[CV/논문리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Paper Review
ECCV 2020에서 발표된 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis는 MLP를 활용하여 복잡한 장면의 Novel View Synthesis(NVS) 테스크를 수행하는 연구이다. NeRF는 MLP를 활용한 이전 모델들이 복잡한 장면의 high frequency detail들을 효과적으로 재현하지 못하는 한계를 극복하며, NVS 테스크에서 큰 성능 향상을 이루었고 현재까지도 3D Reconstruction과 NVS 분야에서 NeRF의 응용 논문이 여럿 나오고 있다.
모델 구조와 아이디어는 꽤 명료한 편이므로 다소 생소한 접근법과 수식에 대한 이해를 중심으로 포스팅을 작성해 보려 한다.
Key Points
- View Dependence를 고려하여 입력값으로 좌표 뿐 아니라 View Direction(시점 방향) 추가
- MLP 기반의 연속적인 3D representation
- 미분가능한 Volume Rendering을 활용하여 Backpropagation을 가능하게 함
- 최적화를 위한 Positional Encoding과 Hierarchical Volume Sampling
논문에 대해 이야기하기 전, 먼저 간단한 Background를 살펴보자.
Background
3D Graphics
3D Representation
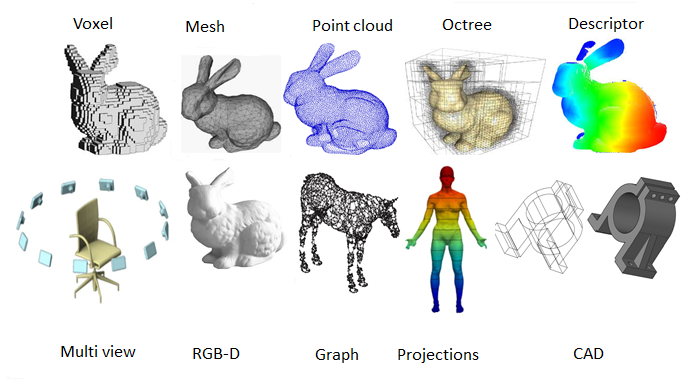
그래픽스에서 3D Scene이나 Object를 나타내는 방식에는 여러가지가 있다. 몇가지만 소개하자면 다음과 같다:
-
Mesh: 가장 보편적으로 사용되는 방식으로, 모델링부터 렌더링까지 그래픽스의 여러 영역에서 활용이 용이하다. 그러나 NN 기반의 View Synthesis에 mesh로 3D Reconstruction을 구현하는 것은 mesh 구조 자체의 불규칙성 때문에 적절한 토폴로지를 생성해 내는 것이 어려우며 상당히 느리다는 한계가 있다.
