이번 포스팅에서는 Few-Shot Learning에 대한 기본적인 개념과 baseline model 구조가 어떻게 되어있는지를 공부한 내용을 정리해보려 한다. Few-Shot Learning(Shusen Wang) 유튜브 강의를 바탕으로 글을 작성하였다.
Basic Concepts
Few-Shot Learning이란?
Few-Shot learning은 적은 수의 데이터셋만 가지고도 모델을 "잘" 학습시키기 위한 학습 방법으로, 학습의 초점이 유사점과 차이점을 찾는 것에 맞춰져 있다.
Why Few-Shot Learning?
딥러닝 모델을 학습시키기 위해서는 어마어마한 양의 데이터가 필요하다. 그러나 모든 task에 대해서 이 방대한 양의 데이터를 구축하는 것은 사실상 불가능하다. 예를 들어, 열심히 1000가지 클래스의 이미지 데이터셋을 구축해 두었더니 그 1000가지 밖의 클래스에 대한 분류가 필요한 상황이라면? 그런데 하필 이 클래스의 이미지를 모으기가 너무나 어려운 상황이라면? 이럴 때 Few-Shot Learning은 큰 도움이 될 수 있다.
특히나 Novel View Synthesis 테스크의 경우, 모델은 학습한 view에 없는 다른 새로운 view에서 이미지를 생성해 내야 한다. 이러한 경우에 Few-shot learning은 매우 유용하다.
Supervised Learning vs. Few-Shot Learning
Learn to Learn
"Learn to learn"은 Few-Shot Learning을 포함한 Meta Learning의 목적이다. 즉, 모델은 학습단계에서 생소한 Query를 을 때 "잘 학습할 수 있는" 준비를 하게 된다. 이를 위해서 Few-Shot Learning에서는 Supervised Learning과 다른 방식으로 데이터셋이 구분된다:
Supervised Learning

- 구조: Training Set - Test Set
- Test Set은 Training Set에 없는 데이터여야 하지만, 이미 알고있는 class에 속해야 함.
Few-Shot Learning
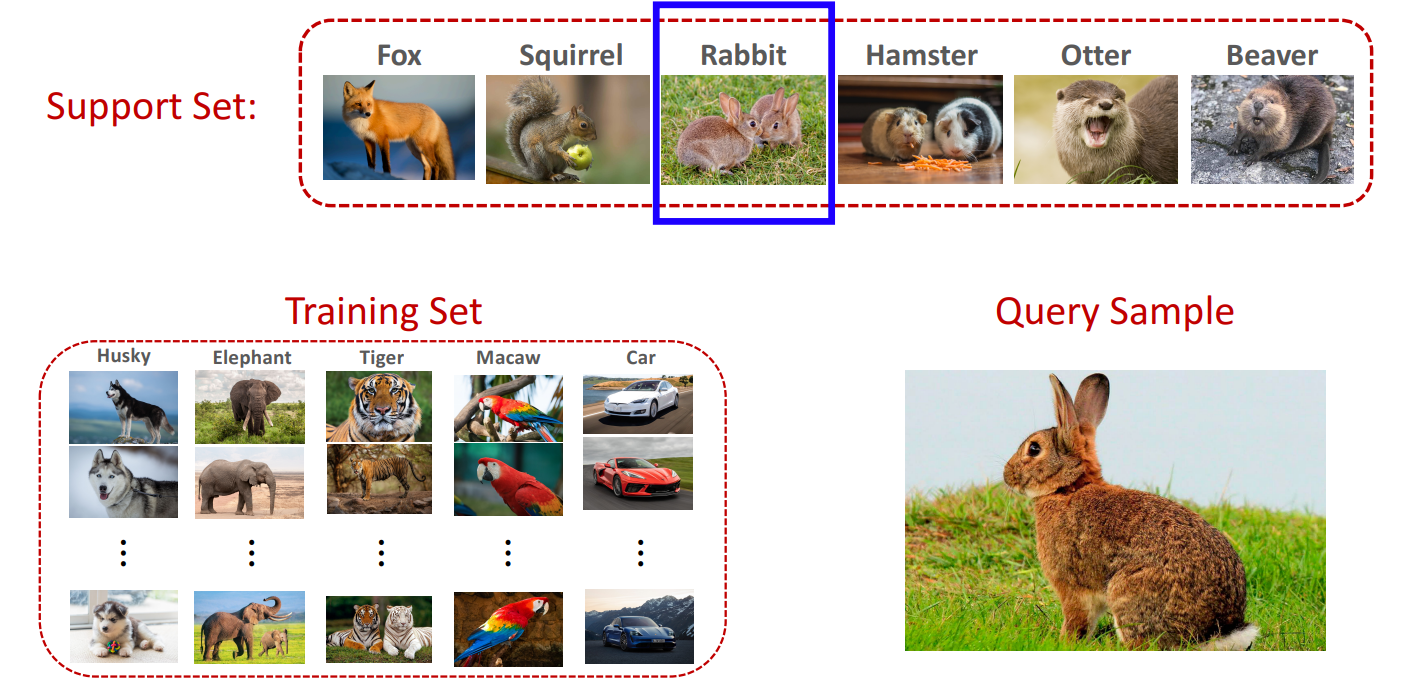
- 구조: Training Set - Support Set - Query Sample
- Query Sample은 Training Set에 없는 데이터여야 하고, 동시에 한 번도 본 적 없는 class에 속해야 함.
k-Way n-Shot
Few-Shot Learning은 Support Set의 크기에 따라
- -way: Support Set의 class 수
- -shot: 각 class에 속한 sample 수
로 구분된다.
