Title
UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition (EMNLP 2022)
Abstract
- Multimodal sentiment analysis (MSA)
- Emotion recognition in conversation (ERC)
- Most existing works study sentiment and emotion seperately
=> Multimodal sentiment knowledge-sharing framework (UniMSE) that unifies MSA and ERC.
- Modality fusion + contrastive learning between modalities
- SOTA on MOSI, MOSEI, MELD, IEMOCAP
1. Introduction
- Multimodal data => verbal(textual feature) + acoustic(prosody, rhythm, pitch) + visual (face)
MSE and ERC
- MSA - Predict sentiment intensity or polarity (longer periods)
- ERC - Predict predefined emotion categories (short periods)
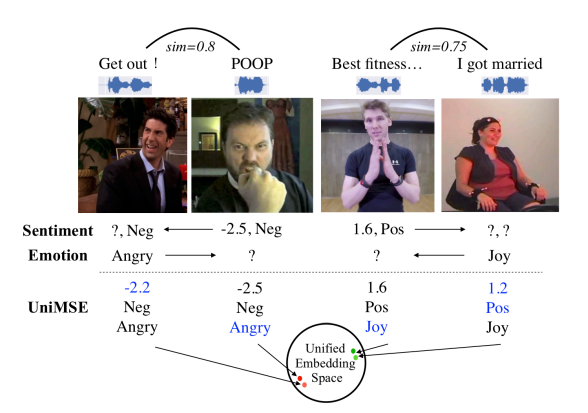
=> sentiments and emotions are relevant, and could be projected into a unified embedding space.
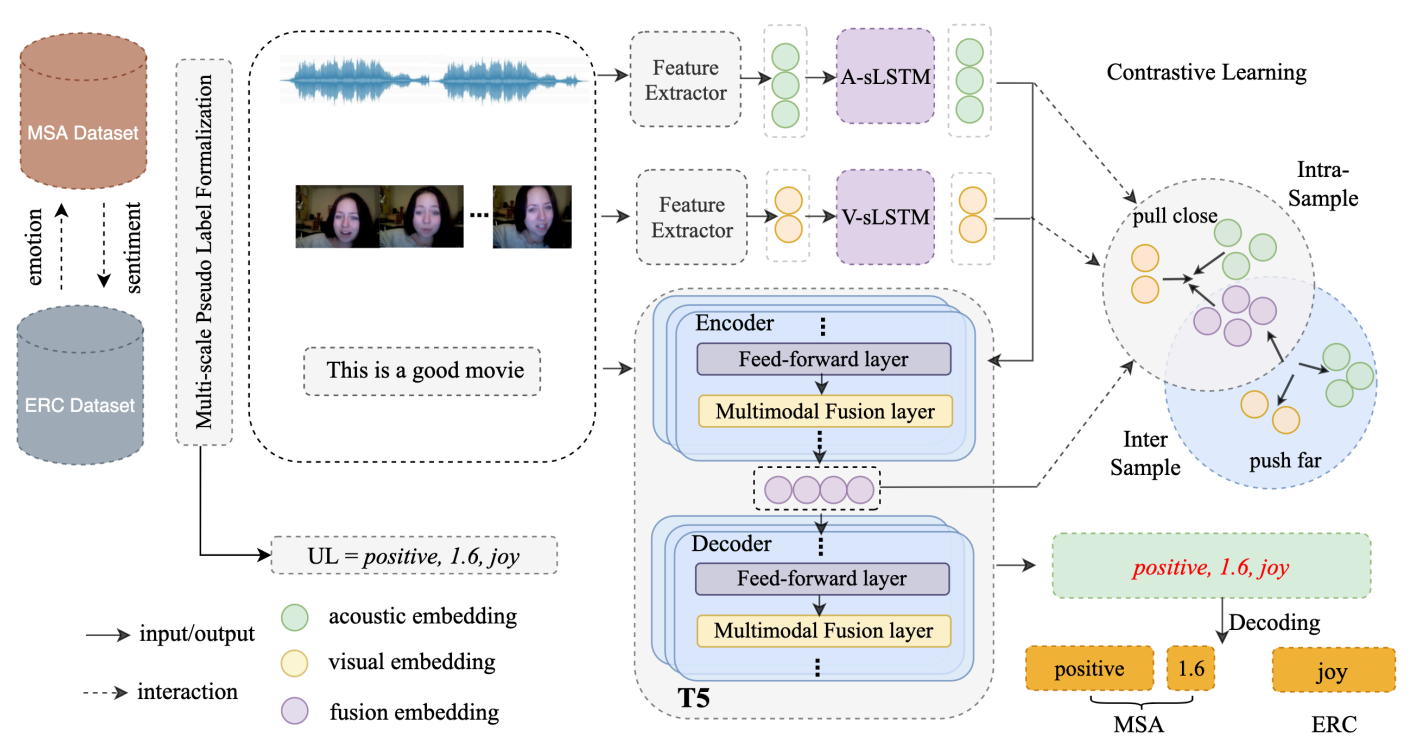
UniMSE (Unified MSA and ERC)
- MSA & ERC labels => Universal Labels (UL)
- Pre-trained modality fusion layer (PMF)
- Embed PMF to T5, fusing acoustic and visual information with different level textual features
- Inter-modal contrastive learning (CL) => minimize intra-class variance and maximize inter-class variance across modailities.
Contribution (summarized)
- UniMSE that unifies MSA and ERC tasks
- Fuse multimodal representation from multi-level textual information
( Injecting A & V signals into the T5 model.) - SOTA on public benchmark datasets (MOSI, MOSEI, MELD, IEMOCAP)
- First to solve MSA and ERC generatively + first to used unified A & V across MSA and ERC
2. Related Works
Multimodal Sentiment Analysis (MSA)
Emotion Recognition in Conversations (ERC)
Unified Framework