-
Voxel: 2D 픽셀의 3D 버전이라고 생각할 수 있다. 보통 그래픽스에서 빠르게 저해상도로 연기 등의 파티클 시뮬레이션을 렌더링해 보는 상황에서 사용하게 된다. 또한, NN 기반 방식에서 Voxel로 3차원 scene을 표현할 때에는 렌더링 대신 활용하는 Occlusion-aware projection기법이 물리법칙에 위배된다.
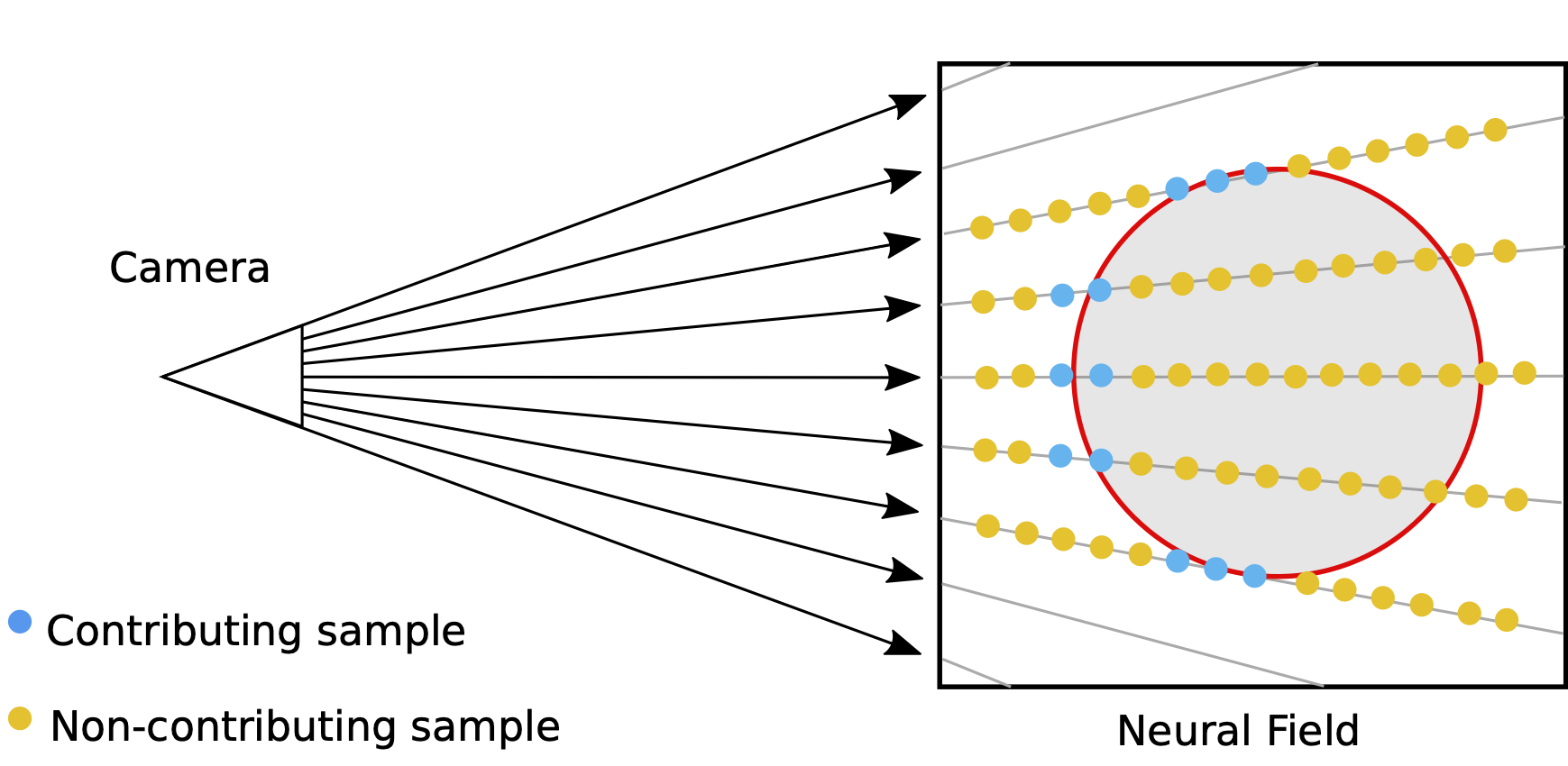
후술할 NeRF의 Volume Rendering 수식에서 다시 살펴보겠지만, 우리가 자연스럽게 느끼는 물리적 컨셉과 일치하기 위해서는 ray 위에서 시간 t에 따라 Transparency(투과도)는 감소해야 한다. 앞에 물체가 존재하고 ray와 collision이 발생했다면 그 뒤의 샘플포인트의 transparency가 더 클 수는 없기 때문이다. Voxel 기반 표현은 렌더링 수식을 사용하지 않고 신경망으로 2D 이미지의 feature를 3D Voxel의 latent feature를 인코딩하는 방식으로 3D Reconstruction을 수행하기 때문에 이러한 물리 법칙에 항상 부합하지는 않는다. -
Point cloud: 말 그대로 점을 이용해 객체를 표현하고, 표면에 대한 정보를 제공하지 못한다는 단점이 있다. 이러한 표현방식은 이후 3DGS의 아이디어가 된다.
앞서 언급한 세 가지 3D 표현 방식은 Explicit한 표현으로, 3D Geometry를 구체적으로 정의된 요소들을 기반으로 명시적으로 표현한다.
반면에 Implicit한 3D 표현 방식도 존재한다. 이 방식은 함수나 신경망을 통해 3D Geometry를 표현한다. 대표적으로 Signed Distance Function(SDF)와 같은 함수가 있다. NeRF의 경우 scene을 implicit function으로 학습하는 신경망이므로 Implicit한 표현방식을 활용한다.
