이 글은 "인공지능연구개론" 수업 일환으로 작성된 영어 논문리뷰 블로그포스팅을 한글로 재번역한 것입니다.
Few-shot Gaussian Splatting[1]은 ECCV 2024에서 발표된 최신 논문이다. SIGGRAPH 2023에서 발표된 3D Gaussian Splatting[2]은 3D 재구성과 새로운 뷰 합성(Novel View Synthesis) 분야에서 획기적인 연구로 평가받으며 큰 주목을 받았다. 그 이후로 이 모델을 개선하기 위한 다양한 시도가 이루어졌으며, "FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting"은 그러한 노력 중 하나로, 3DGS의 희소한 입력에서의 성능을 향상시키는 방법을 제안한 연구이다.
이 글에서는 해당 논문을 이해하기 위해 필요한 배경 지식과 FSGS가 제안하는 동기 및 접근법에 대해 다룰 것이다.
Background
FSGS를 이해하기 위해서는 Novel View Synthesis (NVS)와 3D Gaussian Splatting (3DGS)라는 두 가지 핵심 개념을 이해하는 것이 중요하다.
Novel View Synthesis(NVS)
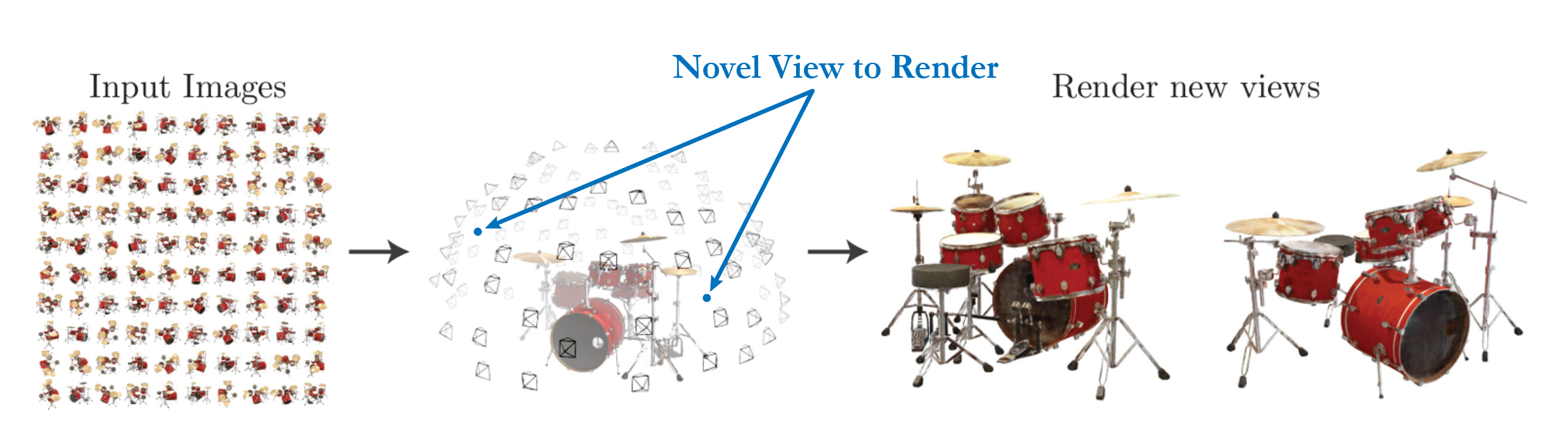
Novel View Synthesis는 제한된 수의 이미지를 input으로 받아 장면의 새로운 view를 생성하는 3D 비전 분야에서 핵심적인 테스크이다. 접근법은 깊이 추정(Depth Estimation)부터 장면 생성(Scene Generation)까지 다양하지만, 목표는 동일하다. 주어진 시점들 사이를 보간하여, 이전에 보지 못한 각도에서 장면이 어떻게 보일지를 예측하는 것이다.
