Vision Transformers Need Registers (ICLR 2024 Oral)
Abstract
- Artifacts in feature maps of ViT(both supervised and self-supervised)
- The artifacts are high-norm tokens in low-informative background images(used for internal computation
- Solution: providing additional tokens(registers) to ViT input sequence
- The solution fixes the problem completly and sets a new SOTA for self-supervised visual models on dense prediction tasks.
1. Introduction
Search of Generic feature embeddings
- Handcrafted before deep learning [SIFT(Lowe, 2004)]
- Recently Supervised and Self-supervised(with Transformers)
DINO (Caron et al., 2021)
- Model that contain explicit information about semantic layout of an image.
- Last attention layer naturally focuses on semantically consistent pars of images.
- Object discovery algorithms like LOST(Simeoni et al., 2021) build on top of DINO
- Can detect objects without supervision by gathering information in attention maps
DINOv2 (Oquab et al., 2023)
- Follow-up to DINO
- Provides features for dense prediction tasks
- Sucessful monocular depth estimation and semantic segmentation
- Incompatible with LOST -> DINOv2 behaves differently than DINO
Artifacts in ViT
- DINOv2 has artifact that were not present in DINO
- Supervised ViT shows similar artifacts
- Suggests that artifacts are baseline behavior of vision transformers, with DINO being an exception
Paper's contribution
Investigation of artifacts
- Artifacts are tokens with 10x higher norm at the output (2% of total sequence)
- They appear around the middle layers of vision transformers
- They only appear after sufficiently long training of sufficiently big transformer
- They appear in patches similar to their neighbors (patches with little additional information)
- They hold less information about original position or pixels -> suggests that the model discards local information in these patches.
- Learning an image classifier on outlier patches yields significantly stronger accuracy than learning with other patches -> suggests that they contain global information
Interpretation of artifacts
The model learns to recognize patches containing little useful information, and recycle the corresponding tokens to aggregate global image information while discarding spatial information.
Registers
- Transformer models perform computation within a restricted set of tokens
- Append additional tokens(Registers) to the token sequence.
- Outlier tokens disappear from the sequence entirely.
- Performance of the models increase in dense prediction tasks, and the resulting feature maps are significantly smoother -> enables LOST.
2. Problem Formulation
On why and when these artifacts appear.
2.1. Artifacts in the local features of DINOv2
Artifacts are high-norm outlier tokens.
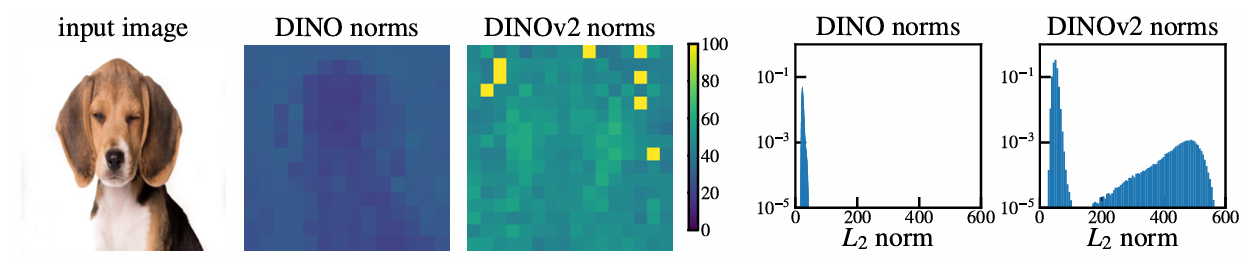
- Bimodal distribution of feature norms in DINOv2
- Tokens with norm higher than 150 will be considered as "high-norm" tokens (for DINOv2 - cutoffs can vary across models)
Outliers appear during the training of large models.

- High-norm patches differentiate themselves from other patches around layer 15 of 40-layer ViT
- Outliers only appear after one third of training
- Only the three larges models exhibit outliers
High-norm tokens appear where patch information if redundant

- Measure the cosine similarity between high-norm tokens and their 4 neighbors right after the patch embedding layer => High-norm patches shows on similar-to-neighbors patches
- Qualitative observations(they often appear in uniform, background areas) matches.