Ray
3D Vision, 그래픽스 분야에서 Ray의 개념은 매우 중요하다. Ray는 카메라로부터 시작되고, 카메라가 바라보는 방향으로 쏘아지는 일종의 광선이다. NeRF에서는 한 픽셀을 렌더링하기 위해 카메라에서 발사된 ray 를 따라 색상을 합산한다. ray는 일종의 직선이므로,
로 표현된다:
- : 카메라의 원점
- : 입력으로 받은 ray의 viewing direction
- : 매개변수
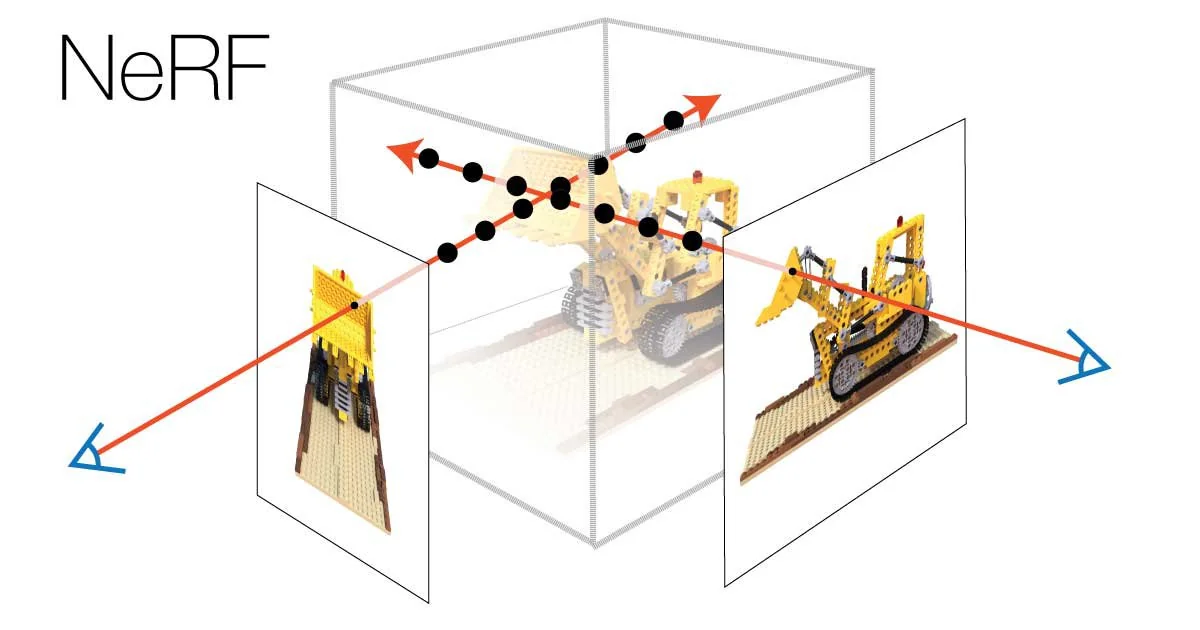
NeRF에서처럼 모델에 주는 입력이 2D "이미지"인 경우, 모델에 이미지 한 장당 카메라의 초점거리와 카메라 중심좌표, 카메라가 바라보는 방향 등을 함께 제공하게 된다.
이 때 제공된 카메라 파라미터를 바탕으로 정해진 , 에 맞추어 이미지 한 장 위의 각 픽셀에서 ray가 방출된다. 이론상으로는 모든 픽셀에서 ray를 방출하지만, 실제로는 계산을 위해 ray를 적절히 샘플링하게 된다.
NN for View Synthesis
Interpretability
머신러닝, 딥러닝은 대체적으로 "black-box"라는 특징을 가지고 있다. 특히 딥러닝은 깊은 모델 구조 때문에 모델 내부의 판단 기준은 인간이 파악하기 어렵다. 그러나 블랙박스라는 뉴럴네트워크의 특성은 NVS 테스크를 단독으로 수행하기에 다소 문제적이다.
View Synthesis의 보편적인 과정을 살펴보면 2D 이미지를 통해 3D Scene을 재구성하고, 다시 이를 새로운 각도에서 바라본 2D 이미지로 뽑아낸다. 이 때, 학습을 통해 재구성된 3D Scene에서 다시 2D 아웃풋 이미지를 렌더링하는 과정은 해석 가능한 데이터를 요구한다. NeRF는 그래픽스 파이프라인에서 사용하는 렌더링 방정식을 차용해 이 문제를 해결한다. 학습 과정에서 직접 explicit한 3D Geometry를 생성하여 View Synthesis를 하기보다, 입력된 정보를 바탕으로 Ray 위의 한 점에서의 밀도 와 색상 을 학습하고, 이를 통해 inference 할 때 Novel View의 2D 이미지를 도출하기 때문이다.