NeRF and 3D Gaussian Splatting
대부분의 NVS가 주요 과제인 경우, NeRF[3]와 3DGS가 주요 비교 모델로 사용된다.
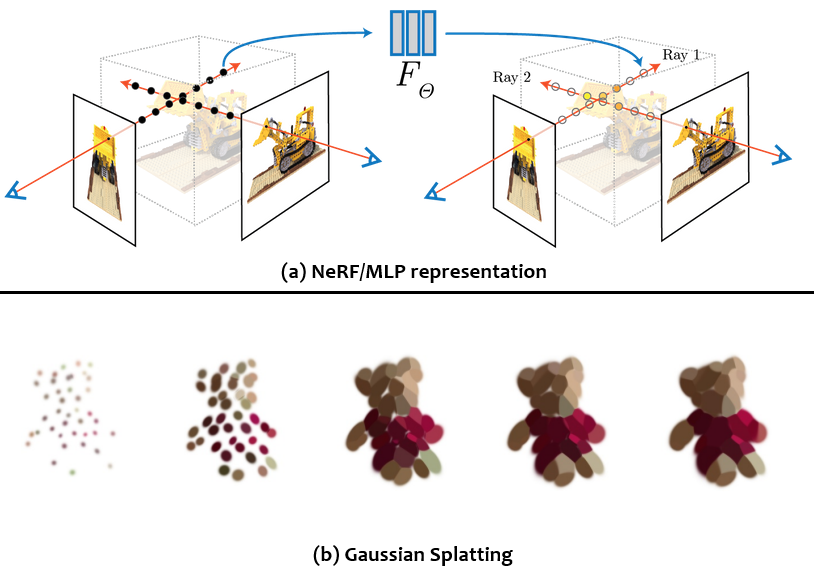
NeRF는 3D 장면을 밀도(density)와 방사(radiance)이라는 주요 매개변수를 사용하는 신경망으로 implicit하게 표현한다. 밀도는 투명도를 제어하며, radience는 scene 환경에 영향을 받는 색상과 lighting을 제어한다. 이를 통해 NeRF는 객체의 구조와 공간적 배치를 추론할 수 있다.
반면, 3DGS는 3D Gaussian이라는 타원형 3D 포인트를 통해 명시적으로 3D 장면을 표현한다. 각 가우시안은 위치, 크기, 색상, 불투명도, 방향성 등의 속성을 가진다. 3DGS는 사전에 2D 이미지로부터 생성된 point cloud를 입력으로 받는다. 이 점들은 단순히 표면을 샘플링한 데이터로, 각 점은 고유한 위치와 색상 정보를 포함한다. 각 점을 중심으로 3D 가우시안을 생성하며, 이들의 속성을 입력된 참조 이미지(ground truth)에 맞게 학습시킨다. 3DGS가 인기를 얻는 이유는 거의 실시간으로 3D 재구성과 NVS를 수행할 수 있기 때문이다.
여기서 중요한 질문이 제기된다. 3D Gaussian Splatting은 3D 장면을 적절히 표현하기 위해 충분한 point cloud가 필요하다. 그렇다면, 만약 장면을 완전히 포착하기에는 point cloud가 부족할 경우엔 어떻게 될까? 3DGS가 그러한 sparse한 조건에서도 장면을 충분히 표현할 수 있을까?
