truth와 IoU가 0.3 미만인 region
2.4 Results on PASCAL VOC 2010-12
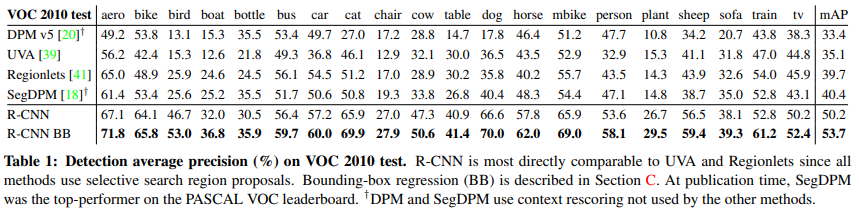
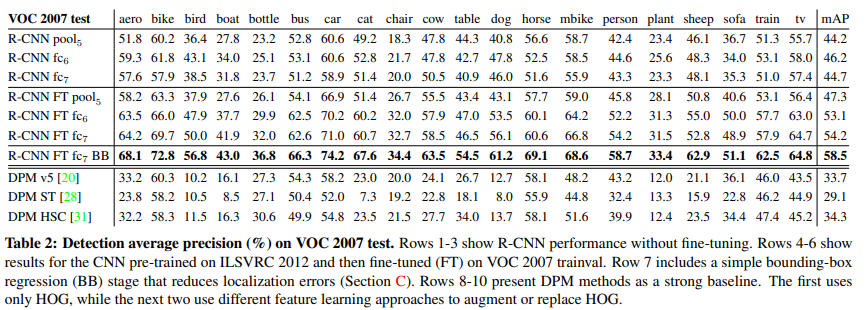
Table 1을 보면 R-CNN이 다른 방법들 보다 좋은 성능을 보이는 것을 확인할 수 있다. BB(Bounding Box regression)을 이용할 때, 성능이 더 올라감을 알 수 있다.
2.5 Results on ILSVRC2013 detection
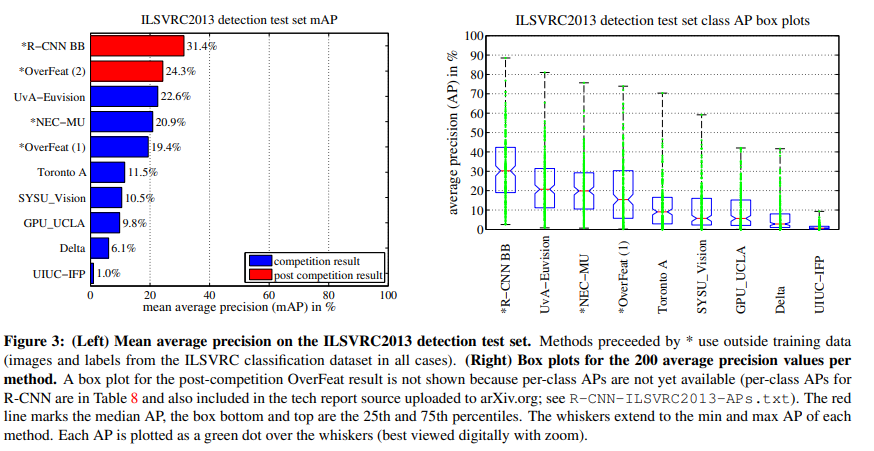
PASCAL VOC에서 보다 분류해야 할 class가 더 많아서 mAP는 낮지만 다른 방법론들에 비해 R-CNN이 성능이 우수함.