Input, Output and Objective
View Synthesis를 위한 딥러닝의 학습단계에서 입출력과 목적함수를 간단하게 생각해보면 다음과 같다:
- Input: 여러 시점에서의 2D 이미지와 여기서 추출된 정보(camera extrinsic, intrinsic 등)
- Output: input view (GT)에 대한 2D 이미지
- Loss: output 이미지와 GT 이미지 사이의 Pixel-wise difference의 합
학습이 끝나면 Inference 단계에서 새로운 시점에 대한 2D 이미지를 생성해낸다.
Motivation and Contribution
Motivation
- View Synthesis 테스크에서 기존의 접근은 입력 이미지를 엄청나게 많이 필요로 했다.
- 혹은 3D 표현방식에 있어서 mesh, voxel 기반의 explicit한 3D 재구성 방식을 사용하였으나, 복잡한 장면에서 비효율적이거나 고해상도 디테일을 잡아내지 못하였다.
Contribution
- 5차원 입력으로 좌표 뿐만 아니라 Viewing Direction 를 추가하였다. 이에 따라 view-dependent한 색상 출력이 가능해진다.
- Volume Rendering 수식 기반으로 미분가능한 렌더링 기법을 활용, Rendering Loss를 계산하는 방식으로 최적화. 덕분에 해석가능한 변수를 활용할 수 있게 되어 물리적 컨셉과 일치하는 View Synthesis가 가능해진다.
- Positional Encoding과 Hierarchical Sampling으로 high-frequency 정보 학습 능력을 향상시켰다.
Architecture
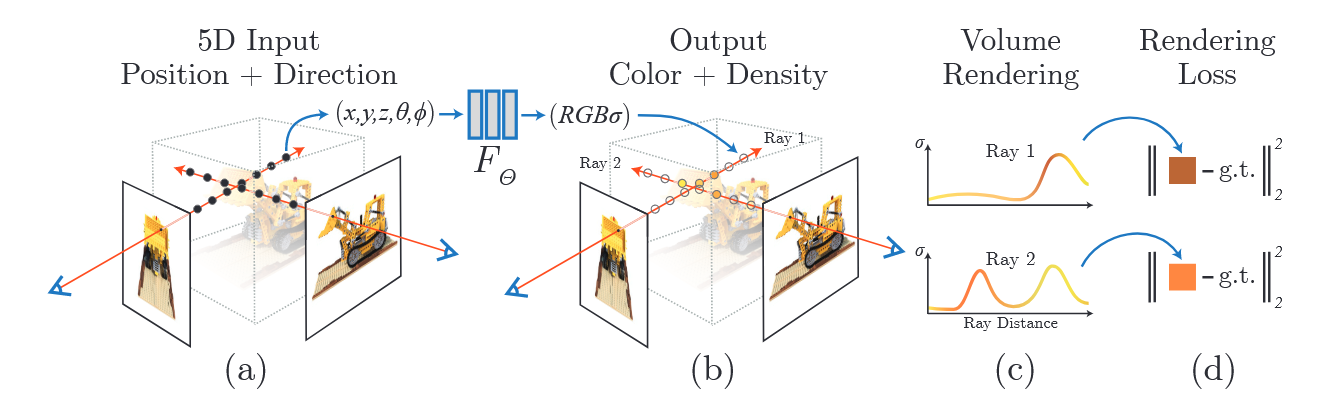
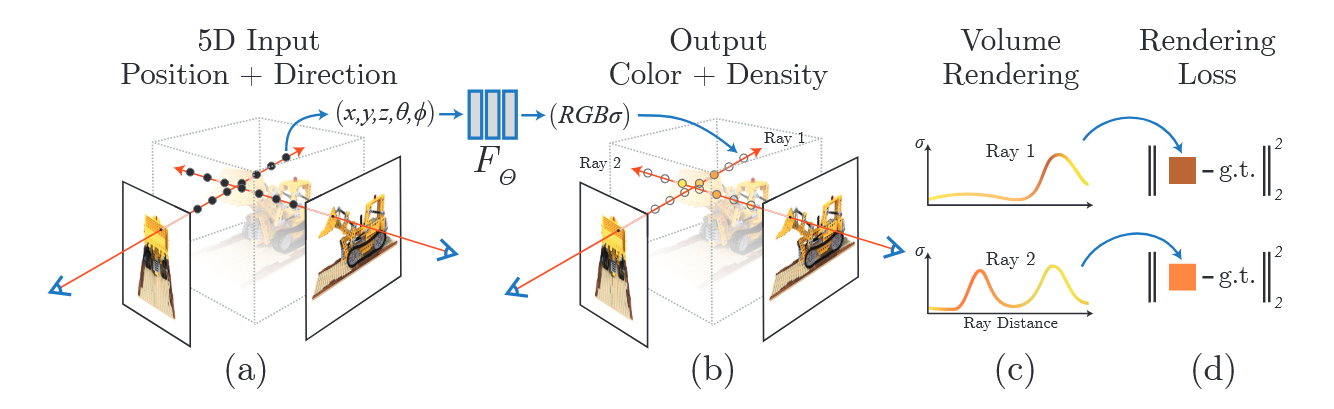
NeRF의 전체 구조는 대략적으로 다음과 같다.
