[NLP/논문리뷰] LSTM&GRU: Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Paper Review
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Motivation
- Vanila RNN의 문제점 : Gradient vanishing이 발생하여 long-term dependencies를 학습하는 것이 어렵다는 문제가 존재한다. 이는 gradient 기반 최적화 방법을 어렵게 만든다.
- LSTM이 성공적으로 도입되었으나, 복잡도가 높아 계산 효율이 떨어진다는 문제점이 있어왔다. 이에 따라 GRU라는 더 단순한 구조의 유닛이 제안되었고, 기존 연구들에서 LSTM과 유사한 정도의 성능을 보인다는 결과가 존재했다. LSTM과 GRU의 비교는 단편적인 task에 대해서는 이루어졌지만, 더 일반적인 영역에서 LSTM의LSTM과 GRU의 체계적이고 실증적인 비교 실험은 이뤄지지 않았다.
Contribution & Limitation
- 바닐라 RNN과 LSTM, GRU에 대한 sequencial한 speech & sound에서의 성능 비교가 이루어졌다. 다양한 데이터셋을 활용하여 일반적인 성능 평가를 수행하였다.
- 그러나 GRU와 LSTM중 어느 것이 더 우수한지는 데이터셋과 수행하는 task에 따라 차이를 보였고, 따라서 결론을 내릴 수 없었다. 또한 게이팅 유닛의 구성 요소가 어떻게 학습에 기여하는지에 대한 추가적인 실험이 앞으로 요구되었다.
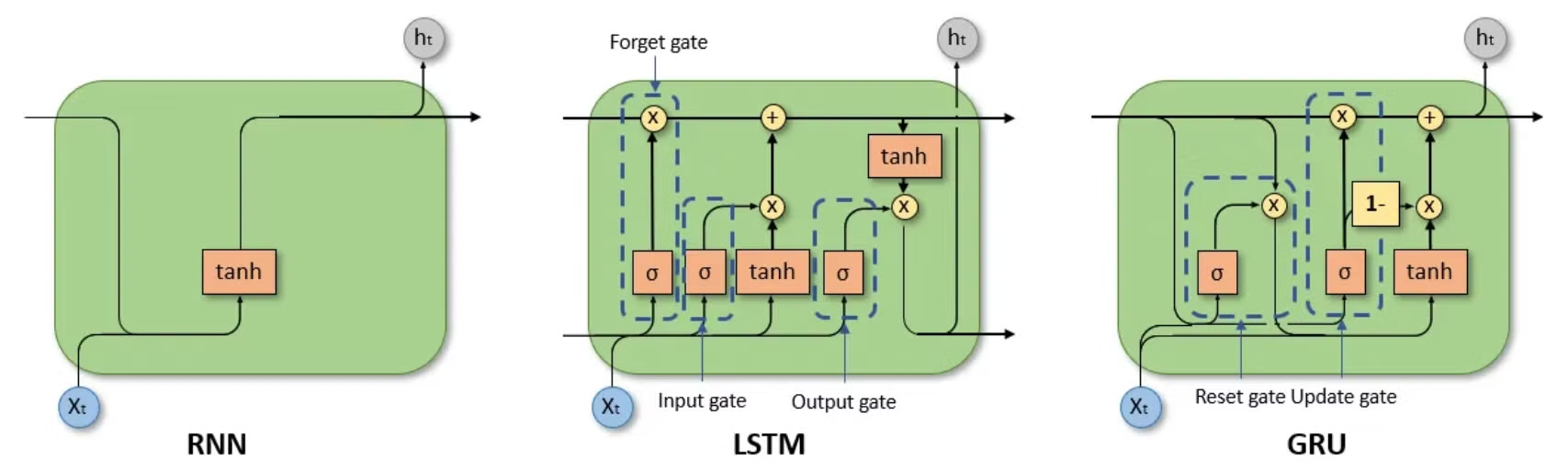
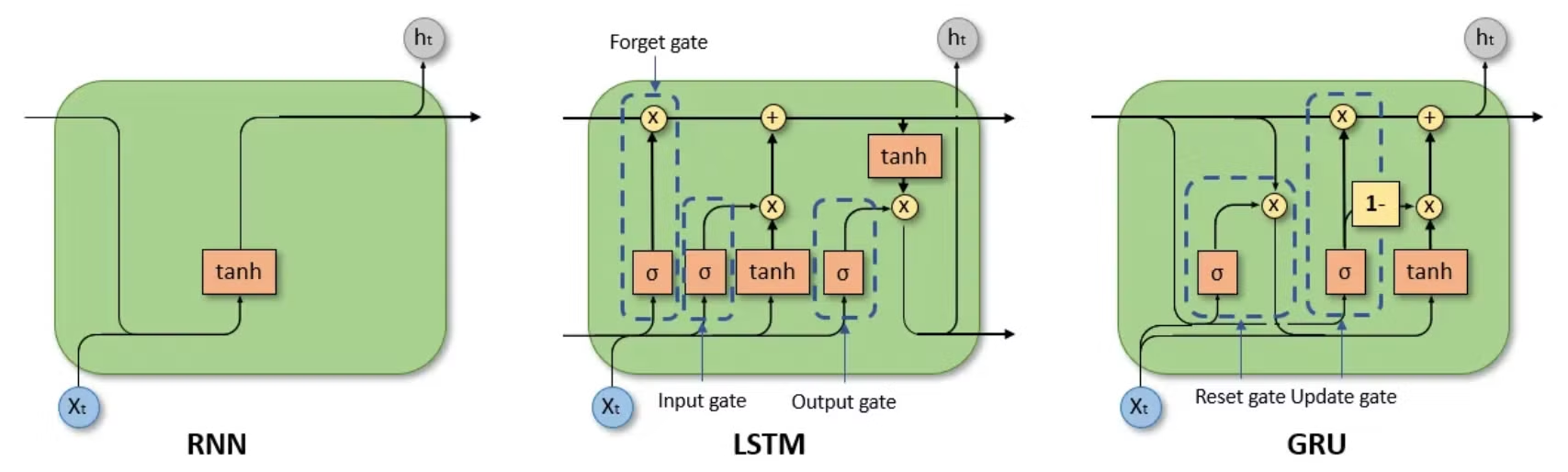
LSTM & GRU
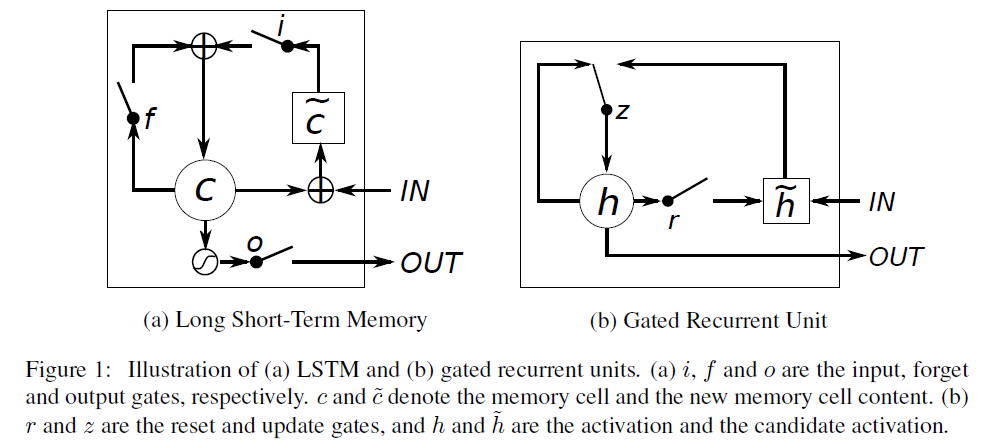
논문에서 활용된 Figure 1이 더 직관적으로 표현된 이미지
Vanila RNN
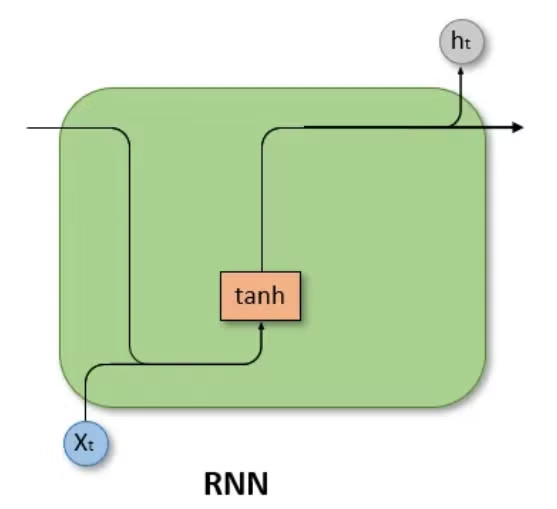
- Gating Unit이 없다.