Few-shot 3DGS
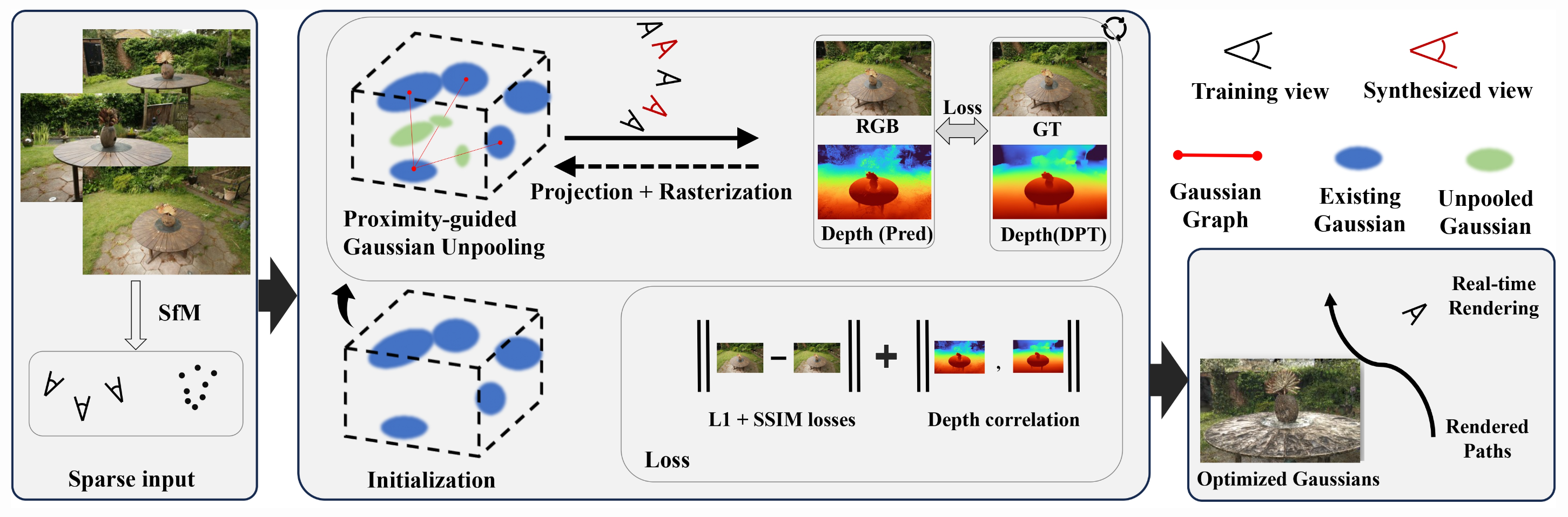
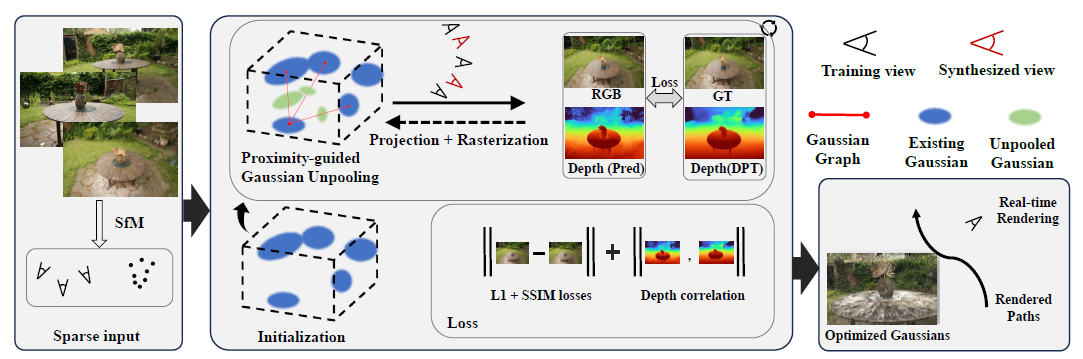
Problem Setting
3DGS는 initial 가우시안을 생성하기 위한 정점이 부족할 경우 3D 장면을 정확히 표현하는 데 어려움을 겪는다. sparse한 입력에서 발생하는 문제를 생각해보자. 첫째, input 이미지의 수가 적기 때문에 모델이 레퍼런스로 삼을 뷰가 부족 하고, 이는 input 이미지에서는 보이지 않는 가려진 scene 일부에 대한 perspective 부족으로 이어진다. 이는 깊이 예측을 어렵게 만든다. 둘째, 다양한 perspective의 부족은 가우시안의 수가 부족하게 만들어 장면을 적절히 "그려내는" 데 한계를 준다.