(a) 이미지의 각 픽셀에서 Ray를 쏘아 그 위의 점들을 샘플링한다. 그리고 하나의 Ray 위의 각 샘플링 포인트의 위치좌표와 Ray의 방향인 viewing direction을 네트워크에 입력으로 준다. 이 때 입력은 Positional Encoding을 통해 고차원으로 매핑된다.
(b) 네트워크는 각 샘플링 포인트에 대해 밀도와 시점 의존적인 색상을 출력한다.
(c) 하나의 Ray 위의 모든 샘플링 포인트들의 밀도와 색상을 합하여 Volume Rendering한다. 출력된 값은 Ray를 쏘아 준 픽셀 값에 대한 예측값이 된다. 이 때 High frequency 디테일을 표현하기 위해 밀도가 높은 부분에서 추가적인 샘플링을 진행하는 Hierarchical Volume Sampling을 통해 학습을 최적화한다.
(d) 한 픽셀의 GT 값과 Volume Rendering된 예측값의 MSE Loss를 계산하는 방식으로 역전파를 진행한다.
Network Structure
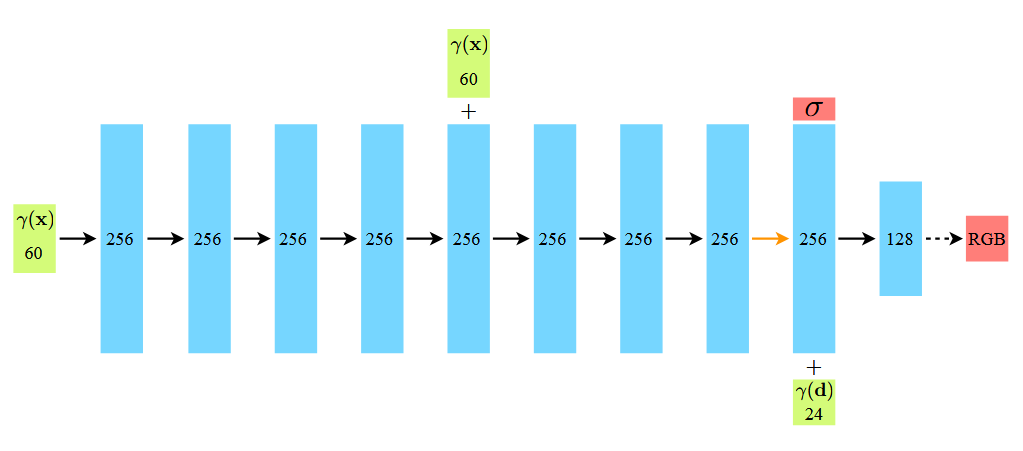
NeRF의 네트워크 구조만 보면 사실 상단 이미지가 전부로, 상당히 간결하다.
구성 요소는 다음과 같다:
-
-
Input:
- : 위치 좌표
- : viewing direction
- Output: density , RGB radiance
- : 위치 에서의 밀도
- : 위치 와 viewing direction 에서의 RGB 컬러
네트워크는 fully-connected 레이어로만 구성되어 있으며, 입력 5D 좌표를 이에 대응하는 volume density 와 시점 의존적인 색상 로 매핑하도록 가중치 를 최적화하도록 학습된다. 밀도는 다중 시점에서 항상 일관적이어야 하므로 8개의 fc 레이어에서 만으로 학습이 진행된다. 다섯번째 레이어에서 skip connection을 한번 거치고, 밀도 를 출력하는 추가 레이어에서 시점 의존적인 를 위해 를 입력으로 추가하게 된다.
밀도는 항상 0 이상이 되어야 하므로 앞 8개의 레이어에서는 활성함수로 ReLU를 사용해주고, 를 출력하기 전에는 Sigmoid 함수를 사용하여 색상 값을 정규화해준다.
cf). 입력에 2D 이미지만 주고 카메라 extrinsic, intrinsic 파라미터 정보가 필요없나 궁금했는데, 코드를 보니 필요했다. point cloud를 만들지 않으니 3DGS처럼 SfM을 사용하지는 않지만, 픽셀 좌표계에서 카메라 좌표계로 변환할 때 카메라 데이터 사용한다.