3. Method
3.1 Overall Architecture
Task formalization
- Process MSA & ERC labels into universal label (UL) format (offline)
Pre-trained Modality Fusion
- Unified feature extractors among datasets => Audio and Video features
- 2 individual LSTM for long-term contextual information
- T5 as encoder for texual modality.
- Embed multimodal fusion layers into T5
- Follows FFN in some layers in T5
Inter-modal contrastive learning
- Differentiate the multimodal fusion representations among samples
- Narrow the gap between modalities of the same sample and push the modality representations of different samples further apart.
3.2 Task Formalization
- Multimodal signal (Video fragment & denote text, acoustic, visual)
- MSA -> predict sentiment strength
- ERC -> predict emotion category of each utterence
- Formalize with input formalization and label formalization step
3.2.1 Input formalization
- Concatenate current utterance with 2 former and 2 latter ones
- - Segment ID
- Raw acoustic input -> librosa => extract Mel-spectogram as audio features
- Video -> extract T frames from each segment -> efficientNet(pretrained on VGGface and AFEW dataset) -> video features
3.2.2 Label Formalization
- Universal label
- : sentiment polarity (positive, negative, neutral)
- : sentiment intensity (real number in [-3, 3])
- : emotion category
Alignment of label space
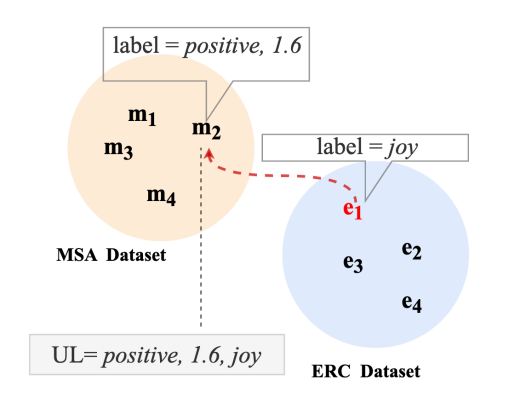
- Classify samples of MSA and ERC into positive, neutral, and negative sample according to their sentiment polarity
- Calculate the similarity of 2 sampels with same sentiment polarity but belonging to different annotation scheme.