FSGS의 저자들은 few-shot 세팅에서 3DGS를 적용할 때 발생하는 두 가지 주요 문제를 다음과 같이 정의한다.
1. Smooth Texture
부족한 입력 이미지로 인해 3DGS는 가우시안을 충분히 생성하지 못한다. 이는 너무 크거나 과도하게 늘어난 가우시안을 초래한다. 3DGS에서는 이를 "Adaptive Density Control" 방식으로 접근하여 해결하지만, 입력 이미지가 너무 적을 경우 결과적으로 모델은 scene의 디테일을 표현하지 못하고 지나치게 부드러운 텍스처를 생성하게 된다.
2. Overfitting Propensity
희소한 입력은 또한 모델이 학습된 뷰포인트에 과적합하는 경향을 증가시킨다. 이는 가우시안이 학습된 뷰 방향으로 늘어나는, 부정확한 장면 표현을 초래한다.
Approaches
위에서 언급한 문제를 해결하기 위해, FSGS는 두 가지 주요 접근법을 채택하여 부족한 요소들을 "더 많이" 생성하는 것을 목표로 한다. 즉, 더 많은 가우시안과 더 많은 이미지(따라서 더 많은 깊이 정보)를 생성하는 것이다.
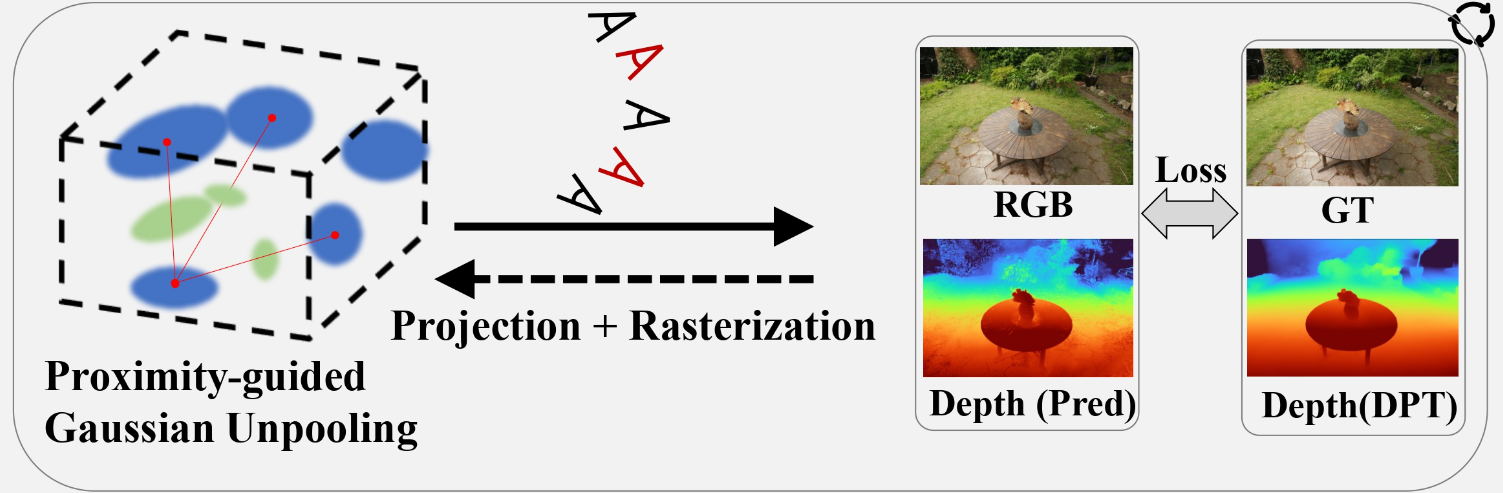
1. Proximity-guided Gaussian Unpooling
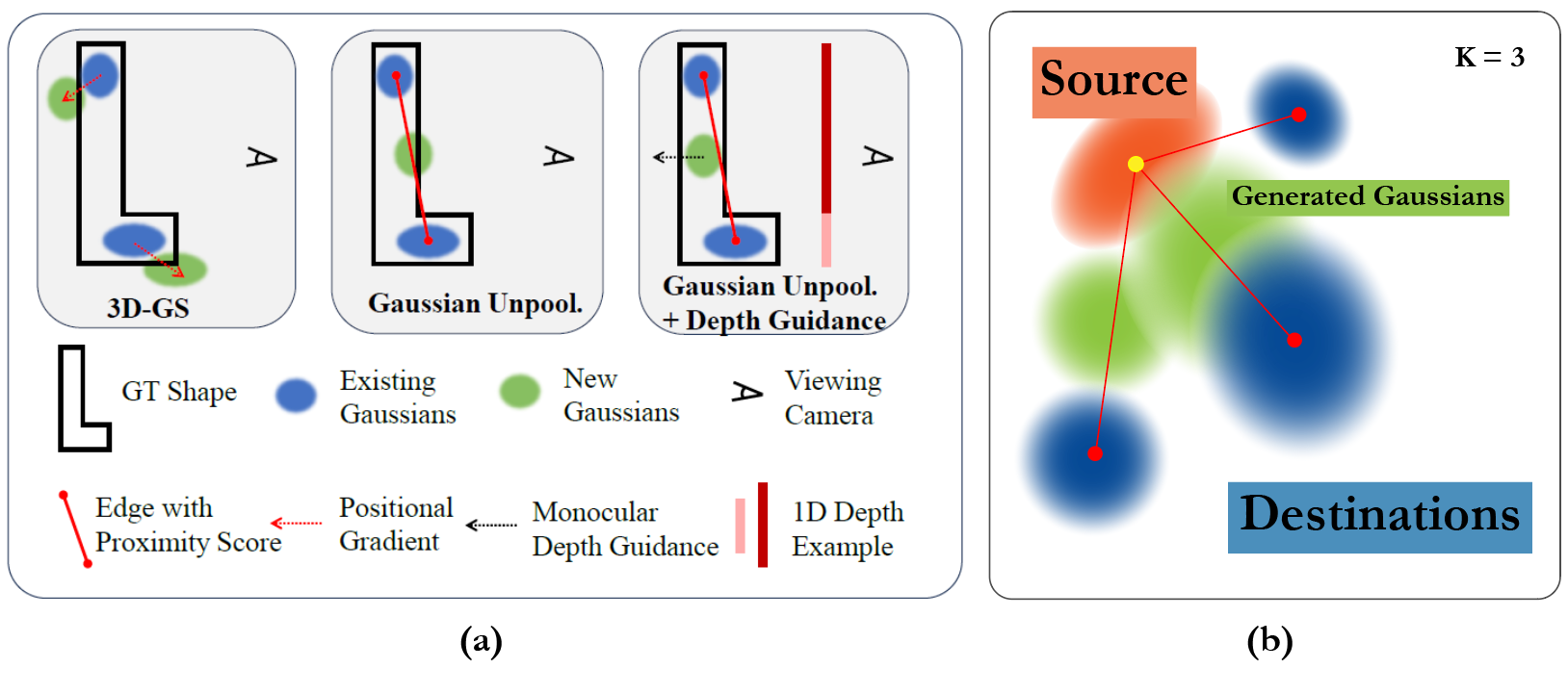
근접성 기반 가우시안 Unpooling은 추가 가우시안을 최적의 위치에 생성하는 기술이다. 이 방법에서 기존 가우시안 중 하나가 "Source" 가우시안으로 지정되고, 가장 가까운 개의 가우시안이 "Destination" 가우시안으로 지정된다. 구체적으로, Source 가우시안은 다른 세 가우시안과의 유클리드 거리가 가장 작은 가우시안이다. Source와 Destination 가우시안 사이의 유클리드 거리가 특정 임계값을 초과하면, 두 가우시안을 연결하는 선을 따라 새로운 가우시안이 생성된다. 새 가우시안은 Destination 가우시안의 초기 크기와 불투명도를 상속받고, 다른 속성은 0으로 초기화된다.