Methods
Volume Rendering
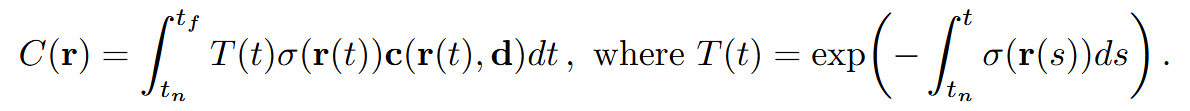
NeRF 논문을 처음 읽을 때 가장 당황스러운 부분을 꼽으라면 아마 이 렌더링 방정식을 만났을 때일 것이다. 이 수식은 Ray 하나의 radiance를 구하는 수식이다. 즉, 하나의 "픽셀" 값을 결정하는 수식인 것이다. 우리의 목표는 네트워크에서 출력된 를 이 방정식에 넣어서, 특정 픽셀 값인 을 예측하고, 이를 GT 이미지의 해당 픽셀값과의 비교를 통해 Loss를 계산하는 것이었다.
따라서 큰 틀에서, 이 수식은 부터 까지 특정 ray 위의 지점 에 대한 값을 바탕으로 한 radiance 정보를 차곡차곡 적분해서 전체 ray의 radiance 값을 구해내는 과정이다.
Density
피적분함수가 무엇을 의미하는지를 알아보기 위해서, 먼저 밀도 의 진짜 의미를 생각해 볼 필요가 있다.
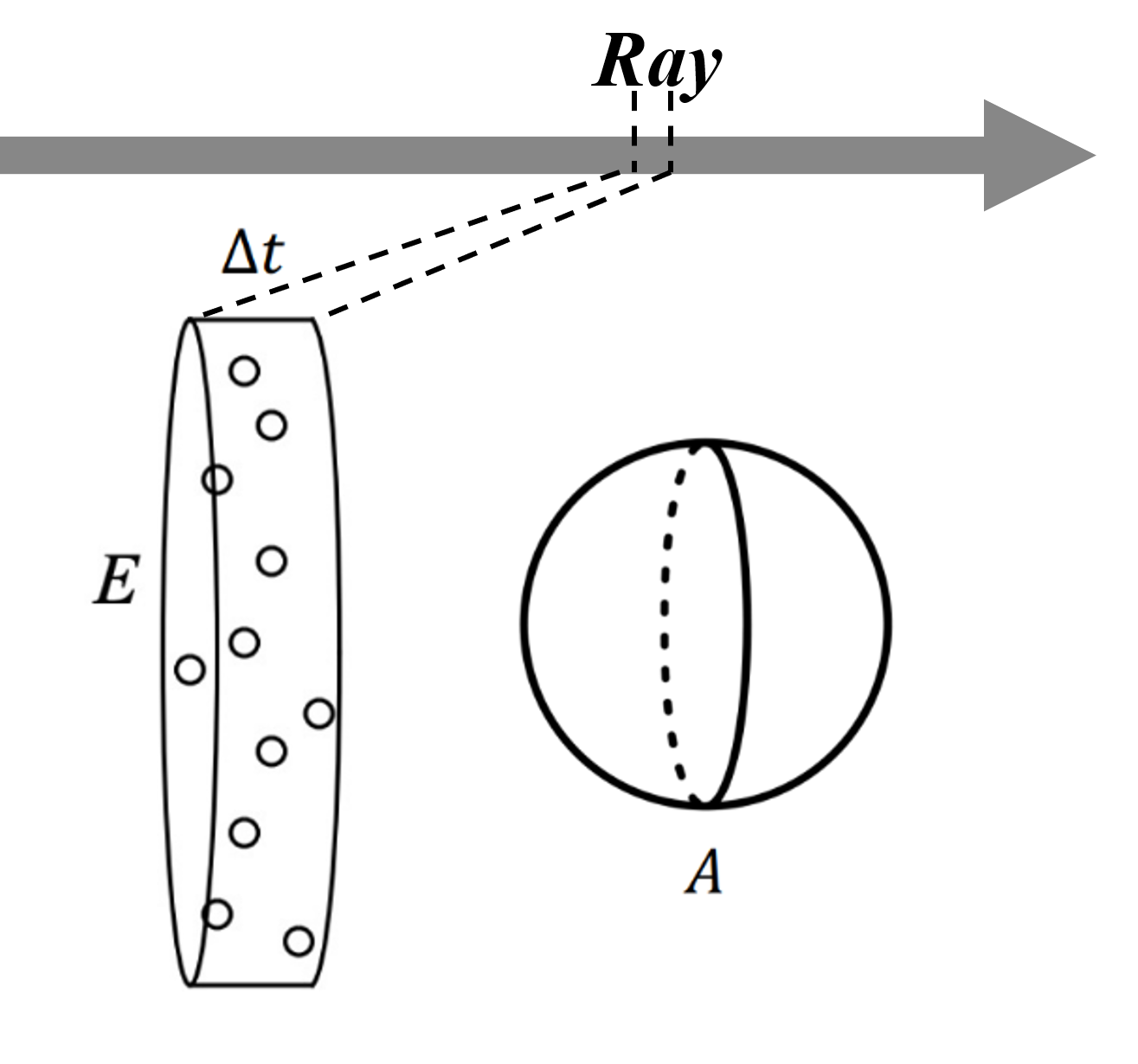
는 특정 지점에서의 volume density 또는 소멸 계수(extinction coefficient) 를 나타낸다. 이는 해당 위치에서 ray가 얼마나 흡수되거나 산란되는지를 결정한다.
