Overview
- 아이디어는 굉장히 간단함 데이터를 생성하고, 이 데이터를 활용해 7B모델 학습
- https://openlsr.org/sail-7b
Introduction
- LLM은 Zero-shot, few-shot ICL setting에서 성능이 좋음 또한 Instruction Tuning을 하면서 alignment가 되는 등 성능이 높아짐
- 그러나 큰 단점 존재, dataset을 모은 시점 이후부터 지식 사용 불가
- 이를 해결하기 위해 RAG 시스템 등장
- RAG: 검색 문서를 LLM에게 같이줘서 최신 지식/모르는 지식에도 대답할 수 있게
- 하지만 보통 상용 검색 시스템의 부정확성 / 검색 모델의 성능 등으로 인해 검색된 문서에는 잘못된것이 섞여 있을 수 있음
- 이때 다음 그림과 같이 LLM은 이를 구별하지 못하고 성능이 하락함

- 따라서 이 논문은 앞선 문제를 해결하기 위해서 search-augmented instruction learning(SAIL) model을 제안
- 트레이닝 셋 제작
- 훈련된 7B모델은 gpt-3.5 // 13B 모델보다 더 성능이 좋음
Method
Ssearch Result Collection
- 52k alpaca instruction dataset으로 사용
- 그 후 instruction과 query를 합쳐서 serach query로 사용
- 이 search query를 활용해 DuckDuckGo search API와 BM25 Wikipedia 검색
- 이 때 title과 preview 정도만 사용
- 그 후 3개 DuckDuckGo와 2개의 Bm25 결과를 가지고 랜덤하게 샘플링해서 사용
In-context Retrieval Selection
- search result에서 좋은 document에만 집중 하기 위해서 다음과 같은 Filtering을 거침 (LLM이)
“Search result (1) is informative and
search result (2) is distracting, so I will use the
information from the search result (1).” - 이 검색 결과중 어떤것이 Query와 연관되어 있는 지 판단하기 위해 NLI모델(Entailment classification) 도입
- entailment와 contradictory 스코어를 비교해서 활용
- 데이터와 inference 예시는 위의 그림 참고
FT(Fine-Tuning)
- 그 후 다음 prompt를 가지고 ChatGPT4의 답변을 생성 > 이를 활용해 FT를 진행

- 훈련 정보
- llama-7b
- 3 epoch
- batch 32, AdamW optimizer
Experiment
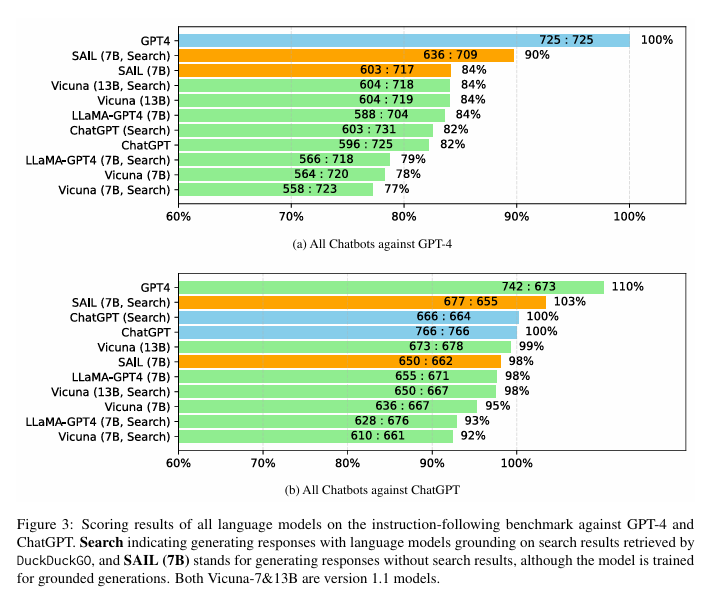
- ChatGPT4와 비교했을때도 괜찮은 성능을 보임
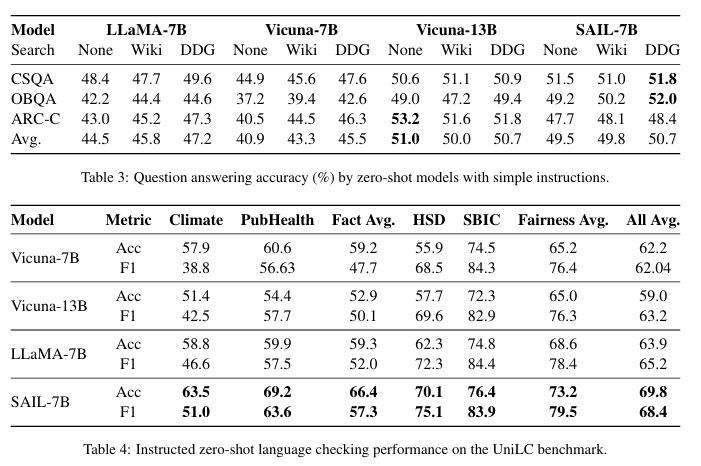
- Zero-shot setting에서도 성능이 좋음
Disscusion
- 요즘 논문들은 ChatGPT4로 데이터를 만드는 방법 등에 더 초점을 맞춰서 진행하고 있는 느낌...
- 이 논문도 다른 논문과 비슷하지만 중간에 CoT 느낌처럼 검색 문단을 필터링 하는 think step을 하나 더 한것만 다름
“Search result (1) is informative and
search result (2) is distracting, so I will use the
information from the search result (1).”