예를 들면,
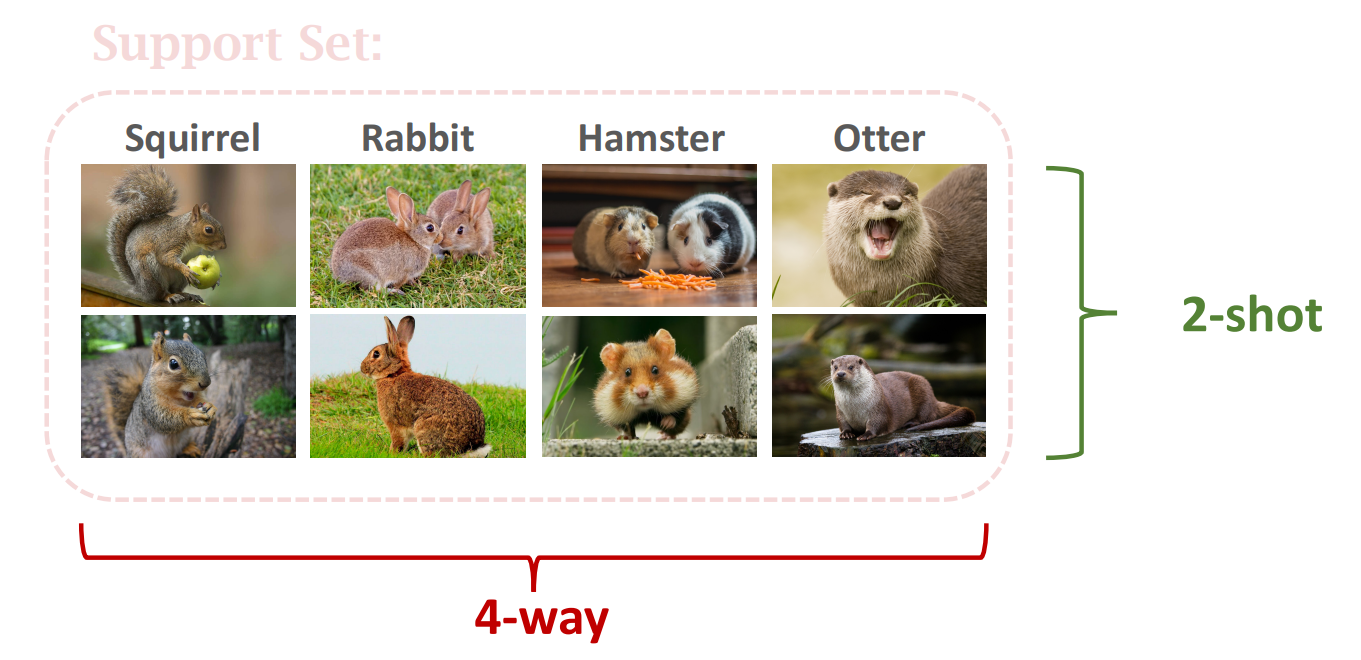
이러한 Support Set 구조를 가진다면 이는 4-way 2-shot learning이다.
Prediction Accuracy
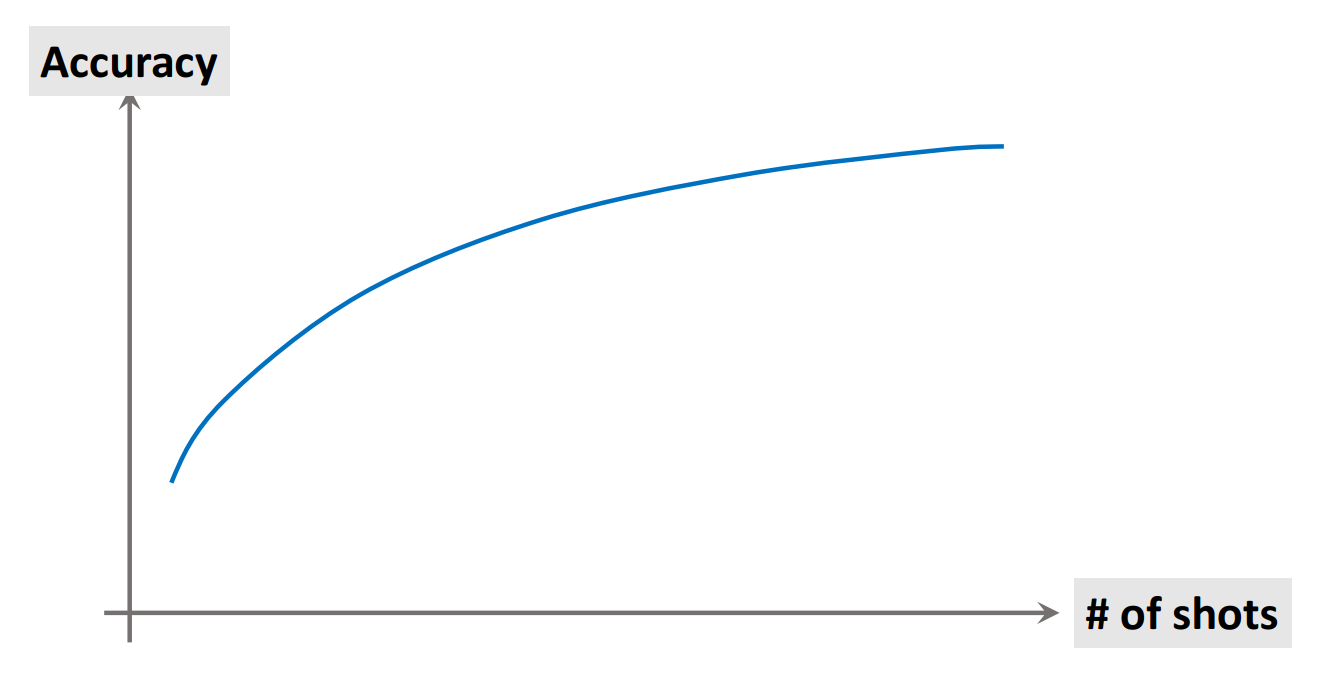 | 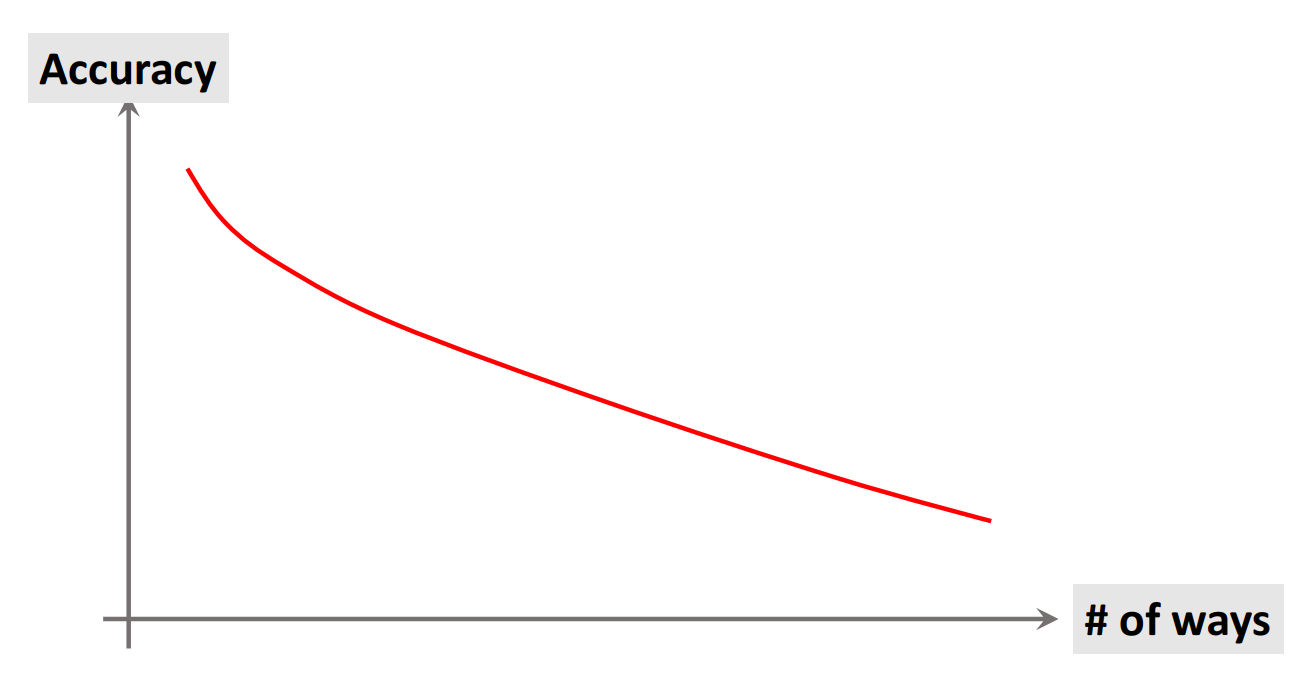 |
|---|
예측 정확도는 Shot이 많을수록, Way가 적을수록 높아진다.
Few-Shot Learning 학습 방법
학습 과정은 크게 세 단계로 나뉜다.

1. 큰 Training Set으로 모델을 학습시킨다.
-
이 때 이미지 간의 유사점과 차이점이 학습된다.
-
Training Set은 Query의 class를 포함하지 않아도 된다.
-
