유튜브 댓글을 수집하는 방법은 크게 두 가지입니다. 첫번째는 Google에서 제공하는 유튜브 API를 사용하는 것이고, 두번째는 직접 HTML 문서에서 크롤링하는 방법이 있습니다.
이번에는 유튜브 API를 사용해서 유튜브 댓글을 크롤링할 것인데, 주의해야 할 점이 있습니다.
유튜브 API는 할당량이 정해져있기에 개인적인 용도로 사용하기에는 거의 문제가 없으나 서비스를 제공한다던가 큰 프로젝트르 진행하는 경우에는 유료로 유튜브 API를 사용해야 합니다.
1. 유튜브 API 생성하기
우선 Google 계정에 로그인한 후에 Google API Console에 접속하여 유튜브 API 키를 발급 받아야 합니다.
 좌측에 라이브러리에서 Youtube를 검색한 뒤 Youtube Data API v3 를 사용해주면 됩니다. 다음으로 좌측에 "사용자 인증 정보"에서 "사용자 인증 정보 만들기"를 클릭한 뒤 API 키를 발급받으면 됩니다. 앞으로 발급받은 키를 사용해야 하므로 이후에 복사해서 붙여넣으시면 됩니다.
좌측에 라이브러리에서 Youtube를 검색한 뒤 Youtube Data API v3 를 사용해주면 됩니다. 다음으로 좌측에 "사용자 인증 정보"에서 "사용자 인증 정보 만들기"를 클릭한 뒤 API 키를 발급받으면 됩니다. 앞으로 발급받은 키를 사용해야 하므로 이후에 복사해서 붙여넣으시면 됩니다.
2. 유튜브 API 라이브러리 불러오기
pip install google-api-python-client우선 Google API를 사용하기 위해 Google-api-python-client 라이브러리를 다운받습니다.
import pandas
from googleapiclient.discovery import build
import warnings # 경고창 무시
warnings.filterwarnings('ignore')3. 유튜브 API 사용하기
comments = list()
api_obj = build('youtube', 'v3', developerKey='API키')
response = api_obj.commentThreads().list(part='snippet,replies', videoId='video id', maxResults=100).execute()수집한 댓글을 저장할 빈 리스트를 하나 만들어줍니다. build를 통해 Google API 객체를 생성하고 아까 발급 받았던 유튜브 API 키를 입력해줍니다. 다음으로 세 번째 줄에서 vedio_id를 입력해주어야하는데 이건 유튜브 주소가 아닙니다. vedio_id를 찾는 방법은 다음과 같습니다.
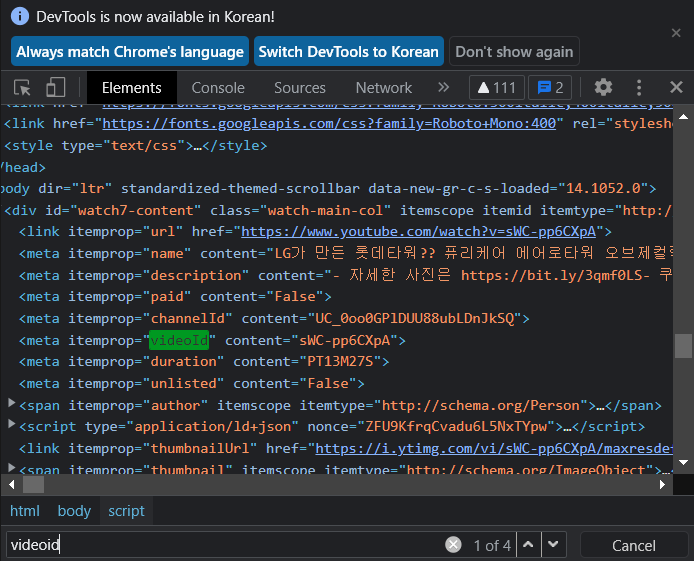 유튜브에서 F12를 누른 뒤 Ctrl+F(찾기) 기능으로 videoid를 입력해줍니다. 그러면 위와 같은 코드가 나올 것인데, videoId 옆에 "sWC-pp6CXpA"(유튜브 주소 마다 다릅니다!)가 우리가 찾는 videoId입니다. 따라서 저 값을 위 코드에서 videoId 란에 입력해주면 됩니다.
유튜브에서 F12를 누른 뒤 Ctrl+F(찾기) 기능으로 videoid를 입력해줍니다. 그러면 위와 같은 코드가 나올 것인데, videoId 옆에 "sWC-pp6CXpA"(유튜브 주소 마다 다릅니다!)가 우리가 찾는 videoId입니다. 따라서 저 값을 위 코드에서 videoId 란에 입력해주면 됩니다.
4. 댓글 수집하기
while response:
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']
comments.append([comment['textDisplay'], comment['authorDisplayName'], comment['publishedAt'], comment['likeCount']])
if item['snippet']['totalReplyCount'] > 0:
for reply_item in item['replies']['comments']:
reply = reply_item['snippet']
comments.append([reply['textDisplay'], reply['authorDisplayName'], reply['publishedAt'], reply['likeCount']])
if 'nextPageToken' in response:
response = api_obj.commentThreads().list(part='snippet,replies', videoId='sWC-pp6CXpA', pageToken=response['nextPageToken'], maxResults=100).execute()
else:
break
- textDisplay: 댓글의 내용
- authorDisplayName: 댓글 작성자
- publishedAt: 댓글 작성 시간
- likeCount: 좋아요 수
-> 유튜브 API 문서에서 확인할 수 있는 변수명입니다.
5. 댓글 저장하기
df = pandas.DataFrame(comments)
df.to_excel('results.xlsx', header=['comment', 'author', 'date', 'num_likes'], index=None)마지막으로 수집된 댓글들을 엑셀 파일에 저장합니다.