High-norm tokens hold little local information
- Train a linear model on top of the patch embeddings, and measure the performance of the model.
- Position prediction -> although position information was injected in the tokens before the first ViT layer in the form of absolute positional embeddings, high-norm tokens have much lower accuracy
- Pixel reconstruction -> high-norm tokens shows much lower accuracy.
Artifacts hold global information

- Trained a logistic regression classifier to predict the image from single patch
- High-norm tokens have a much higher accuracy than the other tokens => suggests that outlier tokens contain more global information than other patch tokens
2.2. Hypothesis and Remediation
Hypothesis: large, sufficiently trained models learn to recognize redundant tokens, and to use them as places to store, process and retrieve global information.
- While this behavior is not bad in itself, the fact that it happens inside the patch tokens is undesirable (decreased performance on dense prediction tasks)
Simple fix: add new tokens to the sequence
- Model can learn new tokens to use them as registers.
- Register tokens are discarded at the end of ViT.
3. Experiments
3.1. Training Algorithms and Data
- Tested on 3 different state-of-the-art training methods for supervised, text-supervised, and unsupervised learning.
DEIT-III (Touvron et al., 2022)
- Simple and robust training recipe for classification with ViTs on ImageNet-1k and ImageNet-22k
OpenCLIP (Ilharco et al., 2021)
- Strong training method for producing text-image aligned models, following the original CLIP work.
DINOv2 (Oquab et al., 2023)
- Self-supervised method for learning visual features
3.2. Evaluation of the Proposed Solution
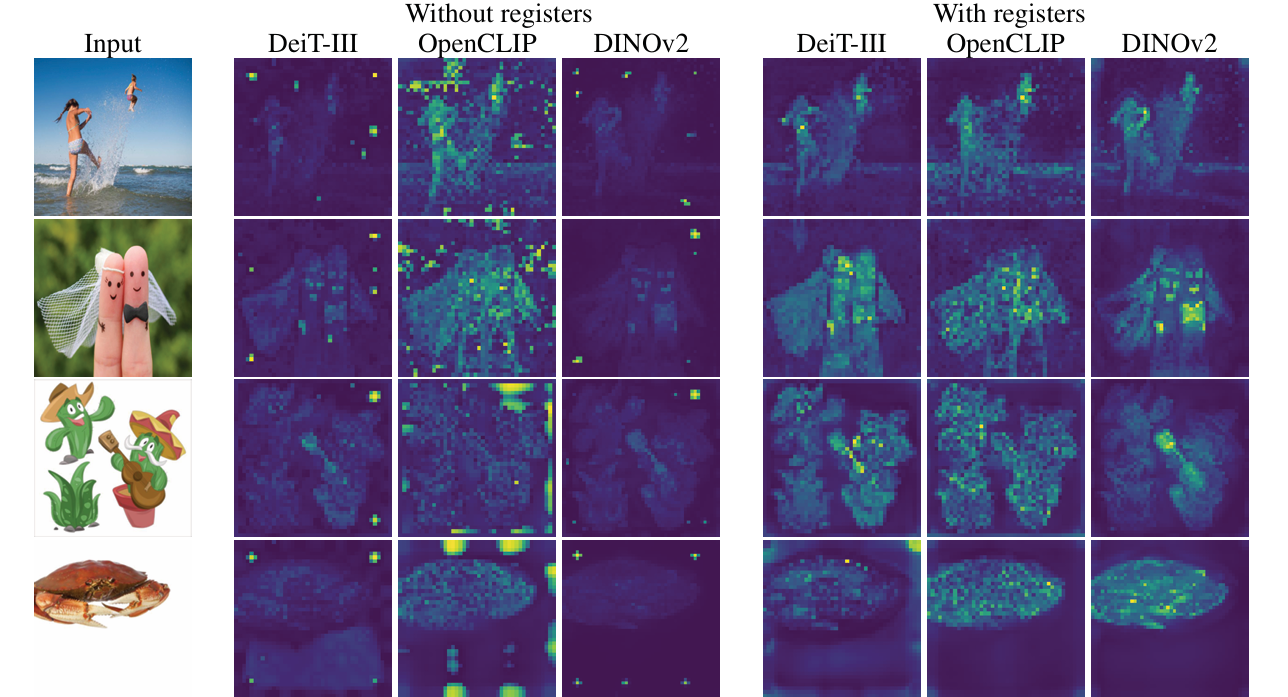
- Models do not exhibit large-norm tokens at the output
Performance regression
- Checking the use of register tokens does not afftect the represantation quality
- Linear probing on ImageNet Classification, ADE20k Segmentation, NYUd monocular depth estimation.