Similarity function을 통해 범위의 similarity score 값을 계산하고 학습한다.

2. Query 이미지를 받으면 Support Set의 각 샘플과 Query를 비교한다.

3. 이 과정을 통해 Query가 속하는 class를 결정한다.
- 가장 similarity score이 높은 class를 찾는다.
Siamese Network
Pairwise Similarity Scores

-
Positive Samples: 랜덤하게 학습데이터에서 하나의 클래스의 이미지를 샘플하고, 같은 클래스의 다른 이미지를 묶어 만든다.
-
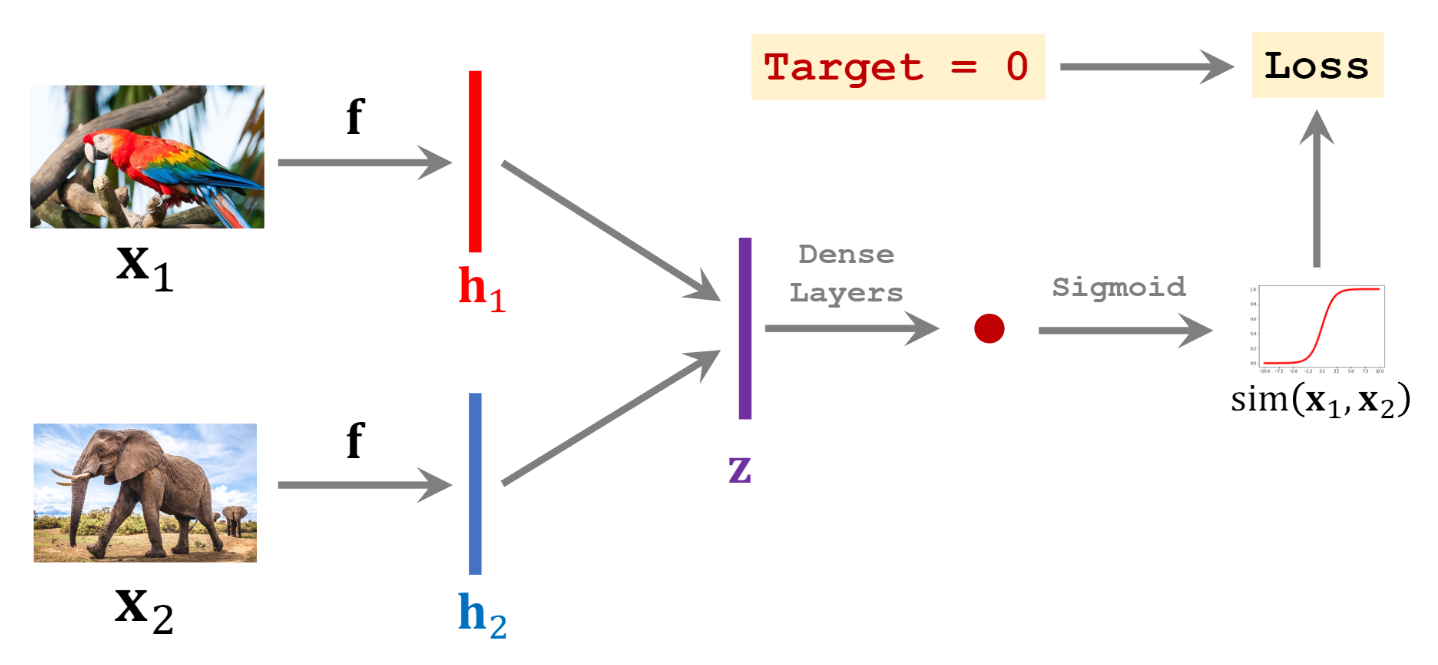
Negative Samples: 마찬가지로 랜덤하게 학습데이터에서 하나의 클래스의 이미지를 샘플하고, 그 클래스를 제외한 클래스의 다른 이미지를 묶어 만든다.