3. Visualization, ablation, and modes of error
3.1 Visualizing learned features

region proposals에 대한 unit activation 계산 → activation내림차순 정렬 → non-maximum suppression 수행 → 고득점 region 표시
- 각 layer마다의 unit들에 대해 어떻게 학습하는지 볼 수 있음
- 네트워크는 모양, 질감, 색, 물성의 분산 표현에 영향을 받음
3.2 Ablation studies
[Performance layer-by-layer, without fine-tuning]
1~3줄을 보면 fc7이 fc6보다 성능이 낮음 → mAP가 줄어들지 않더라도 CNN의 파라미터를 줄일 수 있음
[Performance layer-by-layer, with fine-tuning]
4~6줄을 보면 도메인별 학습을 한 후에 개선이 된다는 점을 볼 수 있음
3.3 Network architectures
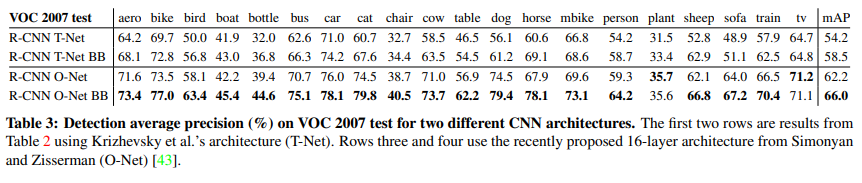
O-Net을 이용한 R-CNN이 T-Net을 이용한 R-CNN의 성능보다 좋음을 볼 수 있음
3.4 Detection error analysis
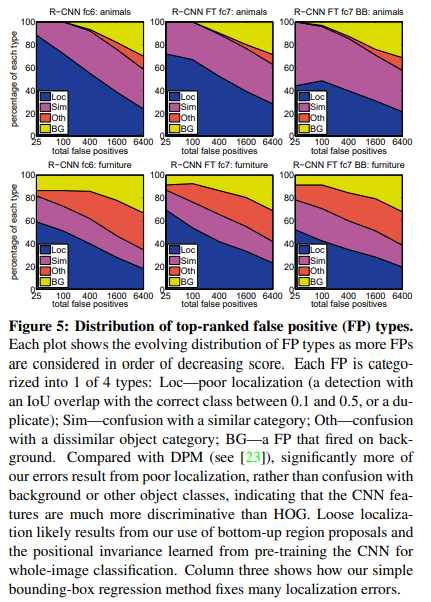
- background나 object classes에 대한 confusion보다는 Loc으로 나타나는 poor localization이 errors의 주요 원인임
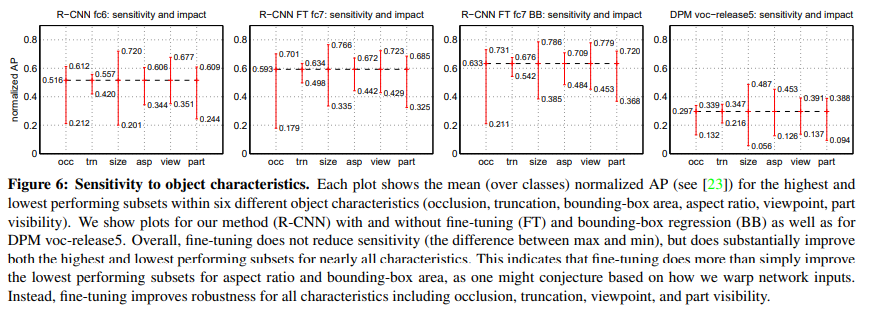
- object의 특징들인 occlusion (occ), truncation (trn), bounding-box area (size), aspect ratio (asp), viewpoint (view), part visibility (part)의 문제가 있을때의 성능
- 이전의 방법론인 DPM 보다는 R-CNN이 더 나은 것을 볼 수 있고, finetuning, bounding-box regression을 활용했을 때 더 좋은 성능을 보인다.
3.5 Bounding-box regression
- DPM에서 사용한 bounding box regression 방식을 도입
- Bounding-box regression : localization 오류를 줄이기 위한 간단한 방법
- 선택적 탐색으로 추출한 후보 영역 경계 박스를 실제 경계박스와 일치하도록 회귀 모델을 만들어 훈련
- Bounding-box : P
- Gounding-truth bounding box : G
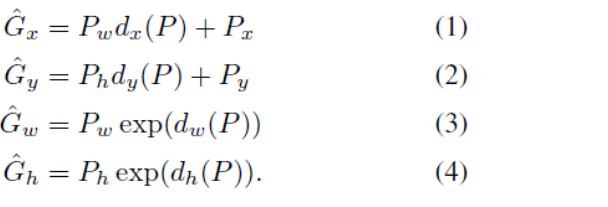
- w∗ 는 각 함수 d∗(P)에 대한 ridge regression를 통해 학습되어지는 가중치 계수
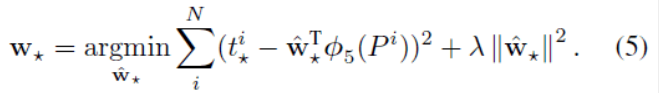
- t : regression target