- Models do not lose performance and sometimes work better with register tokens
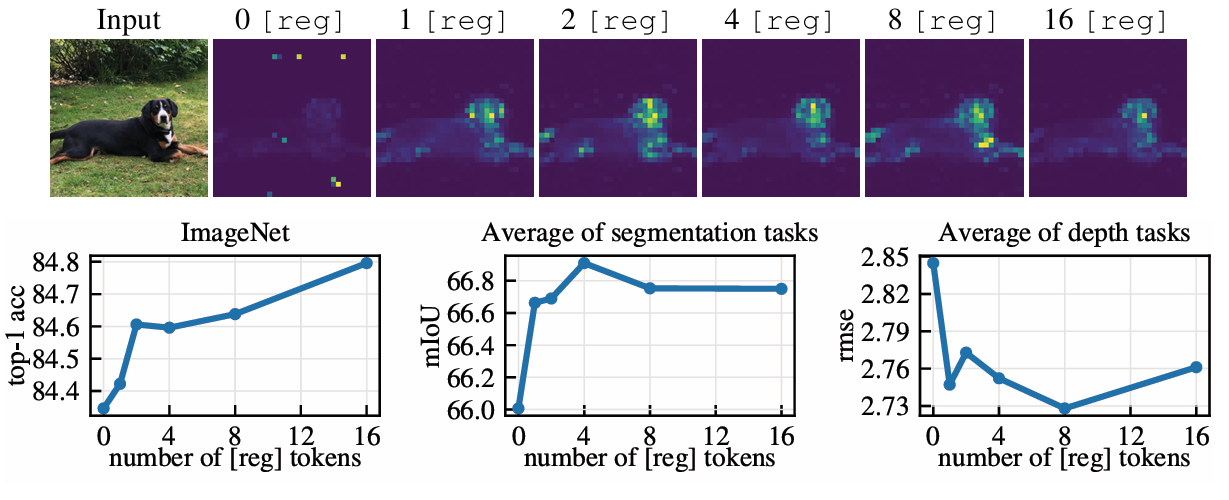
Number of register tokens
- Train DINOv2 ViT-L/14 models with 0, 1, 4, 8, 16 registers
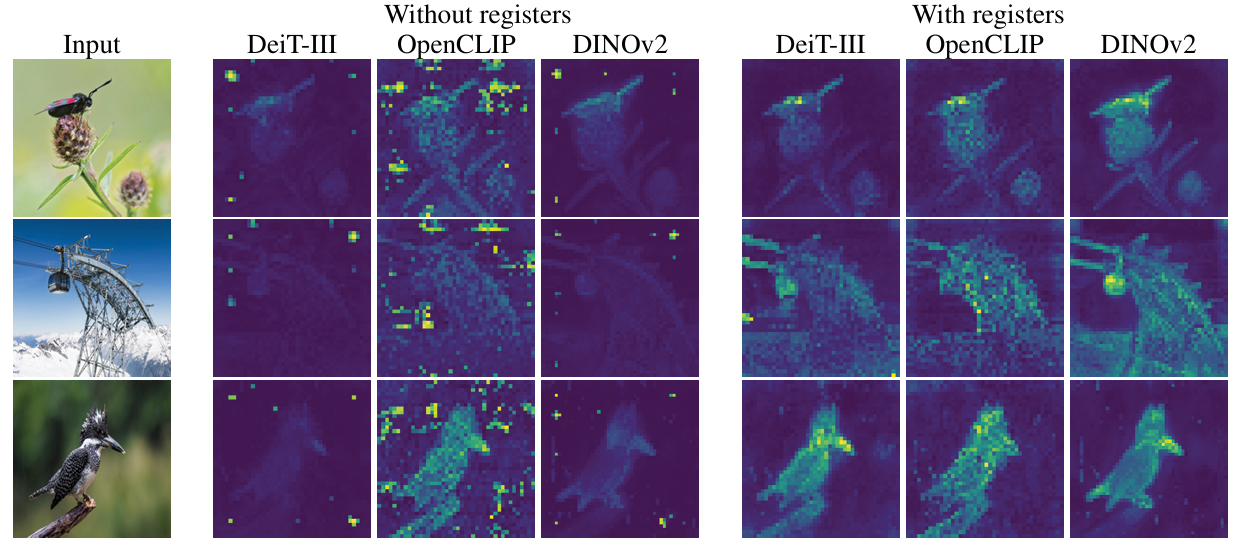
3.3. Object Discovery
- With LOST