Training
CNN for Feature Extraction
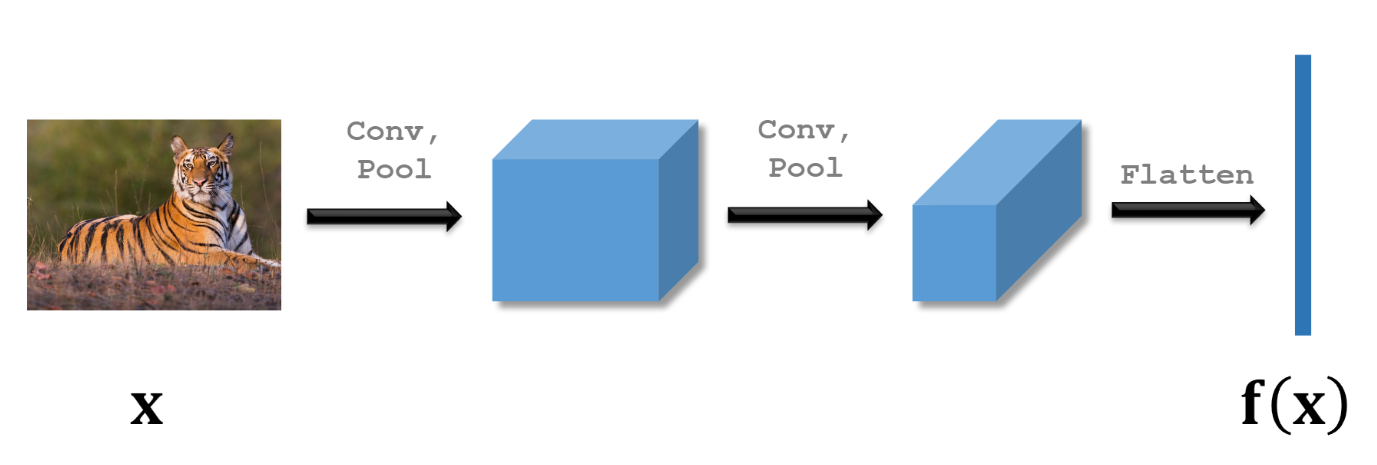
Forward Propagation
 |  |
|---|
-
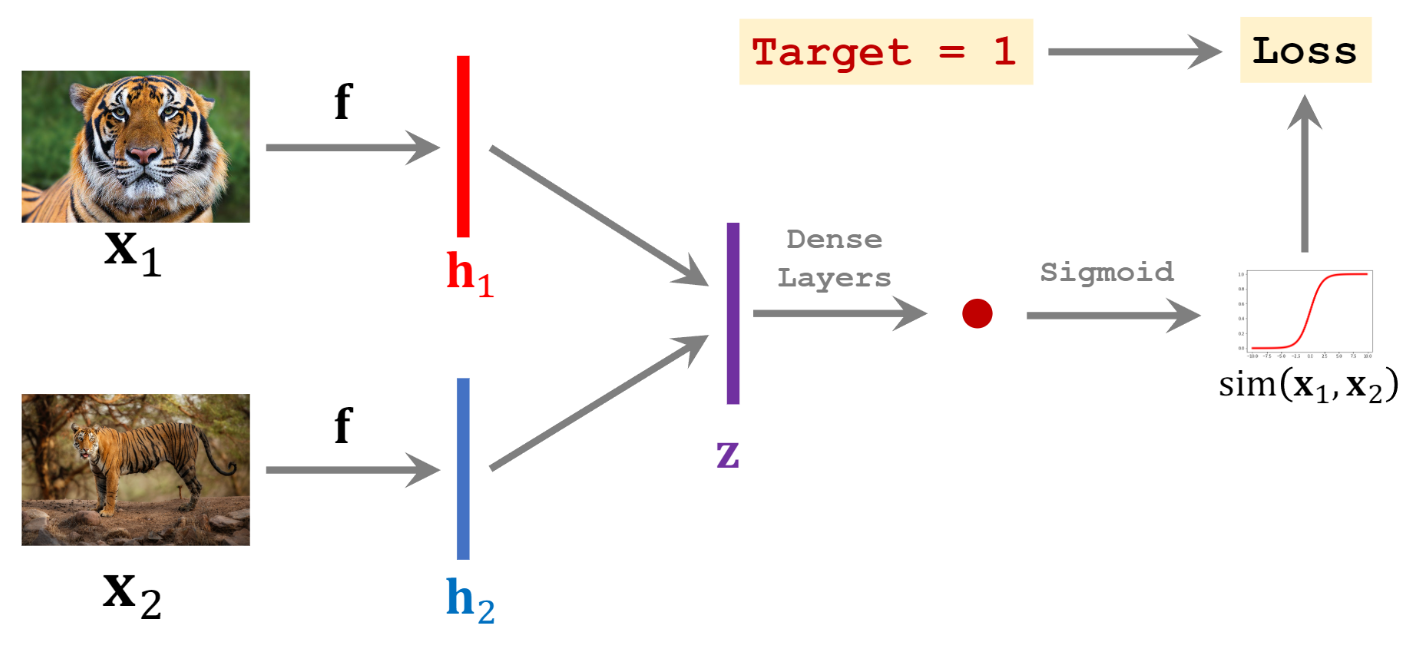
Positive Samples에서는 두 이미지의 Target = 0 이다. 이 때 는 CNN이며, , 가 하나의 CNN 를 공유한다.