- Similarity -> textual similarity with SimCSE(sentence embedding framework)
- Since previous works demonstrated textual modality is more indicative than the other modalities. - Evaluate performance of generated labels => manual evaluation, accuracy about 90%.
3.3 Pre-trained Modality Fusion (PMF)
- Embedding multimodal fusion layers into the pre-trained model.
- Acoustic and visual signals used with multiple levels of textual information.
- PMF unit in the Transformer layer of T5 receives a triplet -> maps multimodal concatenation back to layer's input size.
- Multimodal fusion for -th PMF
- : hidden states of last time step of A-LSTM
- : hidden states of last time step of V-LSTM
Solution regarding two shortcomings of fusion
- Can disturb the encoding of text sequence
- Cause overfitting as more parameters are set for the multimodall fusion layer
=> Solution: Use former Transformer layers to encode text and inject non-verbal signals to the remaining layers.
3.4 Inter-modality Contrastive Learning
Contrastive Learning (CL)
- Gained advances in representation learning by viewing sample from multiple views.
- Anchor <-pulls-> positive samples & Anchor <-pushed-> negative samples
Intermodality contrastive learning
- Process each modal represantation to the same sequence length
- : obtained after Transformer layers
- is convolutional kernel for modalities- Mini-batch with samples
- Text modality as anchor, and other two modalities as its augmented version
Contrastive learning process
- Each batch consists of two positive pairs and negative pairs
- Positive: Text + corresponding acoustic, Text + corresponding visual
- Self-supervised Constrastive loss for each anchor sample:
- , ,
3.5 Grounding UL to MSA and ERC
Overall loss function:
- : generative task loss, are weight values in [0, 1]
4. Experiments
4.1 Datasets
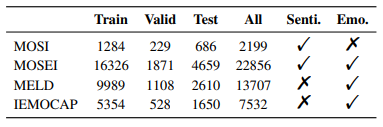
MOSI - Multimodal Opinion-level Sentiment Intensity dataset