3.4. Qualitative Evaluation of Registers
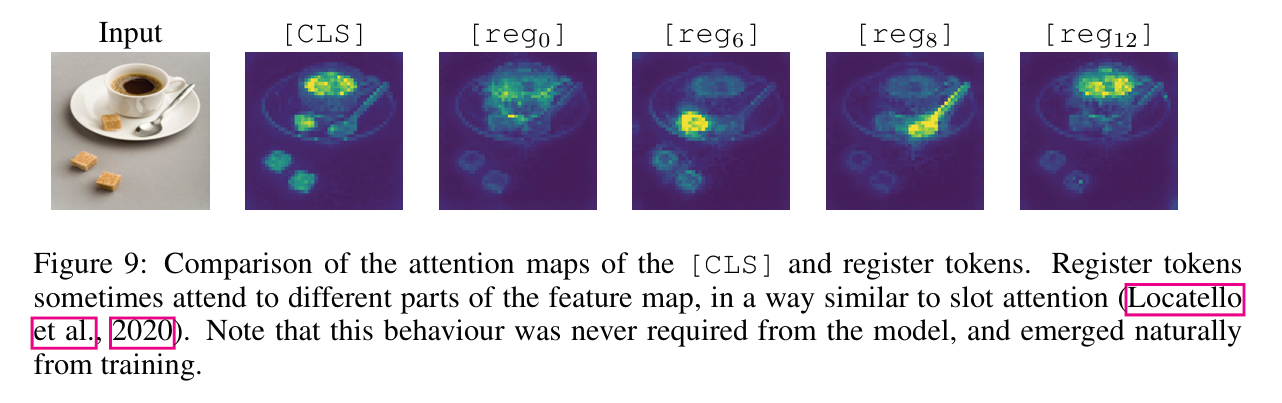
- Registers do not have a completely aligned behavior.
4. Related Works
5. Conclusion
A. Interpolation Artifacts and Outlier Position Distribution
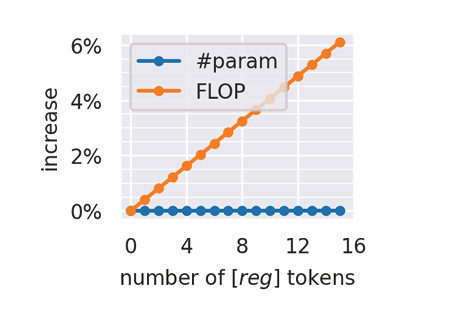
B. Complexity Analysis

Undergraduate student at SNU