-
feature vector을 , 로 뽑아낸 후, 둘의 차이를 계산하여 를 구한다.
-
를 Dense Layers에 통과시키며 하나의 scalar 값을 도출한다.
-
Sigmoid 활성화 함수를 통과시켜 사이의 similarity score을 구한다.
-
Target값과 비교하여 Loss를 구하여 업데이트시킨다.
-
같은 수의 Positive & Negative Sample 쌍을 학습시킨다.
Back Propagation
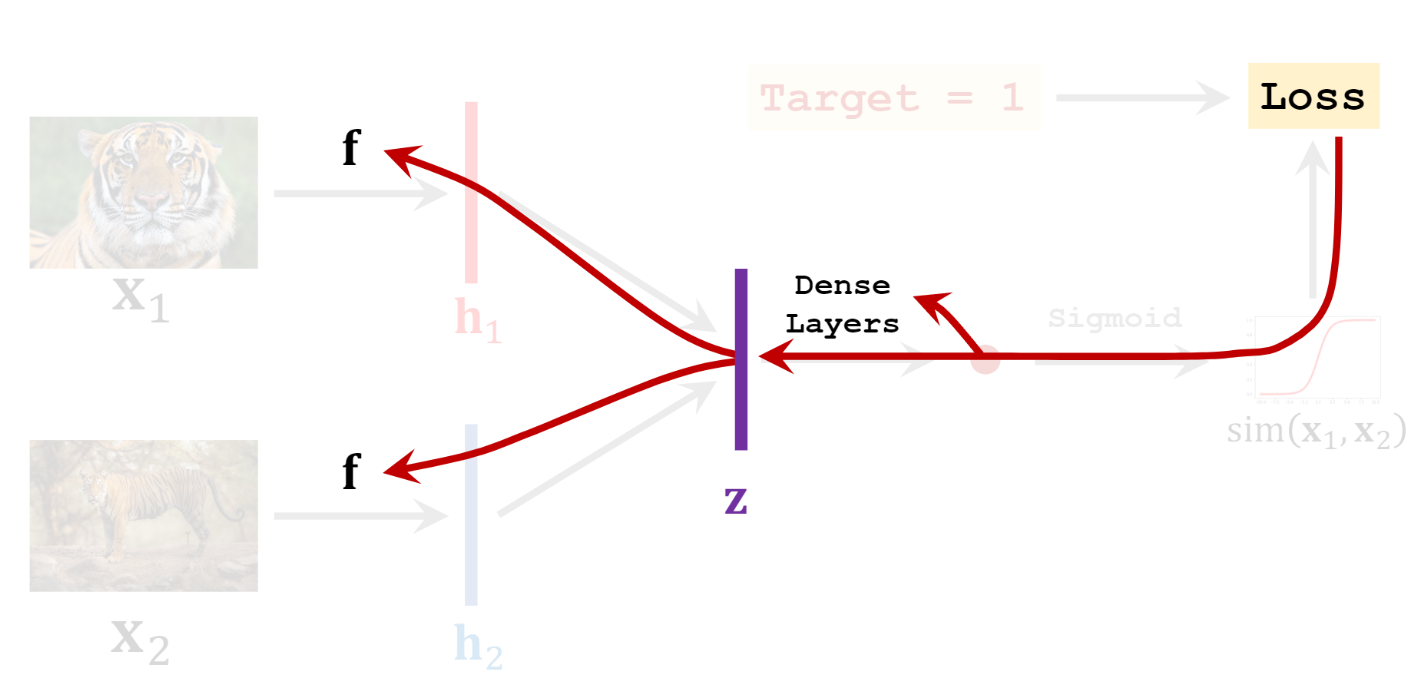
Backpropagation이 진행될 때에는 두 가지 값이 모두 업데이트 된다:
- CNN 의 파라미터
- 가 통과하는 Dense Layers의 파라미터
One-Shot Prediction
학습된 모델을 바탕으로 Support Set과 Query를 활용하여 similarity score을 계산하여 검증한다.
Loss Function
그렇다면 Siamese Network에서 Objective Function은 어떻게 정의해야 할까? 앞서 살펴본 Siamese Network의 학습과정에서 사용된 Binary Loss와, 세 이미지를 비교하여 loss를 계산하는 Triplet Loss가 대표적이다.
Binary Loss
앞의 Training 과정에서 Binary Loss는 다음과 같이 정의된다.
-
으로, 단순 CNN을 통과한 feature vector 간의 차의 절대값이다.
-
Binary Loss는 에 sigmoid 변환을 해준 후, 로 정의된다.