- 2199 utterance video segment, each maually annotated with a sentiment score in [-3, 3].
CMU-MOSEI - Multimodal Opinion Sentiment and Emotion Intensity
- Upgraded version of MOSI, annotated with sentiment and emotion of 22,856 movie review clips from youtuve
MELD - Multimodal EmotionLines Dataset
- 13,707 video clips of multi-party conversation in Friends.
- Labeled with 6 emotions (joy, sadness, fear, anger, surprise, disgust)
IEMOCAP - Interactive Emotional dyadic Motion CAPture database
- 7532 samples of emotion (joy, sadness, angry, neutral, excited, frustrated)
4.2 Evaluation Metric
MOSI & MOSEI (sentiment)
- MAE, Corr, ACC-7, ACC-2, F1
MELD & IEMOCAP
- ACC, WF1
4.4 Experimental Settings
- Pretrained T5-Base(220M params) as backbone
- A100 and V100
- Acoustic & Visual hidden dim: 64
- T5 embedding dim: 768
- Fusion dim: 768
- Fusion layer: last 3 of 12 layers in T5
- ,
4.5 Results
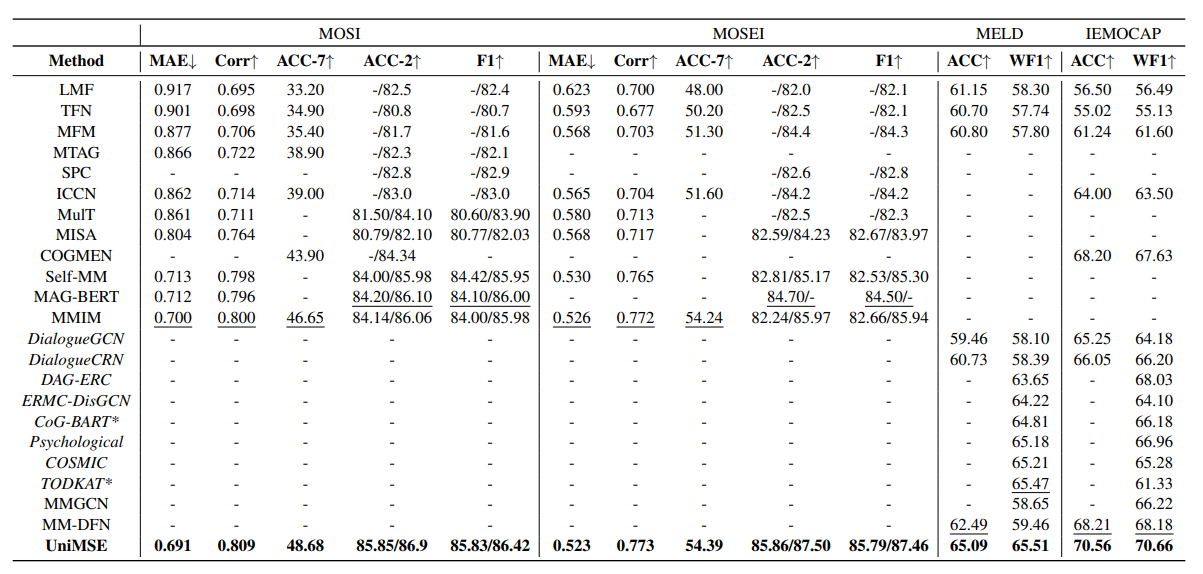
- SOTA results in all MSA and ERC tasks
4.6 Ablation Study
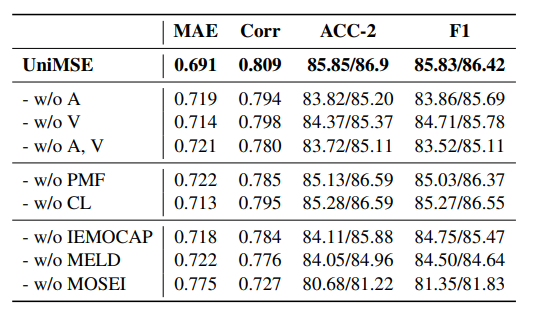
- Ablation study on MOSI dataset.
Removing modalities
- Removing modalities leads to performance degradation
- Acoustic is more important than visual
Removing PMF or CL
- leads to increase in MAE
Removing datasets
- Removed IEMOCAP, MELD, MOSEI and evaluate model performance on MOSI
4.7 Visualization
- Visualize multimodal fusion representation of last Transformer layer to verify effects of UL and cross-task learning
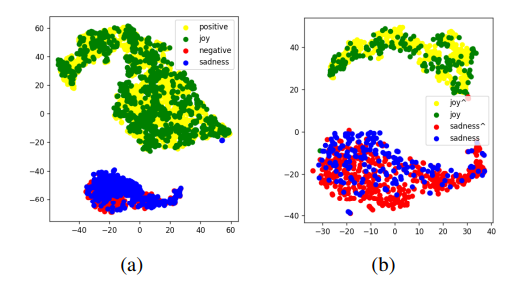
- T-SNE visualization with MOSI and MELD
- Fig(a): positive/negative on MOSI and joy/sadness on MELD
- Fig(b): Pseudo-label of joy/sadness on MOSI and joy/sadness on MELD
5. Conclusion
- UniMSE, unified multimodal knowledge-sharing framework.
- Provides new and different research setting & perspective to the MSA and ERC research communities
Limitation
- Context information only used on MELD and IEMOCAP (??)
- Generation of universal labels only considers textual modality

Undergraduate student at SNU