- tanh activation function을 활용.
- 과 를 인풋으로받고, 지금의 시점 t에 대한 새로운 hidden unit 를 아웃풋으로 배출한다.
- 기본 구조는 다음과 같다. 이 때 는 non-linear한 function이다:

- hidden state의 업데이트가 이뤄지는 부분을 더 구체적으로 살펴보자면 다음과 같다:
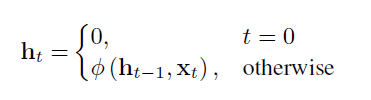
이때 보통 그림과 같은 tanh 함수가 활성화 함수 g로 활용된다.
LSTM
 |  |
|---|
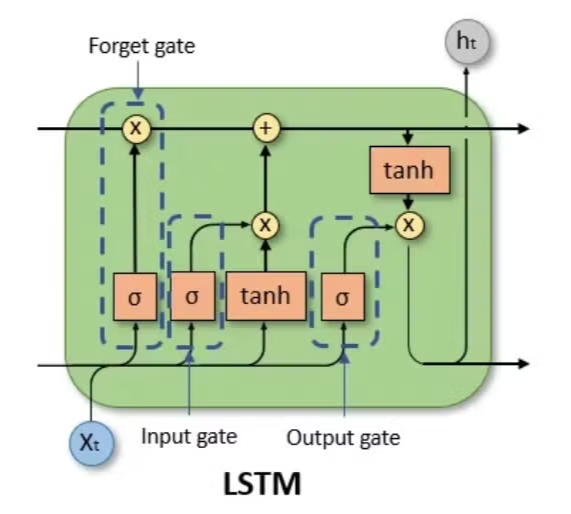
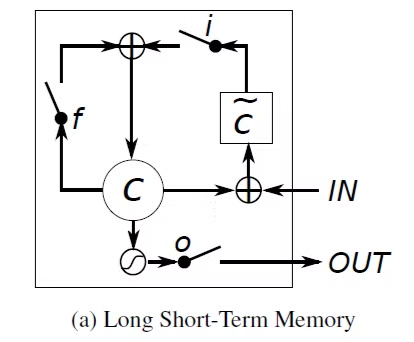
LSTM은 기본적으로 세 개의 Gate인 input gate, output gate, 그리고 forget gate와 메모리 셀인 Cell state로 구성된다.
-
먼저 인풋으로 와 를 입력받고, 이는 forget gate를 통과하며 Cell state 의 정보를 얼마나 유지할지가 결정된다.
-
1) 인풋으로 들어온 의 정보가 input gate를 통과하며 새로운 정보가 얼마나 메모리에 추가될지 결정된다.
2) 인풋은 동시에 tanh를 통과하며 새로운 후보(candidate) 가 생성된다.
-
forget gate를 통과한 값과 input gate를 통과한 값이 더해져 가 업데이트된다.