Triplet Loss
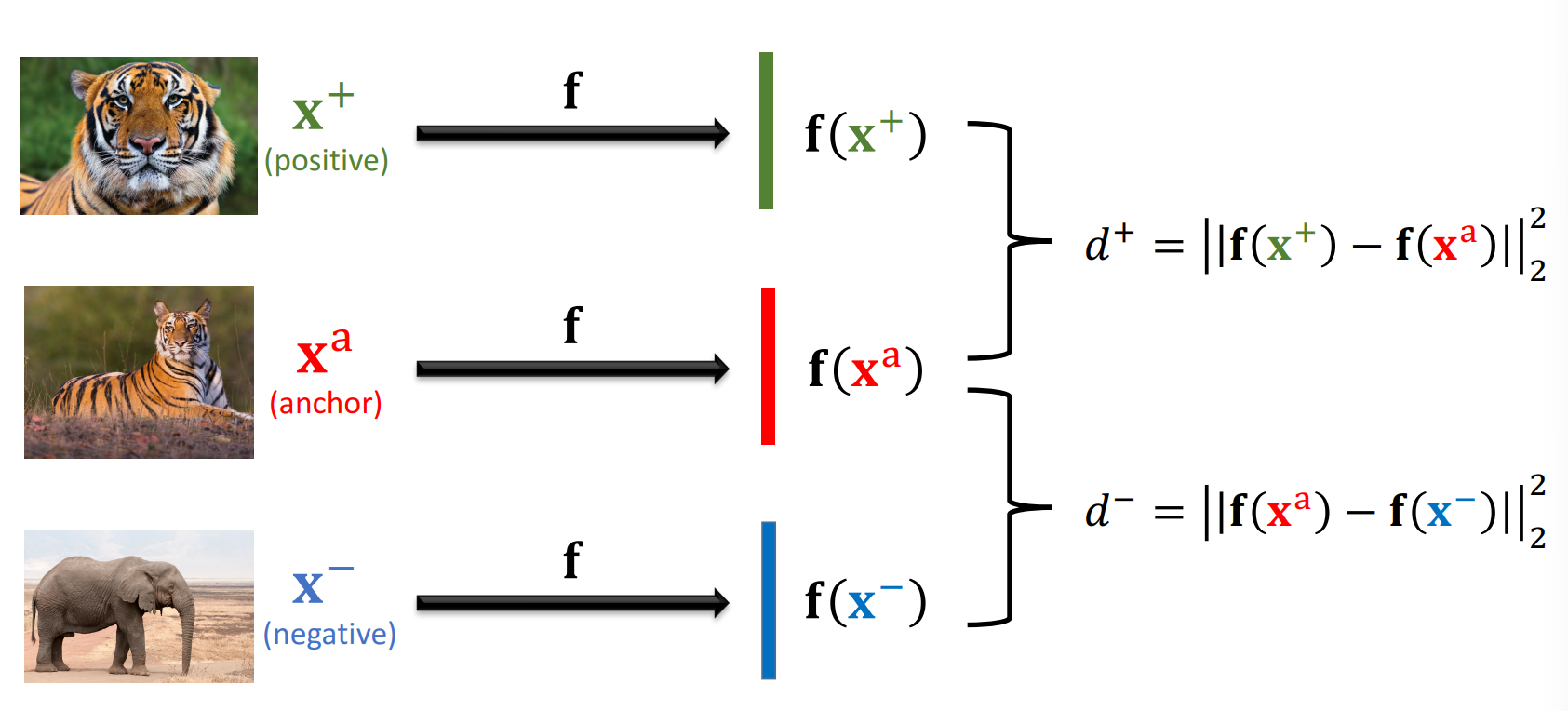
Triplet Loss에는 세 가지 입력값이 있다.
-
Anchor, : anchor 역할을 하는 학습 샘플
-
Positive, : 와 같은 class의 랜덤한 샘플
-
Negative, : 가 속한 class를 제외한 class에서 뽑은 랜덤한 샘플
세 가지 입력 이미지를 바탕으로 다음과 같이 Triplet Loss를 계산한다.
-
세 이미지를 하나의 CNN을 통과시켜 각각의 feature extraction을 진행한다.
-
와 , 와 간의 norm인 , 를 각각 계산한다.
- 이 때 같은 class에 있는 관계이므로 는 작은값, 다른 class에 있는 관계이므로 는 큰 값이 되도록 학습 시키는 것이 학습의 목표가 된다!
-
학습 목적에 맞게, Loss $L = max{0, d^+ + \alpha -d^-} 이 된다.
- 는 margin 값으로, , 가 매우 가까운 값일 때 두 distance 값 사이를 충분히 벌리기 위해 사용한다.
- 라면, loss = 0이 되도록 한다.
이기만 하면 loss = 0이 되는 거, 과연 괜찮을까?
단순 무작위 샘플링으로 학습 샘플을 고른다면 loss가 너무 쉽게 0이 되어버리므로 이는 학습을 방해하는 요소가 된다. 따라서 실제 모델 학습시에는 애초에 학습을 "어렵게" 만든다고 한다. 즉, 와 의 차이가 작은 (=구분이 어려운) 이미지끼리 묶어준다는 것!
Few-Shot Prediction
지금까지 Few-Shot Learning의 학습 과정을 살펴보았다. 그렇다면 예측 단계는 어떻게 수행될까?
단순하게는, 학습 샘플과 supporting set의 샘플 모두를 CNN으로 인코딩하고, 학습 과정에서 사용한 similarity function을 똑같이 적용해서 Support set의 각 class의 이미지(들의 평균)과 비교할 수 있을 것이다. 그러나 이러한 방식은 Support set의 샘플 수가 매우 적기 때문에 몇가지 다른 방식이 사용된다.
