이 포스트는 ⌜혼자 공부하는 머신러닝+딥러닝⌟ 도서를 참고하여 작성하였습니다.
1. k-최근접 이웃 회귀
지도학습 알고리즘은 분류(샘플을 몇 개의 클래스 중 하나로 분류)와 회귀(임의의 어떤 숫자를 예측: 내년도 경제 성장률 예측, 배달 도착 예정시간 예측)의 과정을 통해서 진행된다.
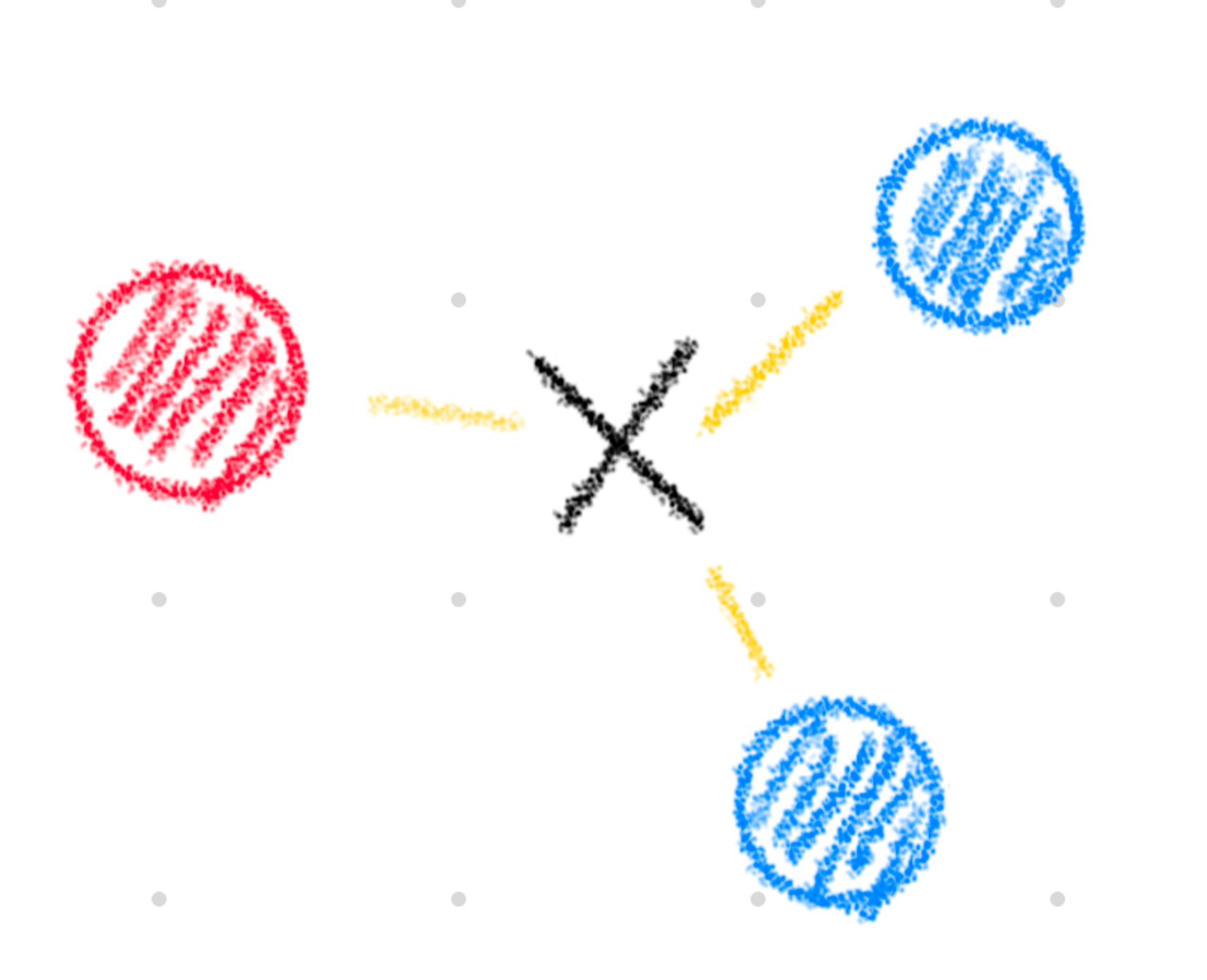
(1) k-최근접 이웃 분류 알고리즘
k-최근접 이웃 분류 알고리즘은 다음과 같은 절차를 통해 분석한다:
1. 예측하려는 샘플에 가장 가까운 샘플 k개를 선택한다.