-
이는 다시 tanh를 거쳐 output gate를 통과하며 가 업데이트된다
- 이 때 gate들은 정보를 얼마나 버리고 또 사용할지를 결정하는 역할을 하면서 sigmoid 함수가 활용된다. 각각의 게이트에 대한 수식은 다음과 같다:
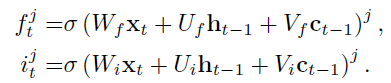
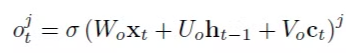
- tanh 함수는 가 output으로 나올 때 에서 한번, 를 생성할 때 한번 사용된다:
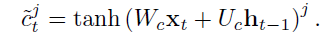
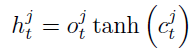
- 의 수식은 다음과 같다:
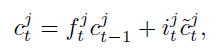
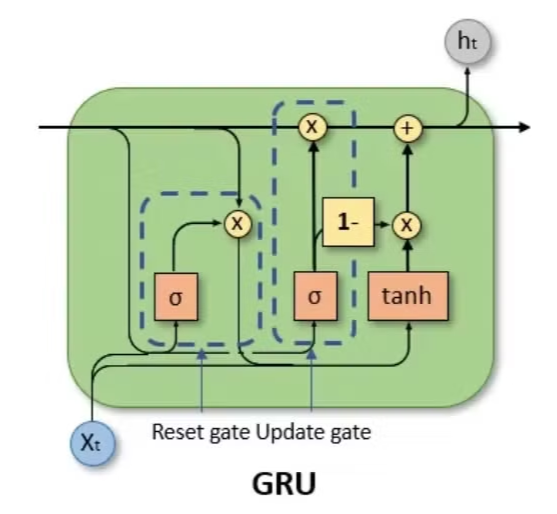
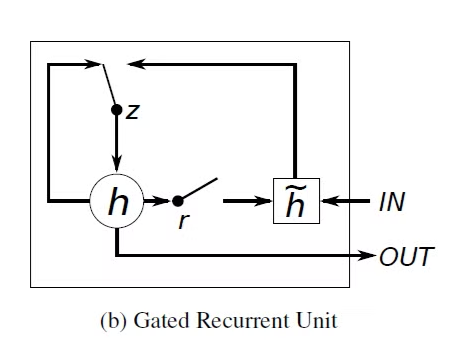
GRU
 |  |
|---|
GRU는 더 간소화된 방식으로, reset gate, update gate 두개의 gate를 가진다. reset gate에서는 이전 상태의 무시 정도가 결정된다는 점에서 forget gate와 유사한 역할을 수행한다. update gate는 새로 계산된 ht와 이전 h{t-1} 사이에서 얼마나 업데이트를 진행할지를 결정한다.
- 먼저 인풋이 reset gate 를 통과하며 이 얼마나 무시될지 결정된다.
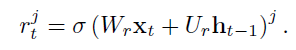
- reset gate를 통과한 정보는 tanh를 통과하여 인풋과 함께 candidate 를 생성한다.
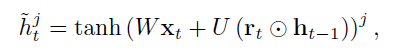
- 인풋이 update gate 를 통과하하여 를 업데이트할 정도를 결정한다.
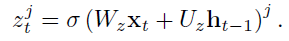
- 위 두 게이트를 통과한 값이 더해져 새로운 가 계산된다.
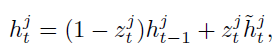
Comparison between LSTM and GRU
- 유사점
- additive update 새로운 입력에 따라 을 완전 대체하는 vanila RNN과 달리, LSTM과 GRU는 모두 이전 상태와 새로운 정보를 결합하는 방식으로 update가 이뤄진다. ⇒ Gradient vanishing 문제 완화
- additive update 새로운 입력에 따라 을 완전 대체하는 vanila RNN과 달리, LSTM과 GRU는 모두 이전 상태와 새로운 정보를 결합하는 방식으로 update가 이뤄진다. ⇒ Gradient vanishing 문제 완화
- 차이점
- LSTM은 output gate를 활용해 memory content가 노출되는 정도를 조절할 수 있지만 GRU는 불가능하다. 이는 LSTM에서 현재 state를 더 세밀하게 조정할 수 있도록 해준다.
- LSTM의 input gate와 forget gate는 GRU에서 하나의 게이트로 간소화되고, 이는 정보 조절의 효율성을 높이는 효과가 있다.
