이전 포스트에서 이어지는 포스트
책에서는 모두 정규화 파트에 작성하였지만, 굳이 따지자면 정규화는 아니지만 정규화 효과를 볼 수 있는 기법들이라 나누었습니다.
참고 자료
윤성진, [Do it! 딥러닝 교과서], 이지스퍼블리싱(2021), 185p ~ 201p
1. 조기 종료(Early Stopping)
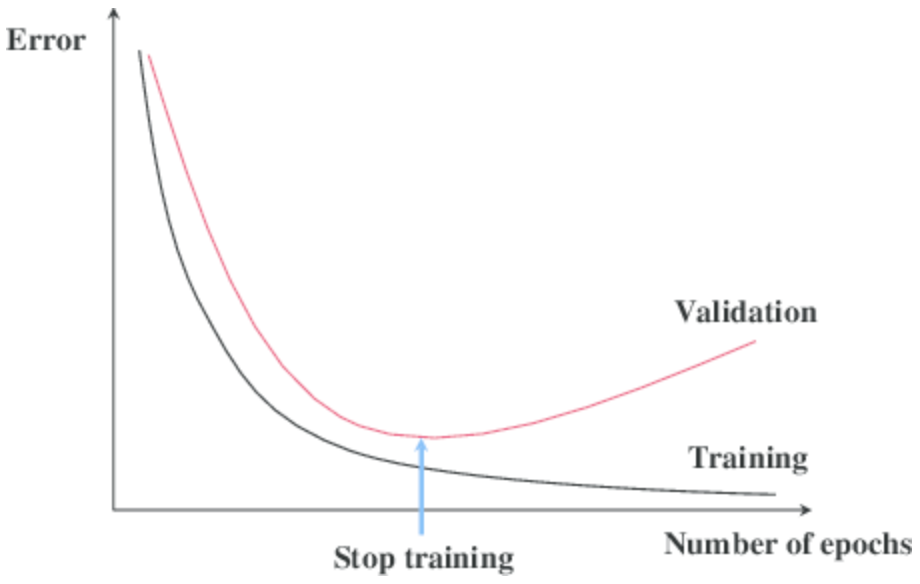
모델이 과적합되기 전에 훈련을 멈추는 기법
1.1 종료 기준
학습할 때 단계마다 미니배치로 근사한 gradient는 실제와 차이가 있으므로 성능이 조금씩 좋아졌다 나빠졌다 할 수 있다. 일시적인 변동이 아닌, 지속적인 성능의 정체 또는 하락이 판단될 때 종료하는 것이 바람직하다.
1.2 정규화 효과
초기 파라미터 위치가 이고 최적화 스텝 수가 , 학습률이 라면 파라미터 공간이 을 중심으로 크기의 반경을 갖는 공간으로 제약된다.
이러한 형태로 공간의 크기가 제약되면 정규화와 동일한 효과가 있다.
2. 데이터 증강(Data Augmentation)
모델은 복잡한데 그만큼 충분한 훈련 데이터가 제공되지 않으면 모델이 데이터를 암기해서 과적합이 생긴다.
현실적으로 데이터 레이블을 만드는 비용이 만만치 않다. 따라서, 수집해서 큰 데이터셋을 만드는 방법보다 훈련 데이터셋을 이용해서 새로운 데이터셋을 생성하는 기법을 사용하는데 데이터 증강기법이라고 한다.
2.1 데이터 증강 기법
훈련 데이터를 조금씩 변형해서 새로운 데이터를 만드는 방법이다. 사람이 규칙을 정할 경우에는 성능에 최적인지 검증이 필요하다. 고도화된 방법으로는 분포를 학습해서 생성 모델을 만든 뒤 새로운 데이터를 생성하는 방법이 있다.