더 쉽게 생각해 보자면, ray 위의 한 영역을 확대해 생각해 볼 수 있다. 이 영역 내에 물체나 volume이 존재한다면, 그 안의 여러 입자가 ray에 충돌할 것이다. 이 때, 지점에서 이 입자의 밀도를 , 그림의 확대된 ray가 통과하는 면적을 , 입자 하나의 단면적(= 입자의 투영된 면적)을 라 한다면, 밀도는 다음과 같은 개념에서 유도된다:
- : 특정 ray 영역 내 입자의 수
- : 직관적으로 입자에 의해 가려진 ray 영역의 비율이므로, ray가 특정 구간에서 만나는 입자의 비율
- : 특정 지점에서의 소멸 계수(opacity)
결론적으로, 는 ray가 특정 위치에서 얼마나 흡수될 가능성이 있는지를 나타내는 값으로, 입자의 밀도와 크기를 모두 반영하게 된다.
이러한 이해를 바탕으로, 위의 volume rendering 수식을 구체적으로 살펴보면 다음과 같다:
- : 지점 에서의 충돌 확률. Ray가 까지 투명도를 유지하였다가 딱 에서 충돌할 확률.
- : 투명도. 광선이 특정 지점 까지 충돌하지 않고 통과할 확률
 가 커질수록 는 작아지므로, voxel 표현에서 문제되었던 물리적 컨셉과의 일치가 이루어짐
가 커질수록 는 작아지므로, voxel 표현에서 문제되었던 물리적 컨셉과의 일치가 이루어짐
- : 소멸 계수. 시점에 충돌할 확률 밀도
- : 투명도. 광선이 특정 지점 까지 충돌하지 않고 통과할 확률
- : 특정 위치, 시점 방향에서의 색상
그리고 이 방정식은 다시 실제로 코드를 통해 구현되기 위해, 연속적인 적분이 아니라 구간을 샘플링하여 이산적으로 합산하는 방식으로 표현되고 결과적으로는 다음 방정식을 통해 하나의 ray에 대한 radiance 값이 도출된다:
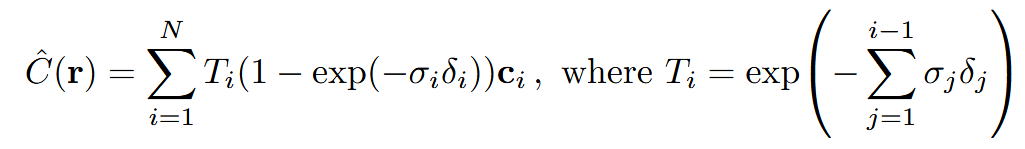
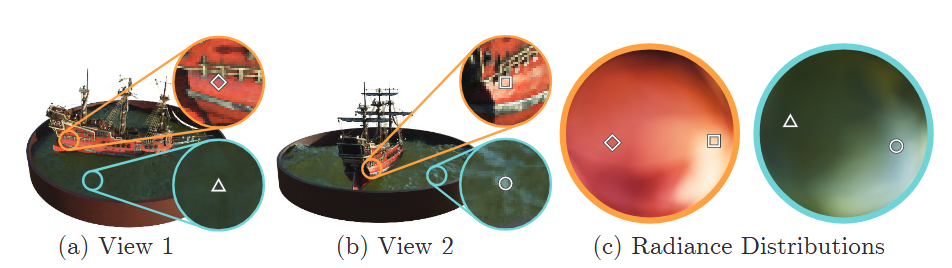
결과적으로, 그림과 같이 방향에 따라 색상이 다르게 나타나는 view-dependent한 radiance가 표현될 수 있다.