Experiments and Result
Experiment Settings
- LSTM, GRU, tanh 유닛을 비슷한 파라미터 수에서 비교
- test set: 4개의 폴리포닉 음악 데이터 셋(Nottingham, JSB Chorales, MuseData, Piano-midi)와 Ubisoft에서 제공한 2개의 음성 신호 데이터 셋 활용
- Optimizer은 RMSProp 활용
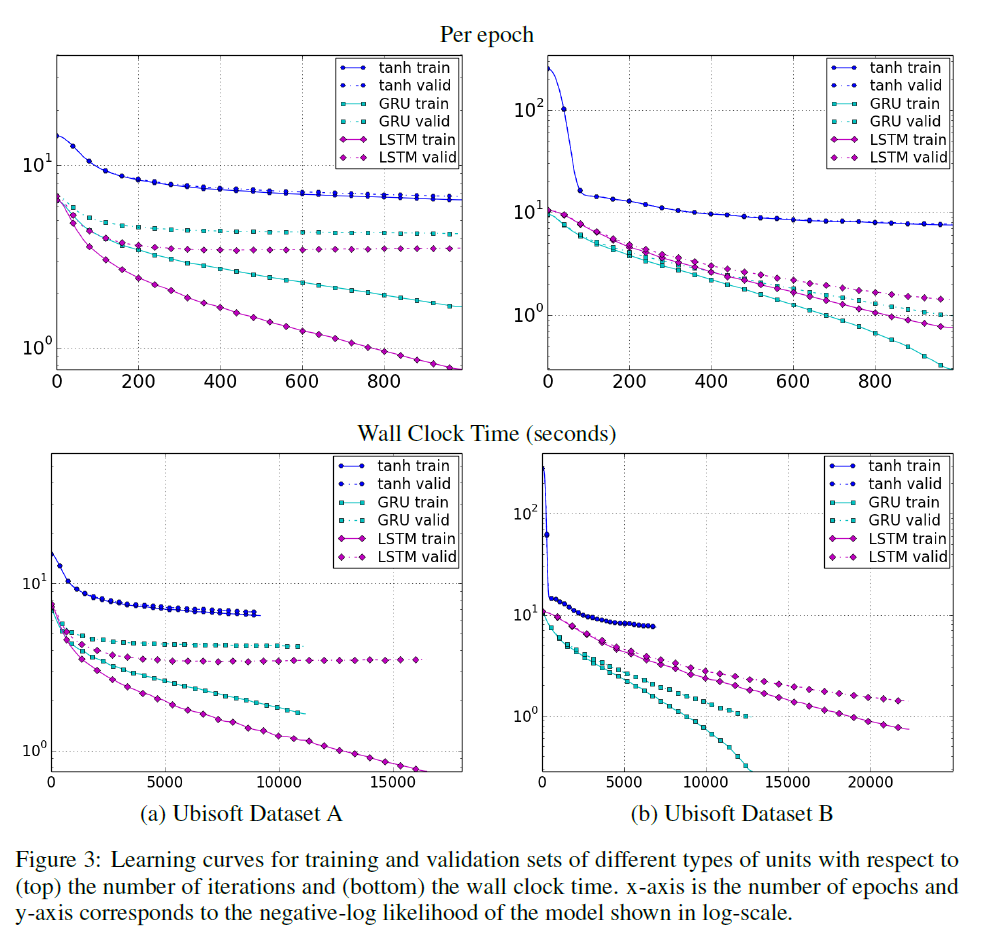
- 평가: 각 데이터셋에 대한 average negative log-probabilities를 확인하고 Wall Clock Time과 epoch에 따른 learning curve 확인
Results
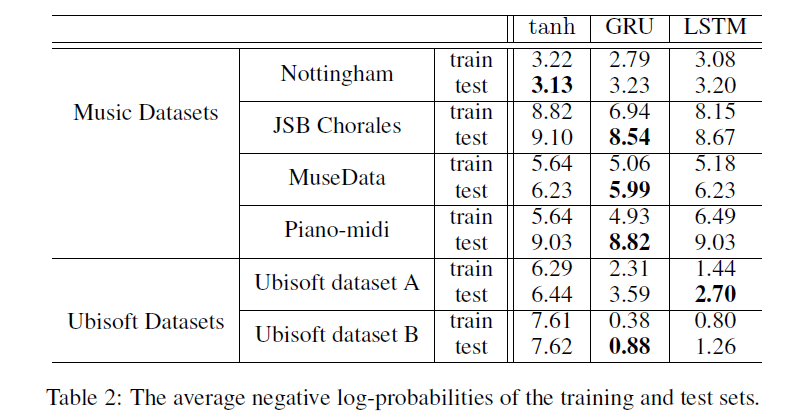
Nottingham 데이터셋에 대해서는 tanh유닛이 가장 높은 성능을 보였지만, 모든 모델이 유사한 정도의 성능을 보였음을 감안한다면 Music Dataset에서 GRU가 가장 높은 성능을 보였다. 반면 Ubisoft Dataset에서는 GRU, LSTM이 각각 한번씩 가장 좋은 성능을 보였다.