2.2 클래스 불변 가정(class-invariance assumption)
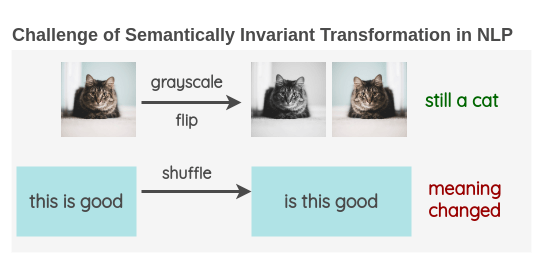
데이터 증강을 할 때는 클래스 불변 가정을 따라야 한다.
=> 데이터 증강할 때 클래스가 바뀌지 않도록 해야 한다는 가정이다.
아래 그림과 같이 문장의 경우에는 단어의 도치로 인해 의미가 달라질 수 있다.
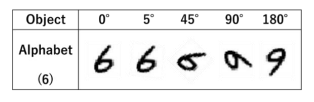
숫자의 경우에도 회전으로 인해 숫자 6과 9의 클래스의 경계가 애매해지는 경우가 있으므로 주의해야 한다.
2.3 데이터 증강 방식 선택
데이터를 증강하는 방ㅇ식은 매우 다양하다.
이미지의 경우에는 이미지 이동, 회전, 늘리기, 대칭, 모자이크, 배경합성, 색 변환, 잘라내기 등등 다양한 변형 방법을 사용할 수 있다.
텍스트의 경우에도 비슷한데
Wei et al. "EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks" EMNLP. 2019 해당 논문에서 기법들이 정리되어 있으므로 참고하면 좋을듯 하다.
이외에도 강화 학습이나 진화 알고리즘 등으로 학습해서 자동으로 생성하기도 한다.
3. 배깅(bagging)
앙상블(ensemble)은 여러 모델을 실행해서 하나의 강한 모델을 만드는 방법이다. 배깅(bagging)도 이러한 앙상블 기법 중의 하나로 독립된 여러 모델을 동시에 실행한 뒤 개별 모델의 예측을 이용해서 최종으로 예측하는 방법이다.
3.1 배깅의 원리
모델의 독립성 보장을 위해 훈련데이터를 부트스트랩으로 추출 후 학습한다. 그 후 개별 모델의 결과를 집계해서 결론을 예측한다.
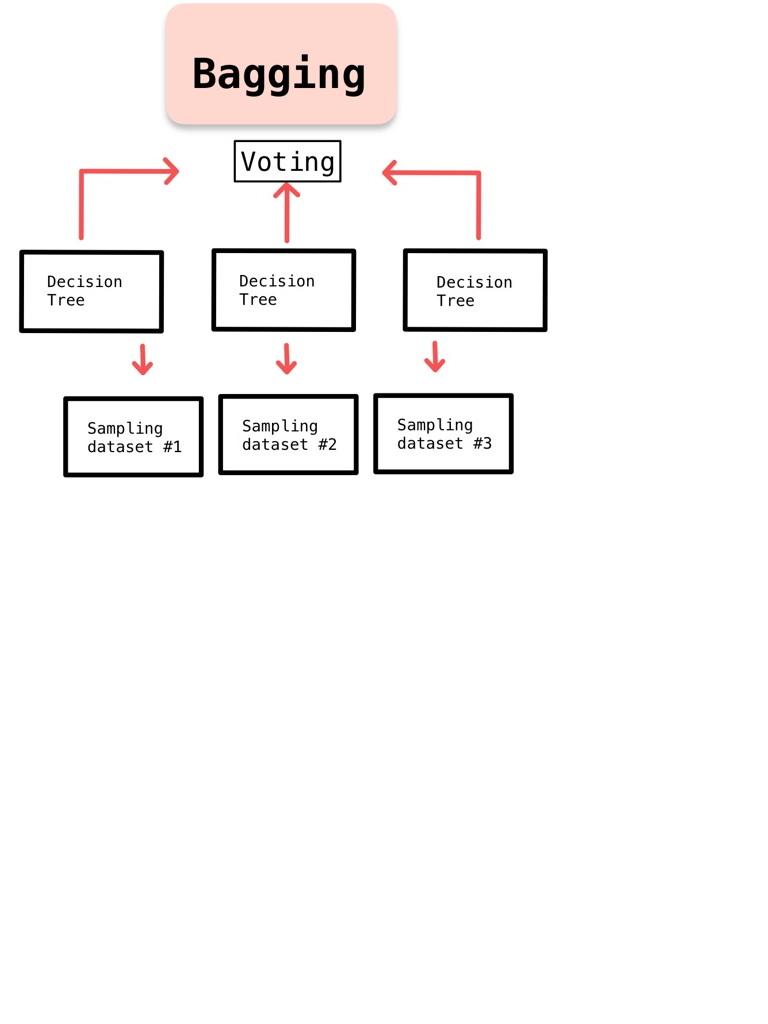
3.2 신경망 모델의 경우
