Overview
- https://github.com/Ablustrund/LoRAMoE
- MoE 방식을 Lora로 진행
- SFT을 하게 되면 Downstream task의 성능은 증가 시키는 반면, global knowledge는 떨어지는데 이를 해결함
Introduction
-
SFT(Supervised Fine-tuning)는 LLM이 인간의 지시를 따르고 (alignment), 다양한 downstream task의 성능을 높이는 방법 중 하나
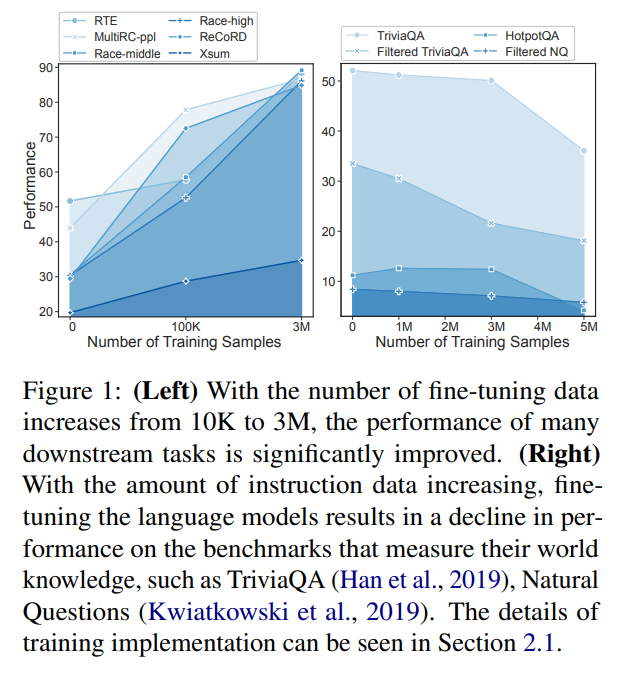
-
SFT을 할 때 training dataset이 많으면 많을 수록 대부분 downstream-task에 대한 성능을 증가 시킴, 그러나 이는 이미 LLM이 가지고 있는 world knowledge를 잊게 함
- 이는 instruction set 사용할 때 더 큼
- world knowledge -> closed QA 등 이미 LLM이 가지고 있는 사전지식 느낌
-
따라서 이 논문에서는 LoRAMoE라는 프레임워크 제안
- 모델이 world knowledge를 유지하면서도 donwstream task에서 높은 성능을 할 수 있도록
- Lora를 Expert로 두고, 이를 Router로 통합하는 식(MOE + Lora)
Method
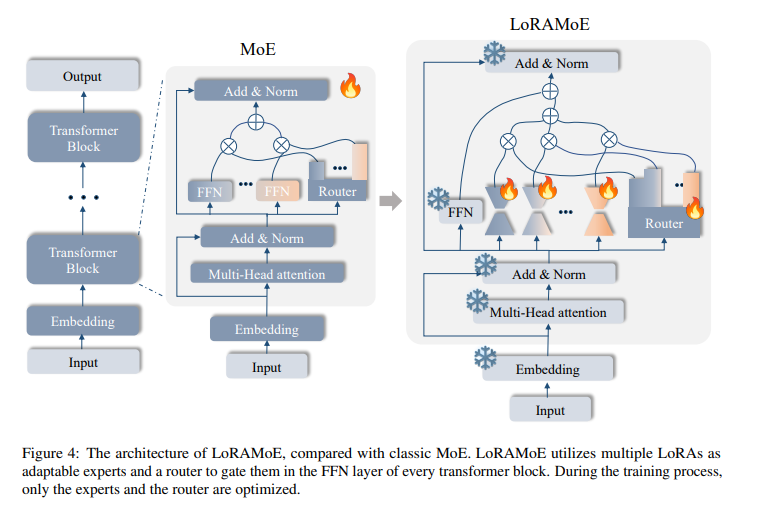
Architecture
- MoE방식인데 MoE block(FFN 중에 linear)가 LoRA로 나머지 기존 모델 weight는 freeze


Localized Balancing Constraint
-
아직 정확히 이해가 가지 않음...