 |  |
|---|
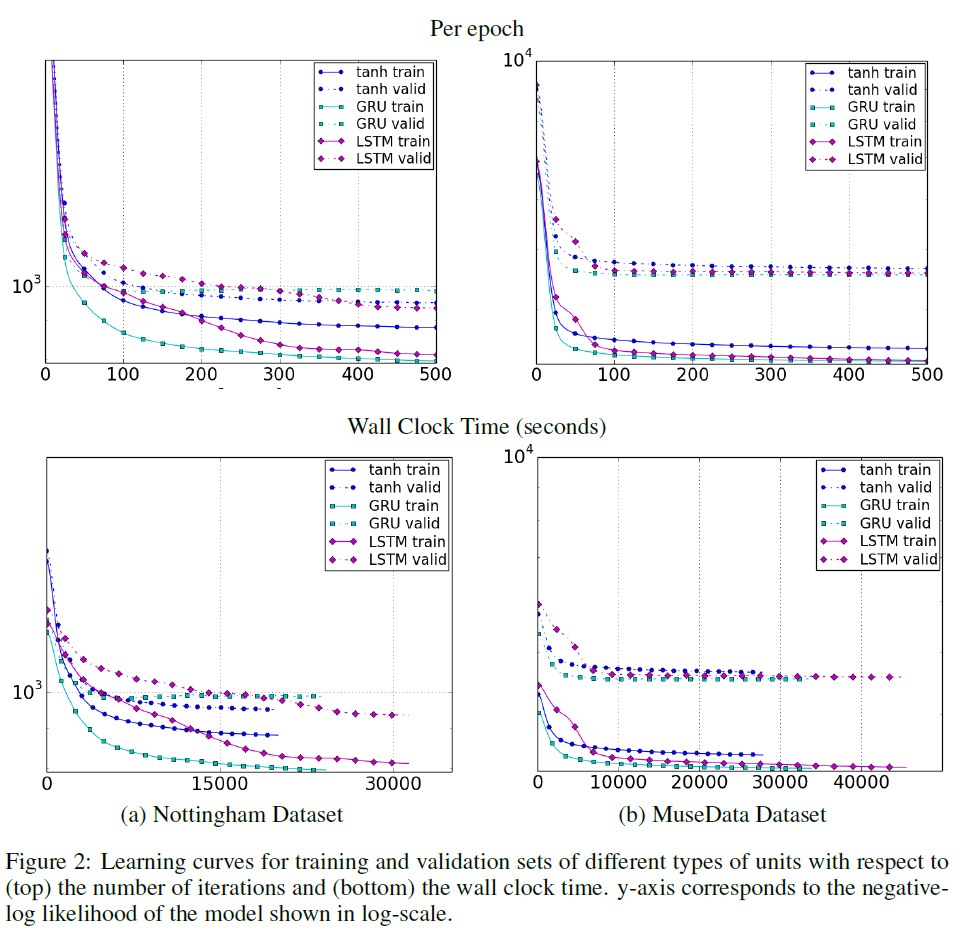
Learning Curve를 보았을 때에도 대체적으로 GRU가 가장 빠른 수렴속도와 성능을 보였다. LSTM도 GRU와 유사한 정도의 성능을 보였지만, tanh 유닛의 경우 Ubisoft 데이터셋에서 확인할 수 있듯 두 게이팅 유닛에 비해 낮은 성능을 보였다.