2. Geometry Guidance for Gaussian Optimization
이 접근법에서는 "pseudo view" 를 생성하여 입력의 희소성을 완화한다. 이 pseudo view는 기존 참조 뷰포인트(GT 뷰포인트) 사이에 위치하며, 이 위치에서 카메라 뷰가 생성된다. 이 위치에서 렌더링된 이미지는 학습 과정에서 사용된다. 그러나 가상 뷰 자체가 "예측된" 이미지이기 때문에, FSGS는 이를 효과적으로 활용하기 위해 깊이 정보를 활용한다.
Depth Map Utilization
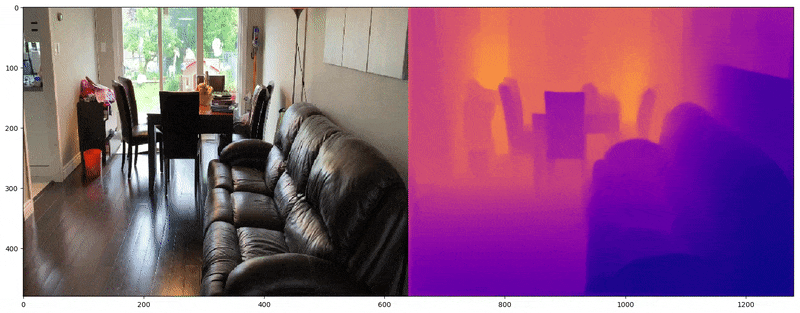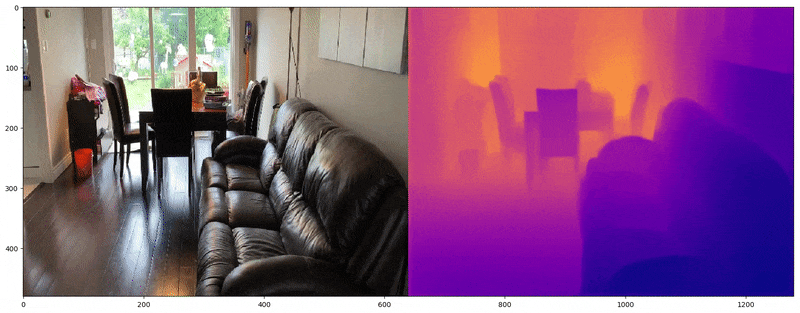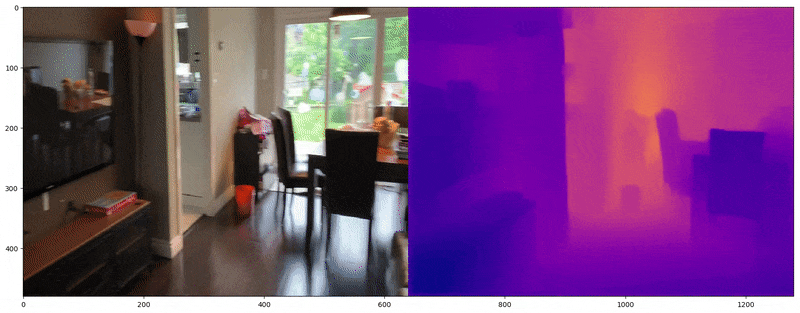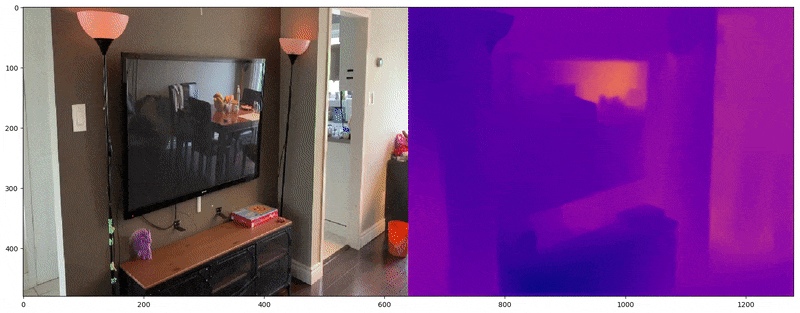
깊이 맵은 공간 깊이를 알파 또는 RGB 표현으로 제공하며, 컴퓨터 비전에서 2D 이미지로부터 3D 공간을 재구성하는 데 일반적으로 사용된다. FSGS는 깊이 맵을 활용하여 두 가지 유형의 깊이 데이터 간 상관관계를 계산한다: (1) 래스터화된 이미지의 깊이 (2) 3D 가우시안에서 추출된 깊이. 이 두 깊이를 비교하여 3D 가우시안의 공간적 정확도를 학습시킨다.