-
Expert을 balance있게 사용하기 위한 기술로, 두가지로 Expert를 나눠서 유형의 작업에 집중할 수 있도록
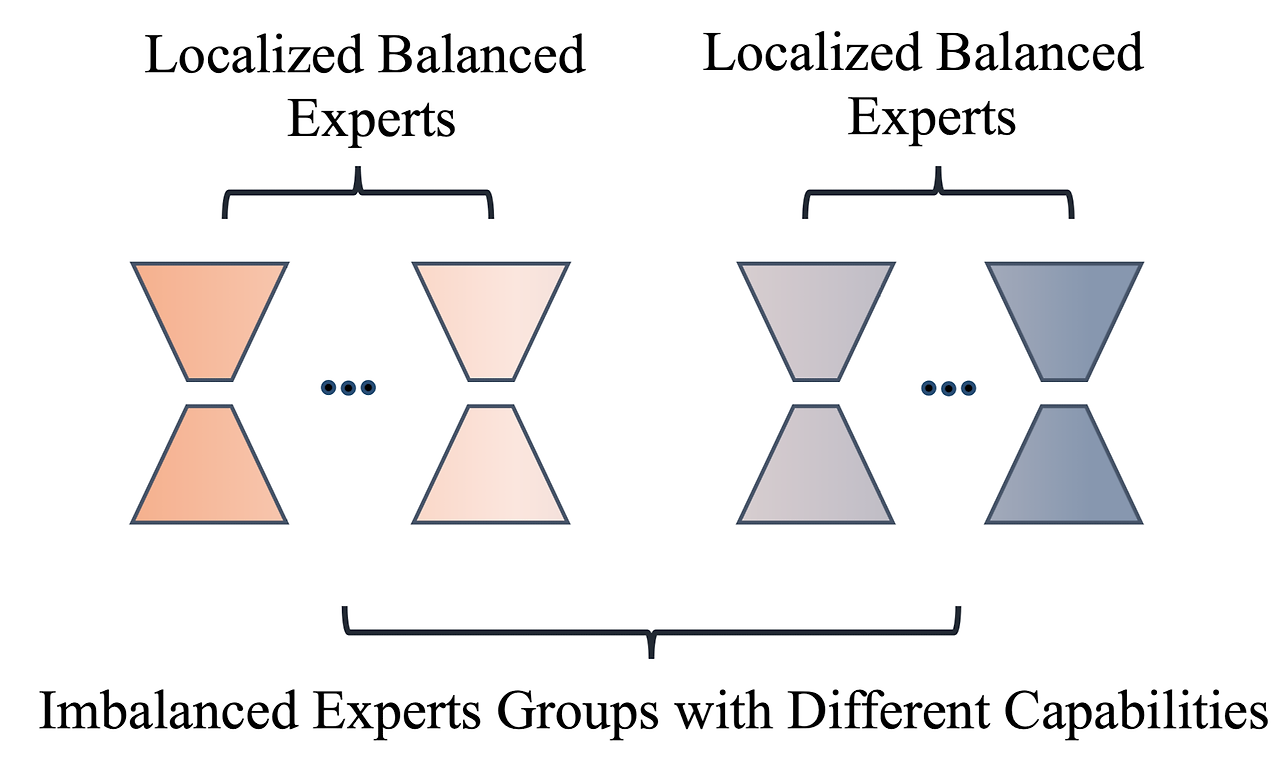
- world knowledge관련된 task에 집중
- 다른 downstream-task 에 집중
-
중요도 행렬의 평균과 분산을 활용해서 loss 계산
- 중요도 행렬: 각 Expert가 처리 과정에서 얼마정도 기여하는지 (활성화 정도 결정)
-
행렬을 통해서 training sample과 expert 사이의 상호 작용을 정량화해서 진행됨.
Experiment
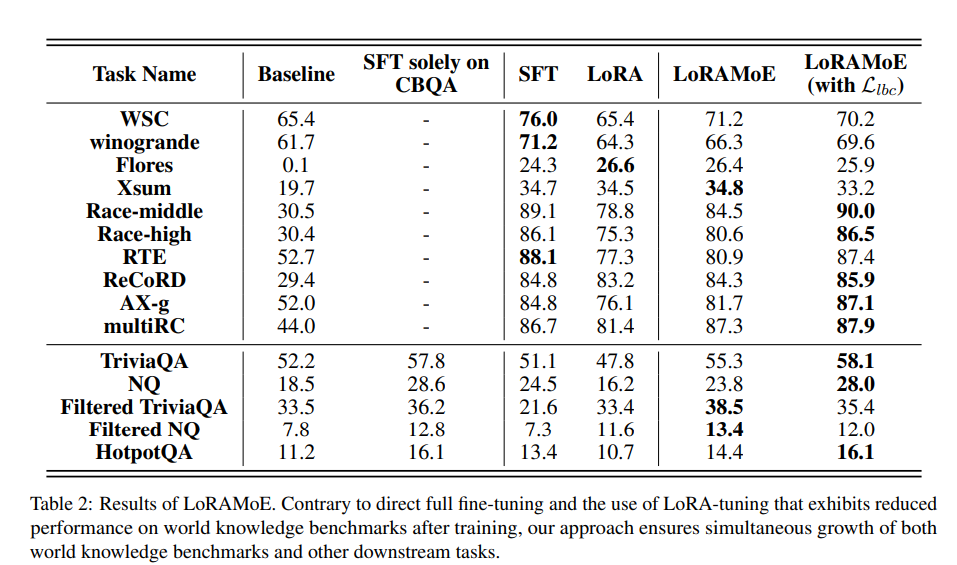
- SFT나 LoRA 튜닝 적용한 모델과 비교해 뛰어나거나 비슷한 성능
- World knowledge를 평가하는 benchmark에서는 LoraMoE을 사용한게 더 뛰어난 것을 알 수 있음
Discussion
- MoE를 Lora로 대체해 훈련하면 resource관점과 학습 난이도에서 더 좋을듯
- 논문에서도 언급하고 있지만 작은 모델로만 실험한게 아쉬움
- 그러나 오히려 작은 모델이기때문에 실험해보긴 편할듯
- Localized Balancing Constraint를 이해하기 위해 MoE와 matrix부분에 대해 공부가 더 필요할 듯 ㅜㅜ