Optimization
Input: Positional Encoding
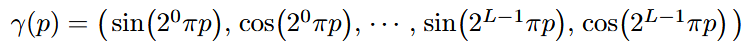
Positional Encoding은 high-frequency 특징 학습을 돕는다.
는 을 의 고차원으로 매핑시켜주는 함수로, Transformer 모델 아키텍처에서 나타나는 positional encoding과 유사한 형태로 사인,코사인 변환을 통해 차원을 확장하고, 입력값에 적용되어 결과적으로 네트워크는 대신 을 입력으로 받게된다.
이 때 일 때 가장 실험적으로 성능이 좋았다고 논문은 밝히고 있다.
Hieriarchical Volume Sampling
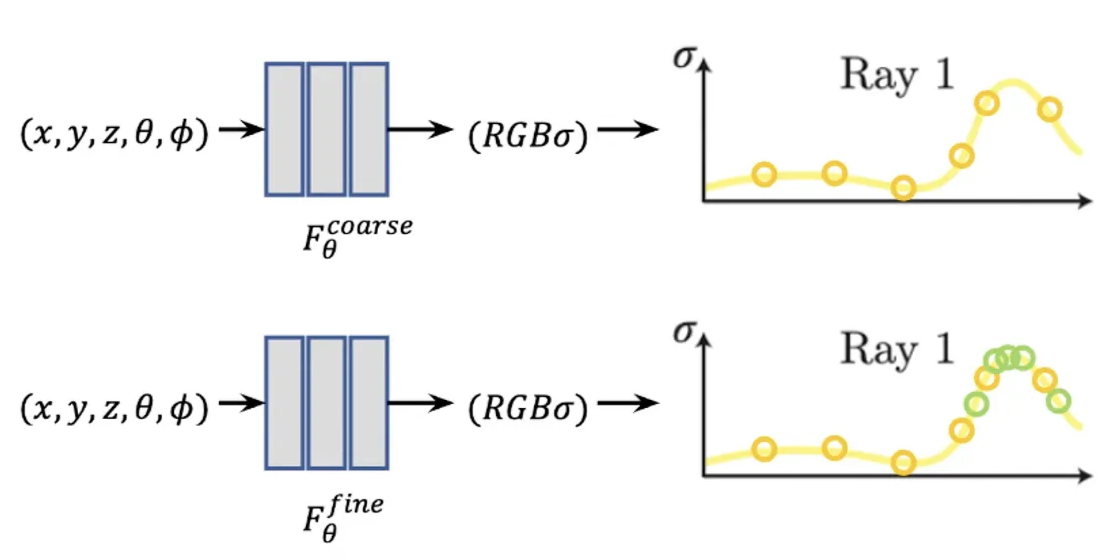
마찬가지로 high-frequency 정보를 표현하기 위해, ray를 sampling할 때 균등 간격으로 먼저 큰 특징을 샘플링하고, 밀도가 높은 구간을 다시한번 샘플링한다.
이를 위해 NeRF는 두 개의 네트워크를 사용한다:
- Coarse Network
- ray를 따라 개의 샘플을 뽑아 색상과 밀도를 예측.
- 균등(Stratified) 샘플링
- Fine Network
- Coarse Network의 결과를 활용하여 중요한 영역을 추가 샘플링
- 개의 추가 샘플을 Coarse network에서 계산한 밀도 값을 기반으로 더 중요한 영역을 집중적으로 샘플링
- 불균등 샘플링


ablation study에서 Positional Encoding, Hierarchical Volume Sampling이 효과적으로 모델 성능을 올려주고 있음을 제시하고 있다.
Loss Function
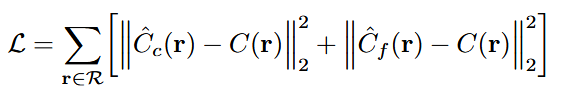
최종적으로, Loss는 모든 ray에 대해 Corse 네트워크 출력의 MSE Loss와 Fine 네트워크 출력의 MSE Loss를 합산하여 구해진다.
Limitation
- Dynamic Scene에서 적용 불가하다.
- Generalizable하지 않다.
- 속도가 느려 real-time inference가 불가능하다.
- 여러 application에 번거로움이 있다. implicit한 표현 방식은 다른 분야에 접목시키기 위해서는 추가적인 단계를 거쳐야 함을 의미한다.