(1) 입력 이미지의 깊이
먼저, 가상 뷰와 GT 뷰 모두에 대해, image-depth 쌍으로 사전 학습된 Dense Prediction Transformer(DPT)[5]를 사용하여 이미지의 깊이를 예측한다.
(2) 3D 가우시안에서 추출된 깊이
반면, 이 깊이 맵은 학습 중에 출력되는 렌더링된 뷰로부터 유도(또는 래스터화)된다. 이는 실제 학습 중인 3D 가우시안에서 렌더링된 장면의 깊이에 기반하여 생성된다.
Conclusion
이 글에서는 FSGS로 이어지는 연구의 발전 과정과 핵심 접근법을 다루었다. Few-shot NVS 과제는 여전히 중요하다. 이는 사용자가 NVS를 수행하기에 충분한 입력 이미지를 확보하지 못하는 Real-world 시나리오를 다루기 때문이다. FSGS에서 제안된 방법들은 이러한 과제에 해결책을 제시하며, 실시간 렌더링 기능과 높은 모델 성능을 포함한 3DGS의 장점을 유지한다.
그러나 FSGS의 접근법에 대해 다음과 같은 두 가지 질문을 던지고 싶다:
- 생성된 가우시안을 초기화하는 데 있어, 일부 속성 값을 0으로 설정하는 것보다 더 나은 방법이 있을까?
- 첫 번째 깊이 맵은 DPT에 의해 "예측"된 것이고, 두 번째 깊이 맵은 "예측된" 가우시안으로부터 생성된 것이다. 예측된 깊이 맵 간의 상관관계를 사용하여 모델을 학습시키는 것이 stable할까?
FSGS의 실험 결과는 이 글에서 다루지 않았지만, FSGS 프로젝트 페이지[6]에서 더 많은 세부 정보와 결과를 확인할 수 있다.
References
[1] Zehao Zhu, Zhiwen Fan, Yifan Jiang, and Zhangyang Wang. 2023. FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting. arXiv [cs.CV]. Retrieved from http://arxiv.org/abs/2312.00451
[2] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 2023. 3D Gaussian splatting for real-time radiance Field rendering. arXiv [cs.GR]. Retrieved from http://arxiv.org/abs/2308.04079
[3] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing scenes as neural radiance fields for view synthesis. arXiv [cs.CV]. Retrieved from http://arxiv.org/abs/2003.08934
[4] Priya Dwivedi. 2019. Depth Estimation on Camera Images using DenseNets. Towards Data Science. Retrieved November 1, 2024 from https://towardsdatascience.com/depth-estimation-on-camera-images-using-densenets-ac454caa893
[5] Ranftl René, Bochkovskiy Alexey, and Koltun Vladlen. 2021. Vision Transformers for Dense Prediction. arXiv [cs.CV]. Retrieved from http://arxiv.org/abs/2103.13413
[6] Zhangyang Wang. FSGS. Github.io. Retrieved November 1, 2024 from https://zehaozhu.github.io/FSGS/
[7] Researchgate.net. Retrieved November 1, 2024 from https://www.researchgate.net/figure/Novel-3D-data-representations-3-6_fig3_381142897
