RNN(Recurrent Neural Network)
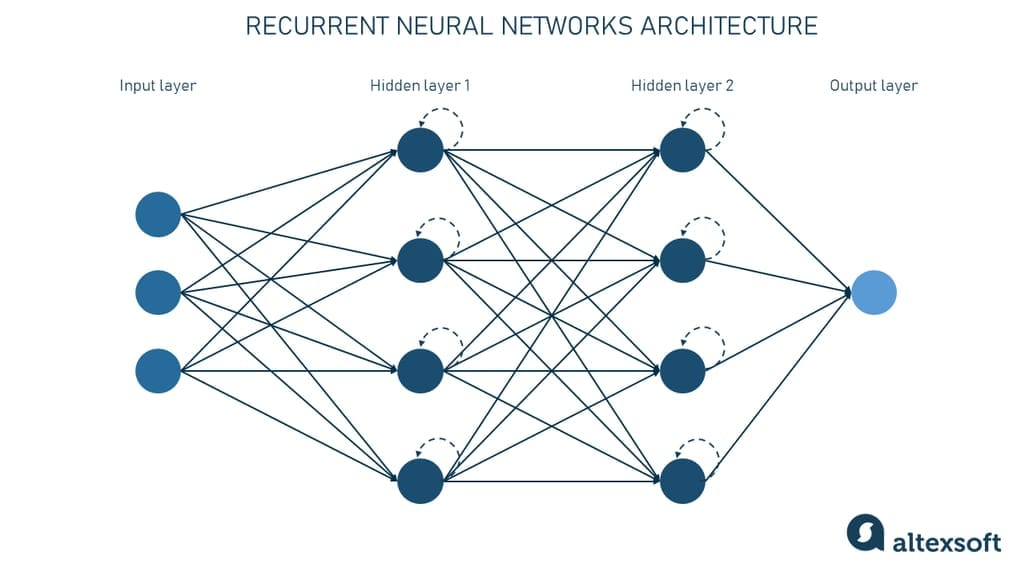
RNN은 이전의 전통적인 인공신경망이 입력과 출력이 모두 서로 독립적인 관계인 것과 반대로 이전의 정보들을 모두 기억하고 계속 계산해 나가면서 예측을 하는 것입니다.
Hidden state는 hidden layer에 의해 유지됩니다.
레이어를 거칠때마다 이전의 정보들을 계속 누적해서 학습 , 또 누적해서 학습 이런 식으로 진행도기 때문에 메모리가 비효율적으로 사용되고 출력층과 먼 정보는 없어질 수 있습니다.
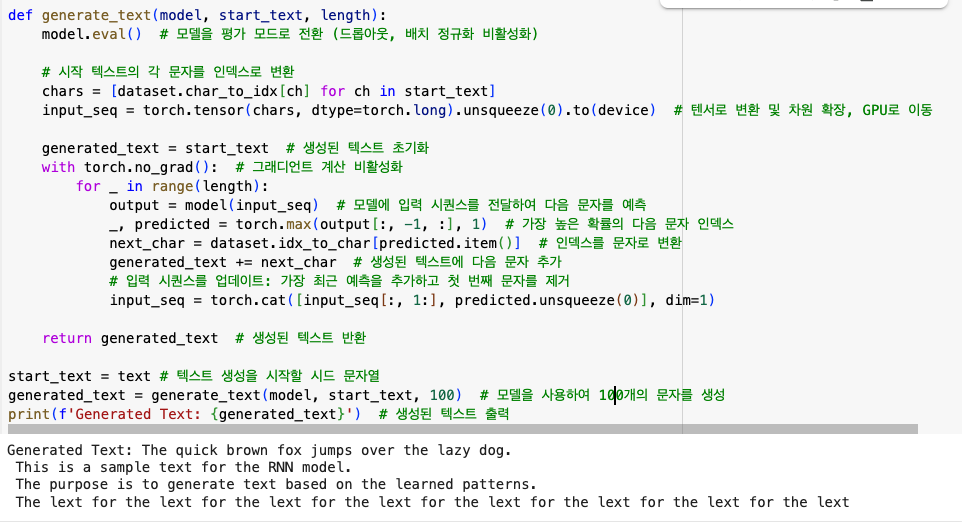
📌 100 개의 문자를 생성하도록 인자 값을 넣고 generate_text()를 호출하였지만 20개를 채 넘기지 못하고 계속 반복되는 현상이 있었습니다.
이는 RNN델이 장기적인 패턴을 학습하는 데 어려울을 겪을 때 나타나는 현상입니다.
🧐 원인
1. 장기 의존성 문제
과거의 정보를 활용하여 다음 출력을 생성하는 모델이기는 하지만, 너무 오래된 정보는 기울기 소실로 인해 잘 잊어버리게 됩니다. 따라서 그 패턴을 계속해서 반복하는 경향이 있습니다.
✨ LSTM,GRU 같은 개선된 아키텍처를 사용하여 완화시킬 수 있습니다.
2. 학습 데이터가 부족하거나 편향됨 / 손실 함수가 너무 작은 값에서 수렴
학습 데이터가 짧거나 편향되어 있으면 모델이 특정한 반복 패턴을 쉽게 학습할 수 있습니다.
✨ 학습 데이터셋을 다양하게, 많이 구성하여 특정 문장이 반복되지 않도록 하고, epoch를 증가시켜 충분히 학습시킵니다.(+Dropout을 적용하여 모델이 특정 패턴만 과적합하지 않도록 방지합니다.)
3. 샘플링 방식의 문제
샘플링 방법이 잘못 설정되면, 특정 단어나 패턴이 과도하게 반복될 수 있습니다.
4. 임베딩 차원의 한계
임베딩(Embedding) 레이어의 크기가 너무 작으면 모델이 충분한 표현력을 갖기 어려워 특정 패턴을 반복할 가능성이 커집니다.
✨ embedding_dim을 늘려 모델이 더 풍부한 표현을 학습할 수 있도록 함.
✅ 따라서 최적의 해결 방법은
- LSTM 또는 GRU 모델로 변경하여 장기 의존성 문제 해결
- Temperature 값 조정 및 Top-k, Top-p 샘플링 적용
- 학습 데이터 다양화 및 학습 에포크 증가
- 임베딩 차원 증가
- Dropout 적용하여 과적합 방지
⚠️따라서 개선하기 위해 LSTM 모델로 변강하고 에포크를 100으로 증가시켰습니다.
LSTM(Long-Term Short Term Models)
RNN의 기울기 소실 문제를 보완하여 나온 모델입니다. RNN의 Hidden State에 Cell State를 추가한 구조이며, 일종의 컨베이어 벨트 역할을 하기 때문에 state가 꽤 오래 경과하더라도 그래디언트가 비교적 전파가 잘 됩니다.(input, forget, output gate layer )

그랬더니 아직도 완벽하지는 않지만 훨씬 더 안정적인 출력을 해냈습니다.