2. 이 샘플들의 클래스를 확인하여 다수 클래스를 새로운 샘플의 클래스로 예측한다.
(2) k-최근접 이웃 회귀 알고리즘
k-최근접 이웃 회귀 알고리즘은 다음과 같은 절차를 통해 분석한다:
1. 예측하려는 샘플에 가장 가까운 샘플 k개를 선택한다.
2. 이 샘플들의 클래스를 확인하여 그 평균을 새로운 샘플의 클래스로 예측한다.
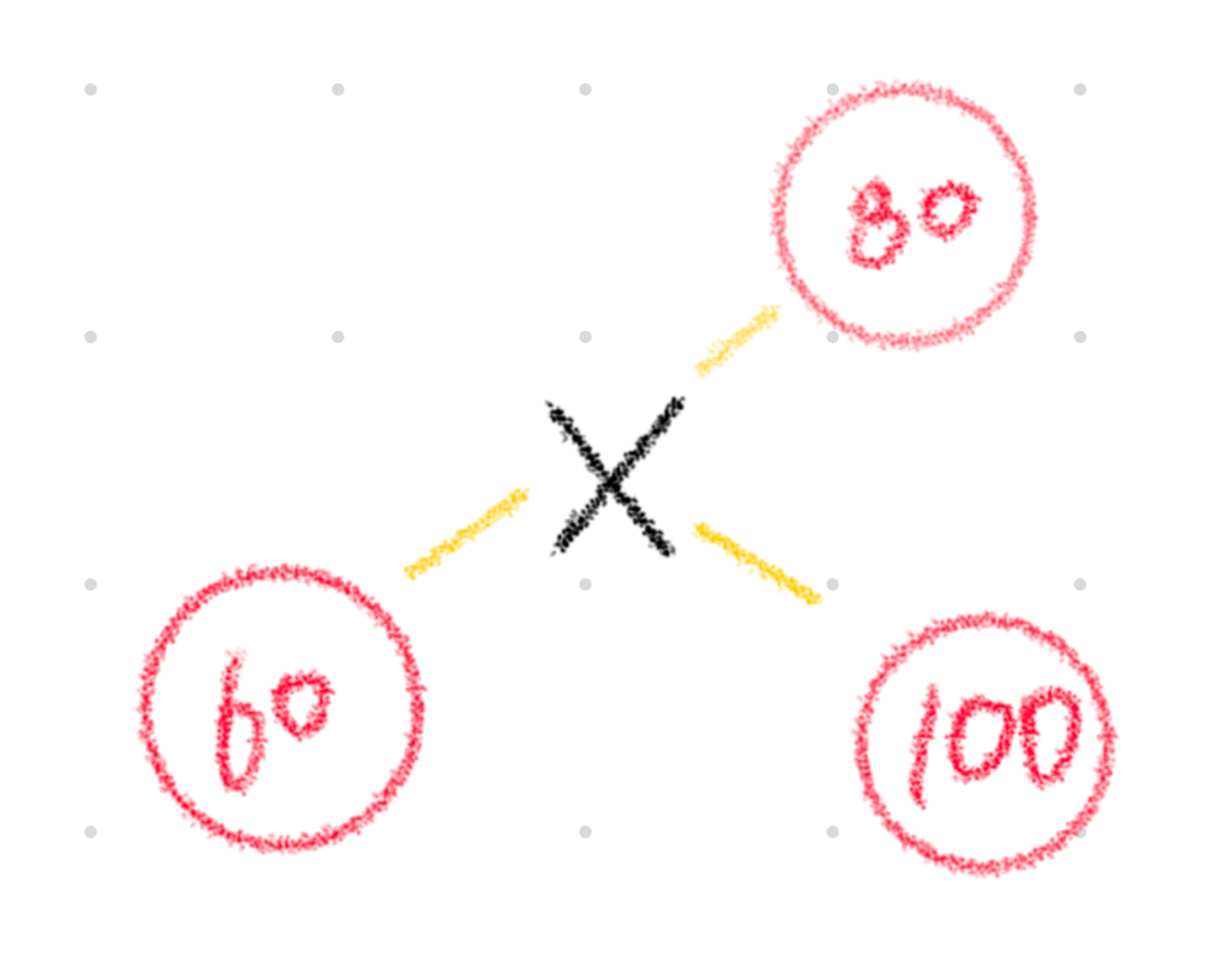
이 경우 X는 60, 80, 100의 평균인 80을 본인의 클래스로 갖는다.