Making Prediction
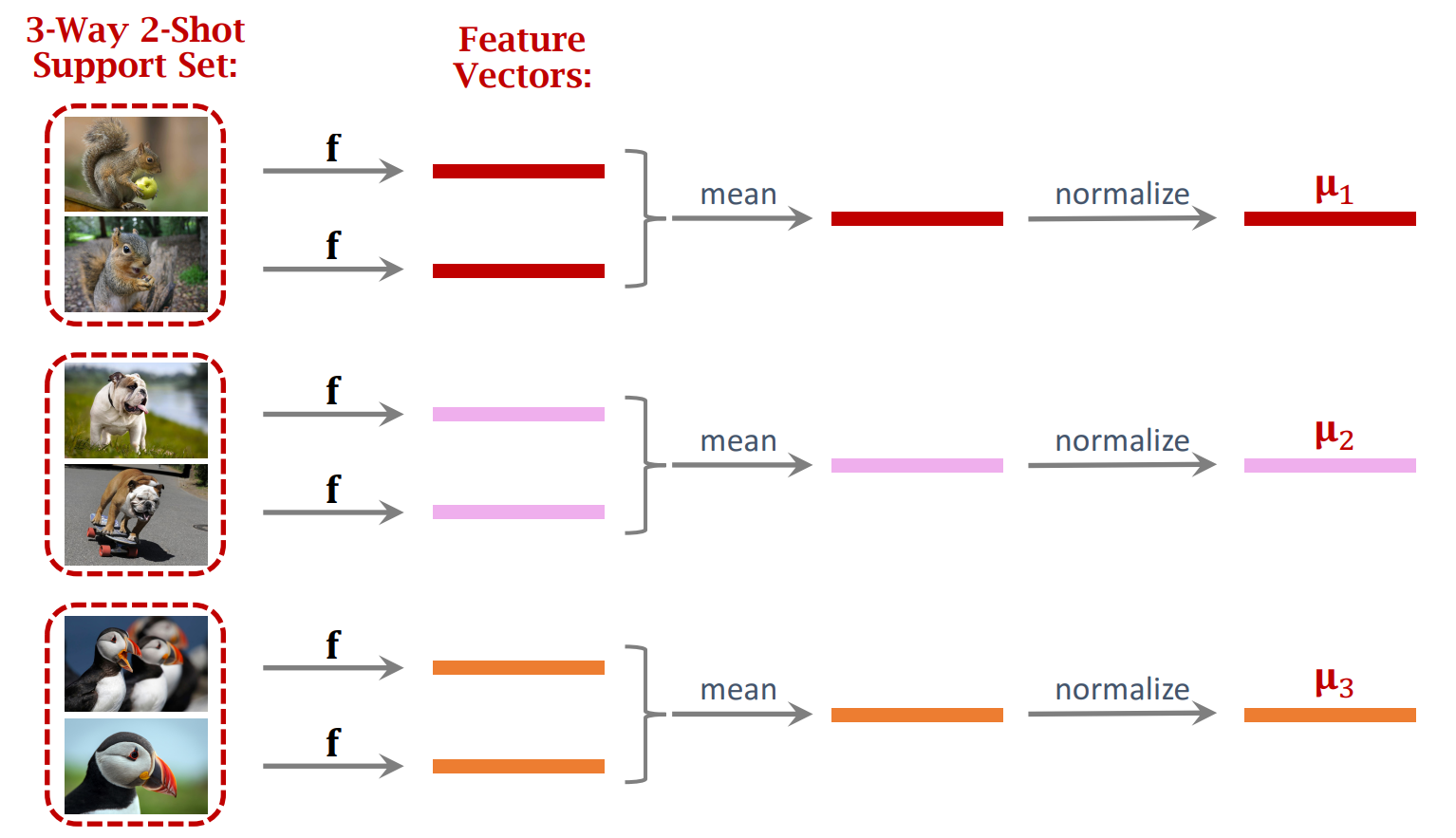
-
먼저 Support Set의 샘플을 동일한 CNN 를 통과시켜 feature vector를 구하고, 이를 다시 정규화시켜 값을 구한다. 를 row로 하는 matrix 을 구한다.
- , 로 다시 나타낼 수 있다.
-
같은 방식으로 Query Set의 샘플도 벡터로 임베딩한다. ()
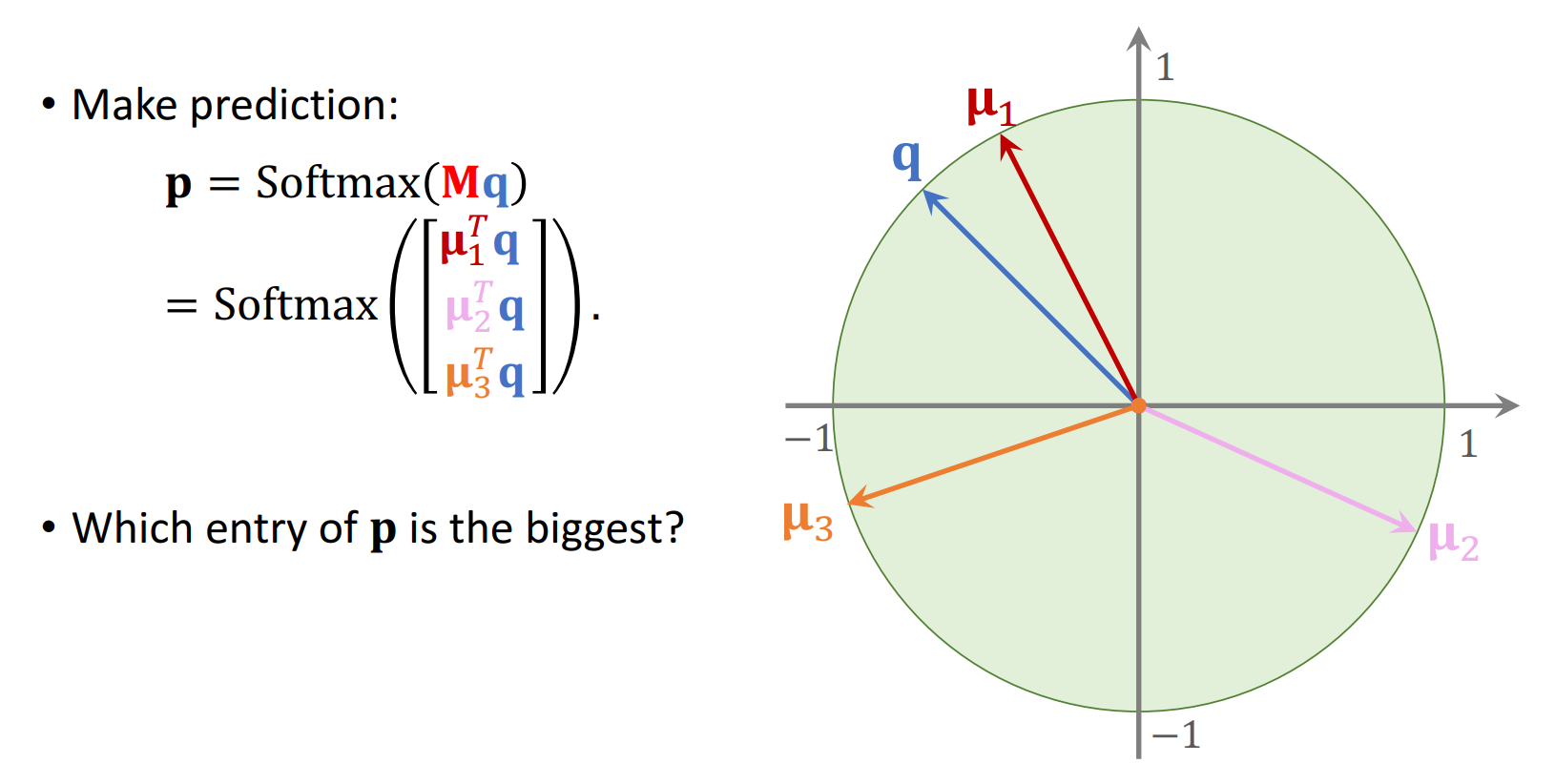
-
과 를 곱하여 softmax를 취해 확률 를 구한다.