신경망 모델의 경우에는 부트스트랩을 사용하지 않아도 된다. 모델의 가중치를 랜덤하게 초기화하는 만큼 마치 다른 모델인 것과 같은 효과가 생기고, 미니배치 방식을 사용함으로써 모델별로 다른 훈련 데이터셋을 사용하는 효과가 있기 때문이다.
3.3 배깅의 정규화 효과
k개의 회귀 모델로 배깅한다고 가정. 개별 회귀 모델의 예측 오차 는 평균이 0이고 분산이 v이며 모델 간의 공분산이 c인 가우시안 분포를 따른다.
모델이 서로 독립인 경우 공분산이 0인 경우라
* 식은 추후에 정리..
와 같이 모델 수에 비례해서 줄어들게 된다.
4. 잡음 주입(Noise Injection)
데이터나 모델을 확률적으로 정의할 수 있다면 더 정확하게 추론할 수 있다. 그렇지 않다면, 간단히 잡음(noise)을 넣어서 확률적 성질을 부여할 수 있다.
4.1 잡음 주입 방식
확률적 성질을 부여하고 싶은 대상에 따라 잡음을 주입하는 형태도 다양하다.
-
입력 데이터에 잡음 주입
- 데이터 증강 기법에 해당한다. 아주 작은 분산을 갖는 잡음을 넣으면 가중치 감소와 동일한 효과를 볼 수 있다.
-
특징에 잡음 주입
- 데이터가 추상화된 상태에서 데이터 증강을 하는 것으로 간주할 수 있다. 객체와 같은 상대적으로 의미 있는 단위로 데이터 증강이 일어나서 성능이 향상한다.
-
모델 가중치에 잡음 주입
- 대표적인 경우가 드롭아웃이다. 뉴ㅠ런을 제거할 때 확률적으로 가중치를 조절하기 때문에 가중치에 잡음을 넣는 것이다.
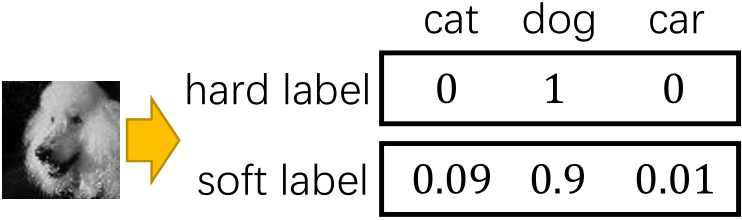
4.2 소프트 레이블링
모델이 훈련 데이터에 과도하게 적합하거나, 불확실성을 고려하지 않고 강한 예측을 내리는 경우에 overconfidence 문제가 발생할 수 있다. 이는 모델의 일반화 능력을 저하시킬 수 있으며, 올바른 예측을 위해 불확실성을 고려하는 것이 중요하다.
그렇기 때문에, 훈련 데이터에 mislabeling이 포함된(그럴 가능성이 있는) 경우, 레이블에 일정한 크기의 오차를 반영해주면 더 정확하게 예측할 수 있다.