(3) 그 밖의 알아둬야할 개념들
결정계수()
과대적합 vs 과소적합
- 과대적합 : 훈련 세트의 점수가 높고, 테스트 세트의 점수가 낮다. 이로 인해 훈련 세트에 최적화되어 새로운 샘플에 대한 예측 시 점수가 낮다는 특징이 있다.
- 과소적합 : 훈련 세트의 점수가 낮고, 테스트 세트의 점수가 높다.
2. 선형 회귀
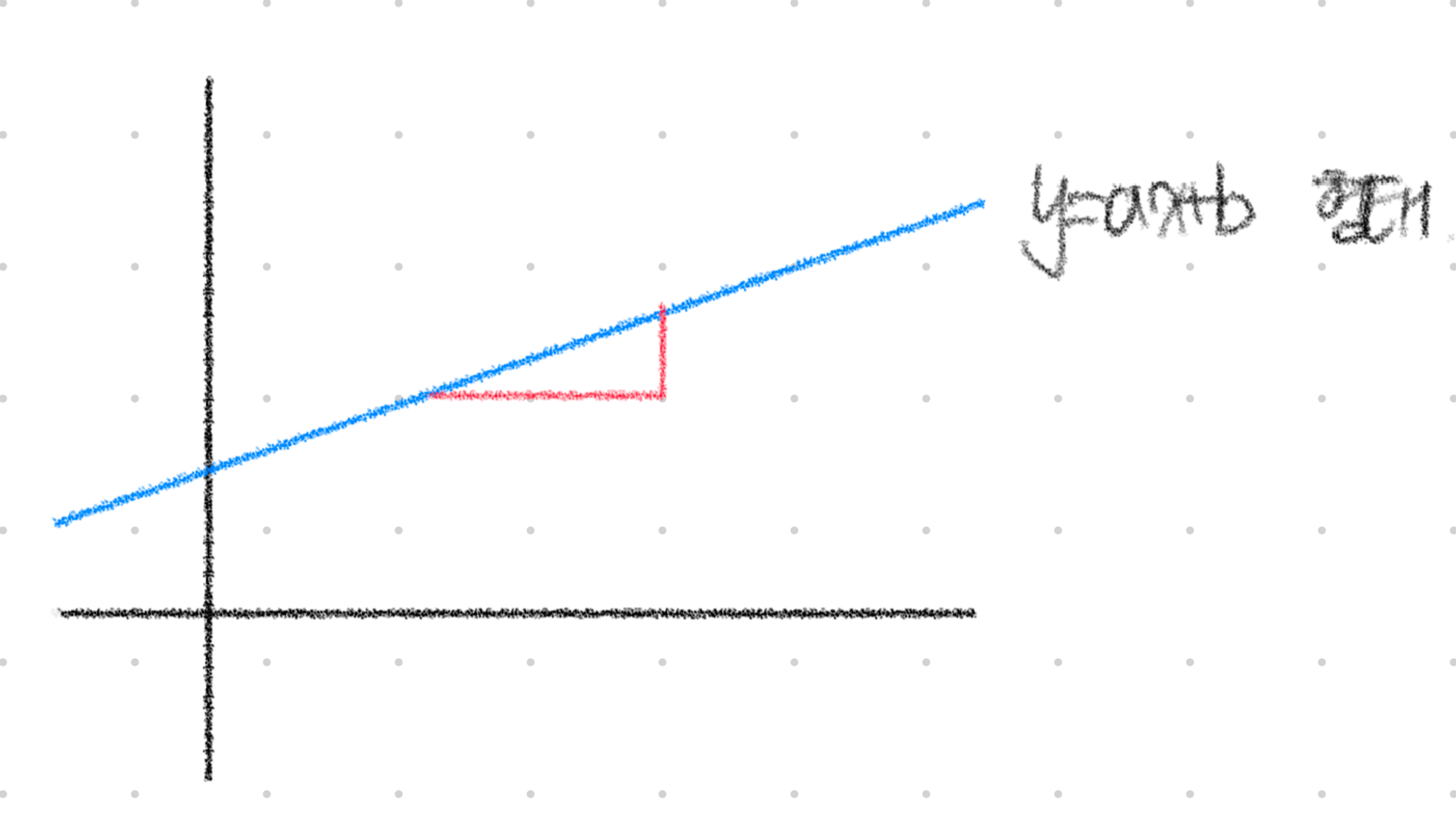
(1) 선형 회귀
선형 회귀는 널리 사용되는 대표적인 회귀 알고리즘으로 직선을 학습한다는 특징을 가지고 있다.