- 1.에 의해 ()으로 다시쓰면, 우리가 익숙한 확률 함수이다.
Cosine Similarity
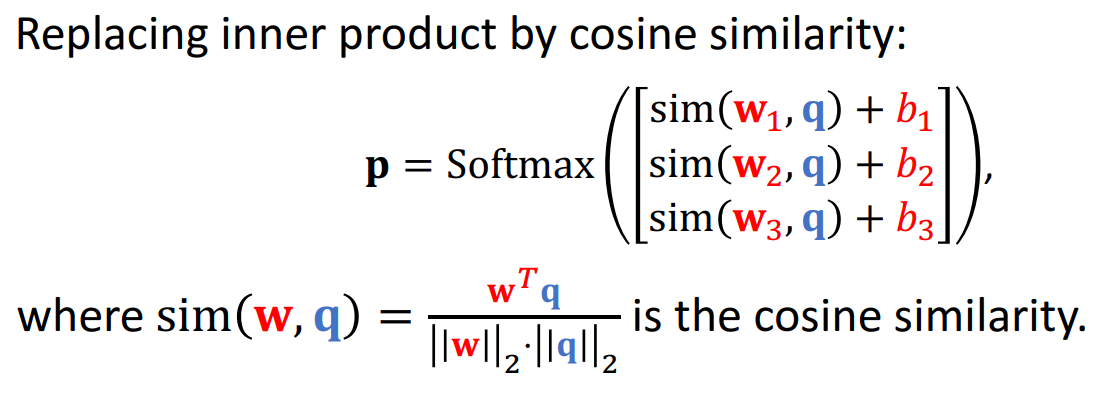
여기서 하나의 새로운 similarity function이 소개된다. 단순히 임베딩된 벡터끼리의 비교로 확률을 구하는 것이 아니라, cosine similarity를 활용하는 것이다. 이를 활용하면 벡터의 크기가 중요하지 않기 때문에, "패턴의 차이"(여기에선 방향의 차이)에 집중해야 할 때에 적합하다. 또한 prediction 과정에서 유사도 계산은 정규화 후 이뤄지는데, 이 과정에서 더 안정적인 유사도 비교가 가능하다. 계산은 간단하게 를 cosine similarity function으로 바꿔주게 된다.
Entropy Regularization
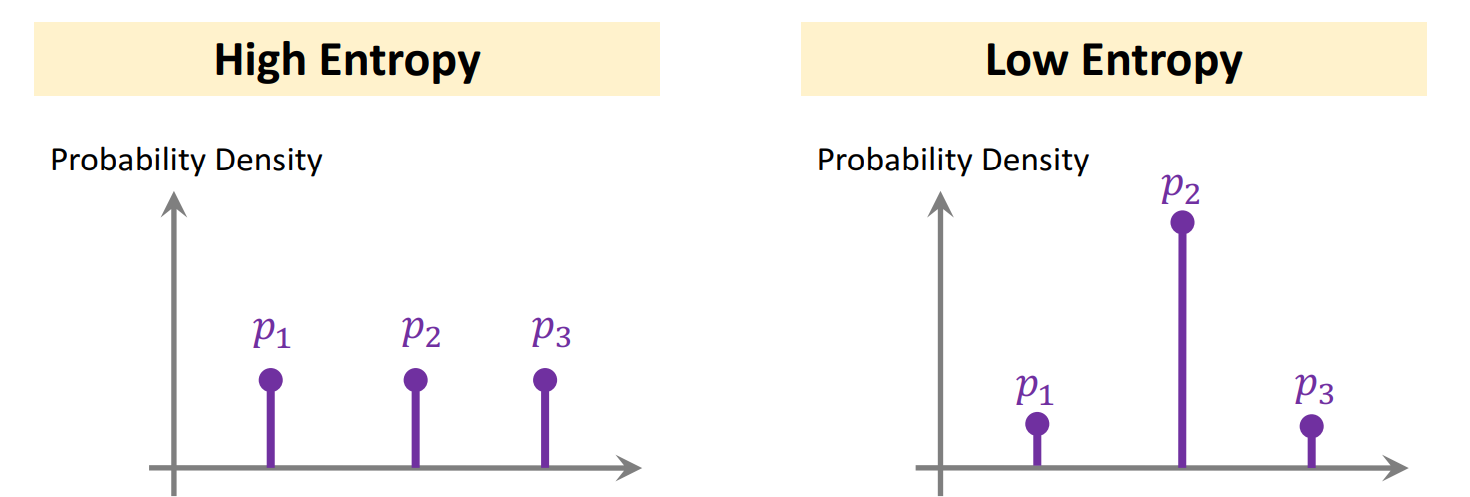
Entropy Regularization은 앞에서 임베딩 과정에 적용할 수 있는 하나의 방법이다. 확률 에 대해
로 정의되는 Entropy 함수에서, Query Set의 모든 query에 대해 의 평균을 구하여 정규화하게 된다. 이 때 엔트로피가 작아지게 만드는 것이 목표가 된다.
References