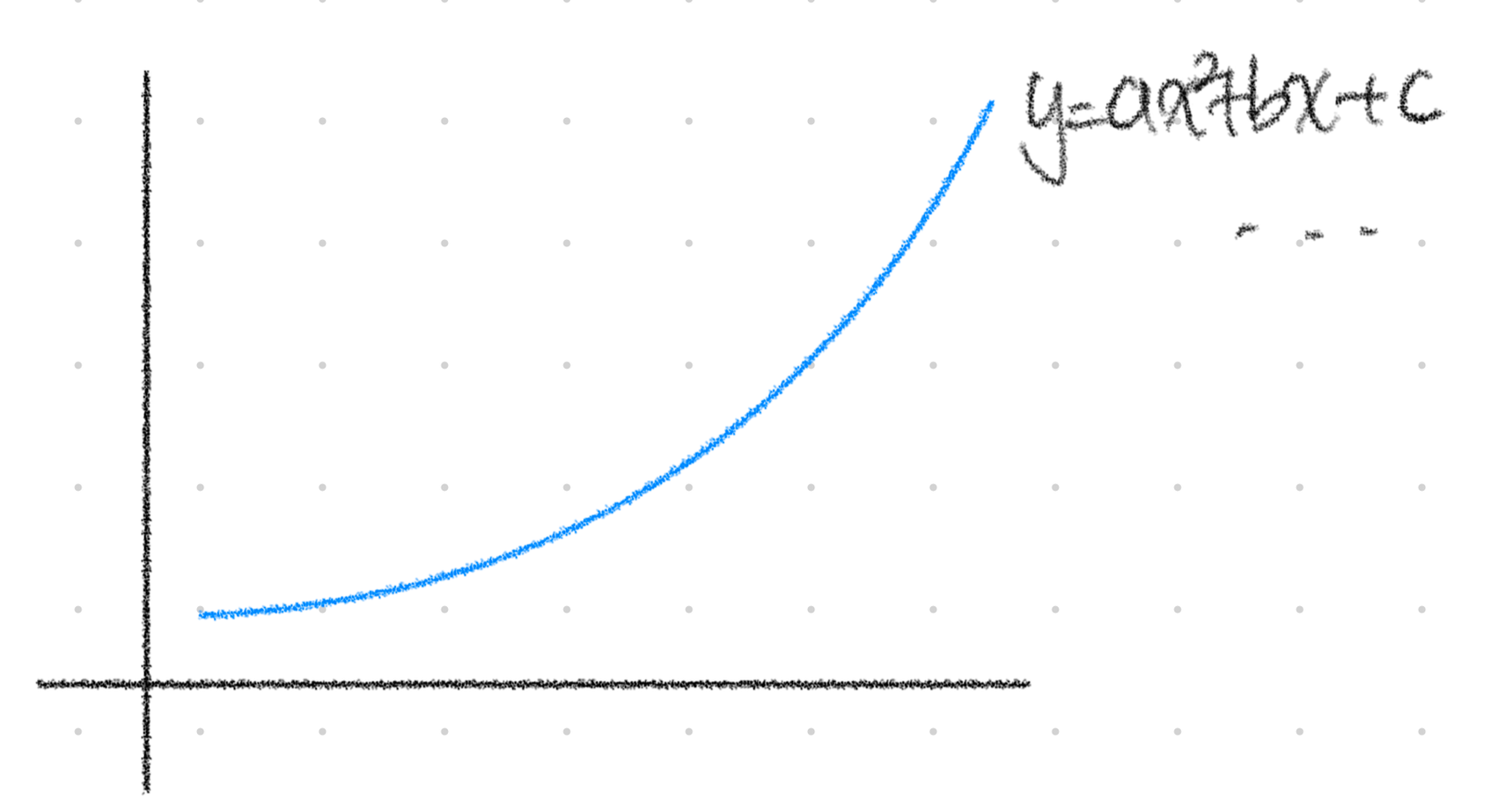
(2) 다항 회귀
다항 회귀는 선형 회귀와 다르게 곡선을 학습한다는 특징을 가지고 있다.
3. 특성 공학과 규제
(1) 다중 회귀와 특성 공학
다중 회귀는 여러 개의 특성을 사용한 선형 회귀를 말한다. 이때, 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업이 필요한데, 이를 특성 공학이라고 한다.
(2) 규제
규제란, 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것을 말한다. 과대적합(overfitting)을 예방할 수 있다.

새내기의 코딩일지